
x86 C++逆向分析
C++逆向
关于Typora插入视频的方法:
Typora视频无法正常显示与mp4格式 - elmagnifico’s blog

直接下载一个格式工厂,然后转一下就行
因为MP4里面又有很多编码,可能Typora不支持
输出配置将 视频编码 改为 AVC(H264)即可,这样qq录屏下来的MP4就可以直接插入Typora了
结构体和类
结构体和类 都有构造函数,析构函数,和成员函数,两者的区别只有一个,结构体的访问控制默认为public,类的默认访问控制是private。
值得注意的是,在c++中所谓的private,public,protected都是c++编译器在编译的时候检查的,在实际编译的时候并没有多加什么,也就是说,加这些修饰是给编译器看的,看能否通过。编译成功后,程序在执行过程中不会对访问控制方面又再多检查和限制
结构体大小:
首先要解决的是对齐问题:
结构体对齐值编译器可以设置:
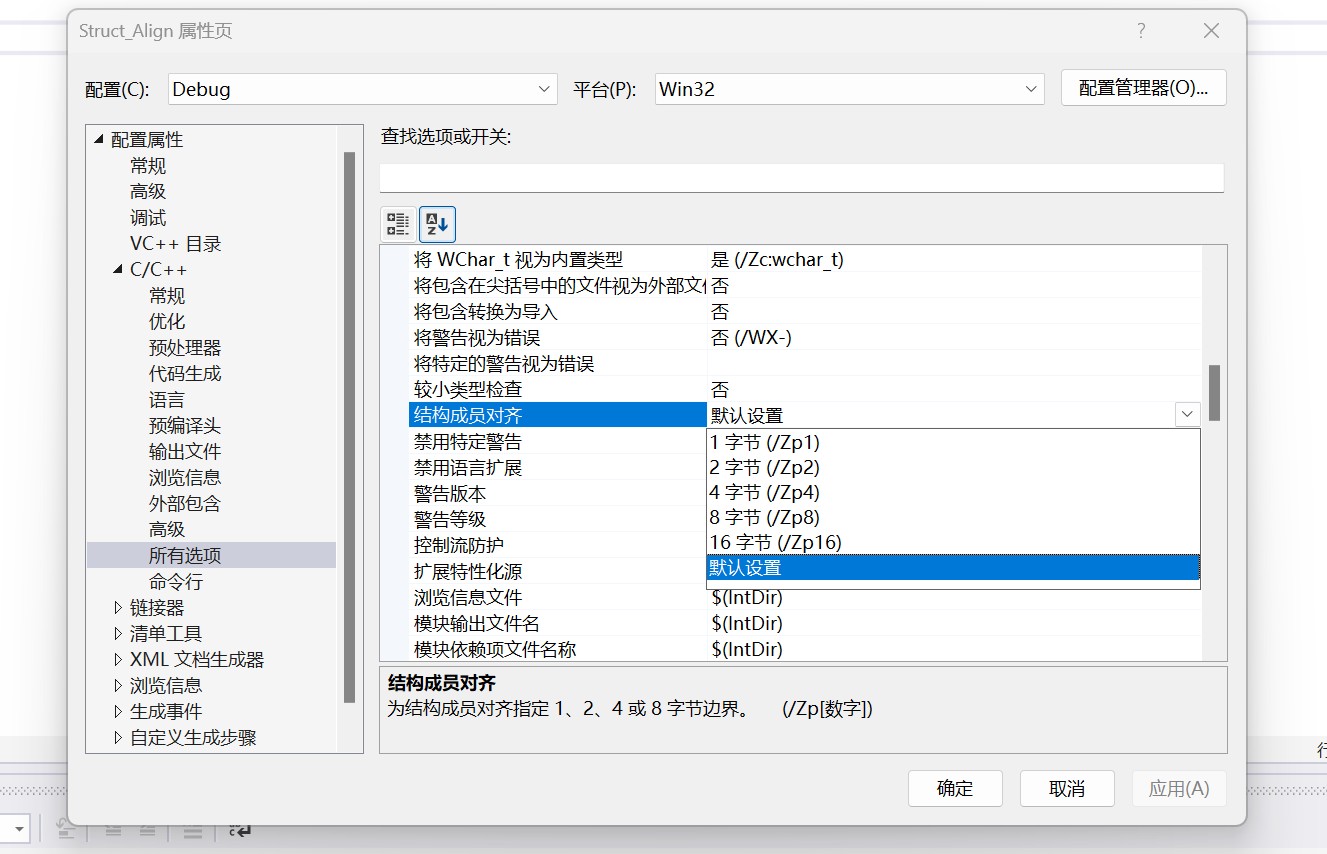
当然也可以手动设置
1 |
|
计算结构体成员对齐 要满足:
1 | struct member % min(结构体成员类型大小,设置的align) == 0 |
计算结构体总大小要满足:
1 | struct size % min(其中结构体成员的最大类型大小,设置的align) ==0 |
我们举个例子:
1 |
|
这个结构体多大呢?
首先
1 | 0x0 char x; |
所以按照这样,把所有结构体成员加起来,大小应该是0x4+0x4+0x4+0x8=0x14
最后一步:结构体的总大小:
因为要满足 struct size % min(其中结构体成员的最大类型大小,设置的align) ==0
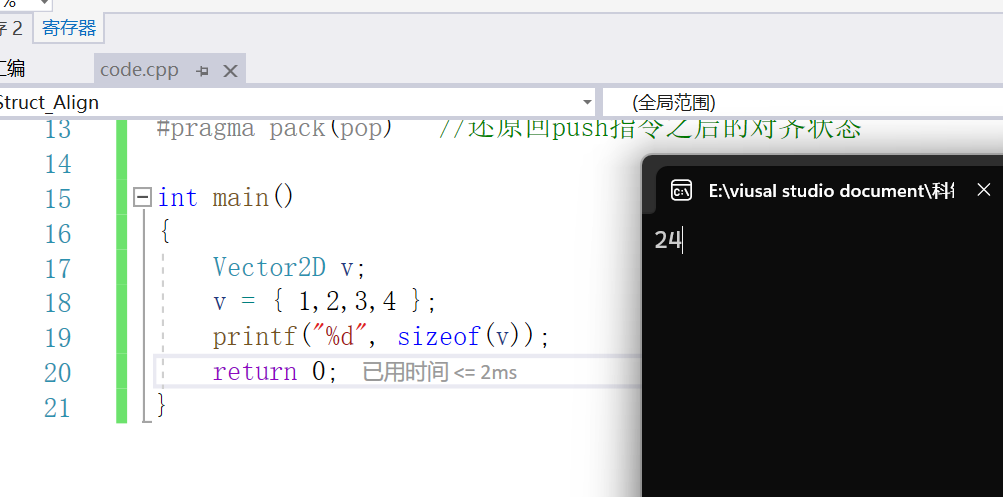
所以为了整除 min(8,8),所以结构体总大小应该是0x18
我们放到编译器看看:
发现大小确实是0x18 (即24)
然后这是内存:
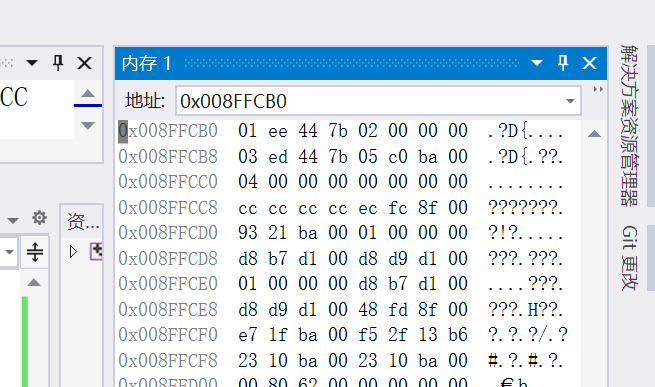
也和我们推测的一致
在IDA的操作

例如这样不太好看出具体赋值类型,可以按下k键,就可以转为有类型的,更符合我们写汇编的语法

如何区分数组和结构体?
首先是初始化:
1 | int main( |
1.结构体成员类型可以不一致

2.数组用的是数组寻址公式,但是结构体不是
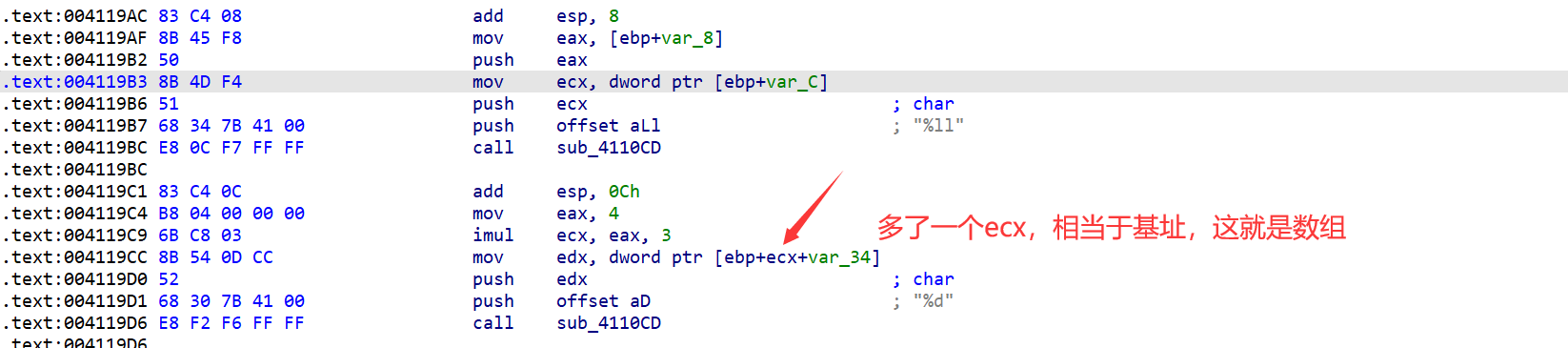
用头文件导入结构体:
之前我们学的都是自己 构造结构体,但是耗时,又麻烦,因此我们可以自己做
例如这个结构体:
1 |
|
先放入一个头文件中
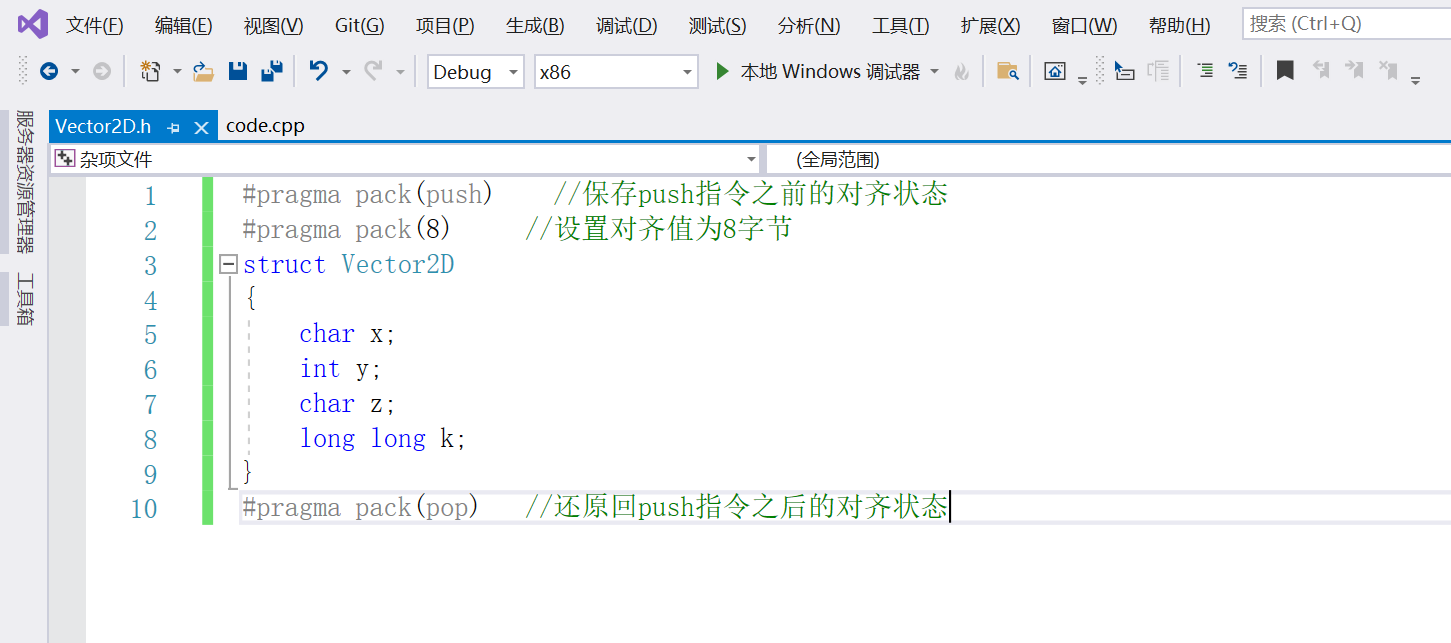
然后在IDA的左上角,可以载入C语言的头文件
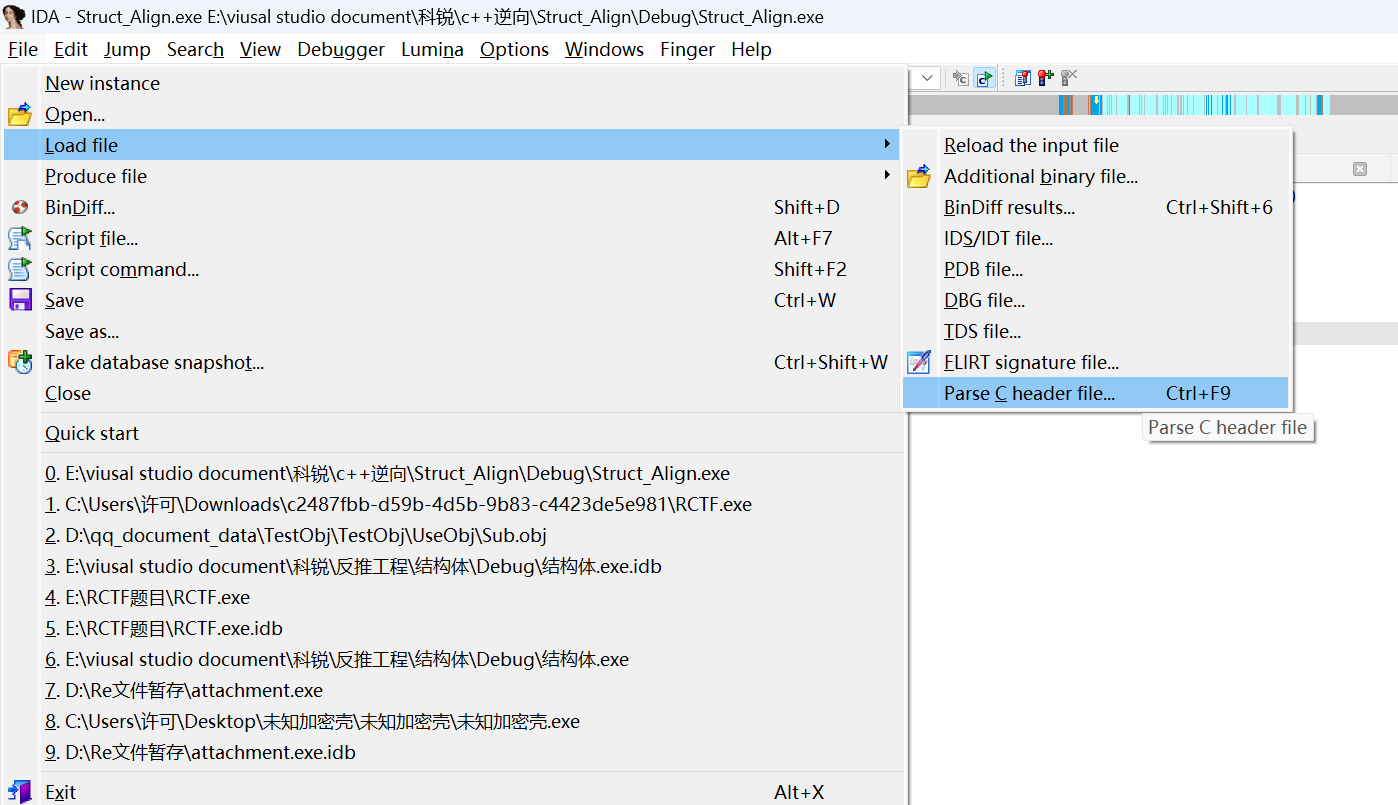
选择我们刚刚那个文件后,这就是加载成功了!
如何添加我们加载进来的头文件结构体呢?
先Shift+F9,进入我们的结构体界面:
鼠标箭头设置在最末尾,然后按下 Insert 键 (在我的电脑上是和‘0’在一起)
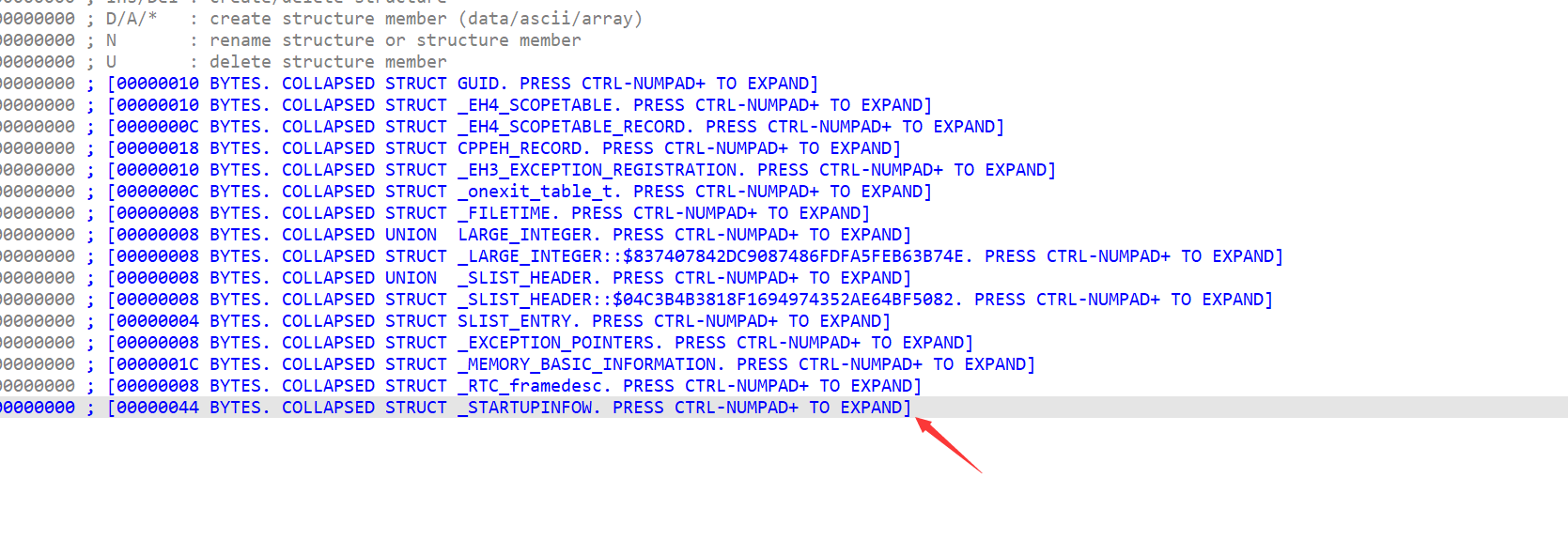
然后弹出来的框填好
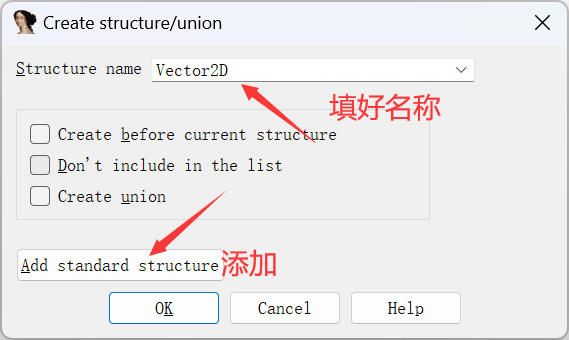
然后选中我们导入的结构体
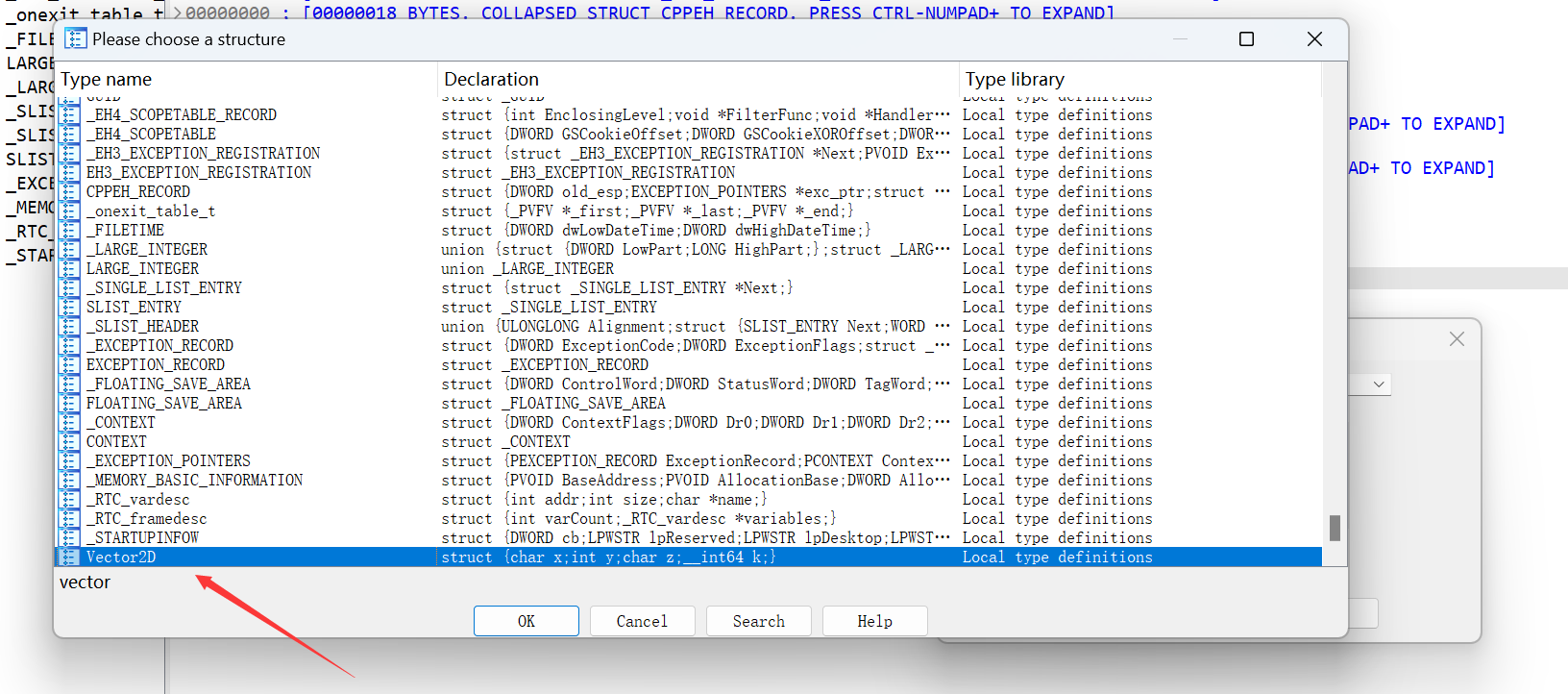
双击加载
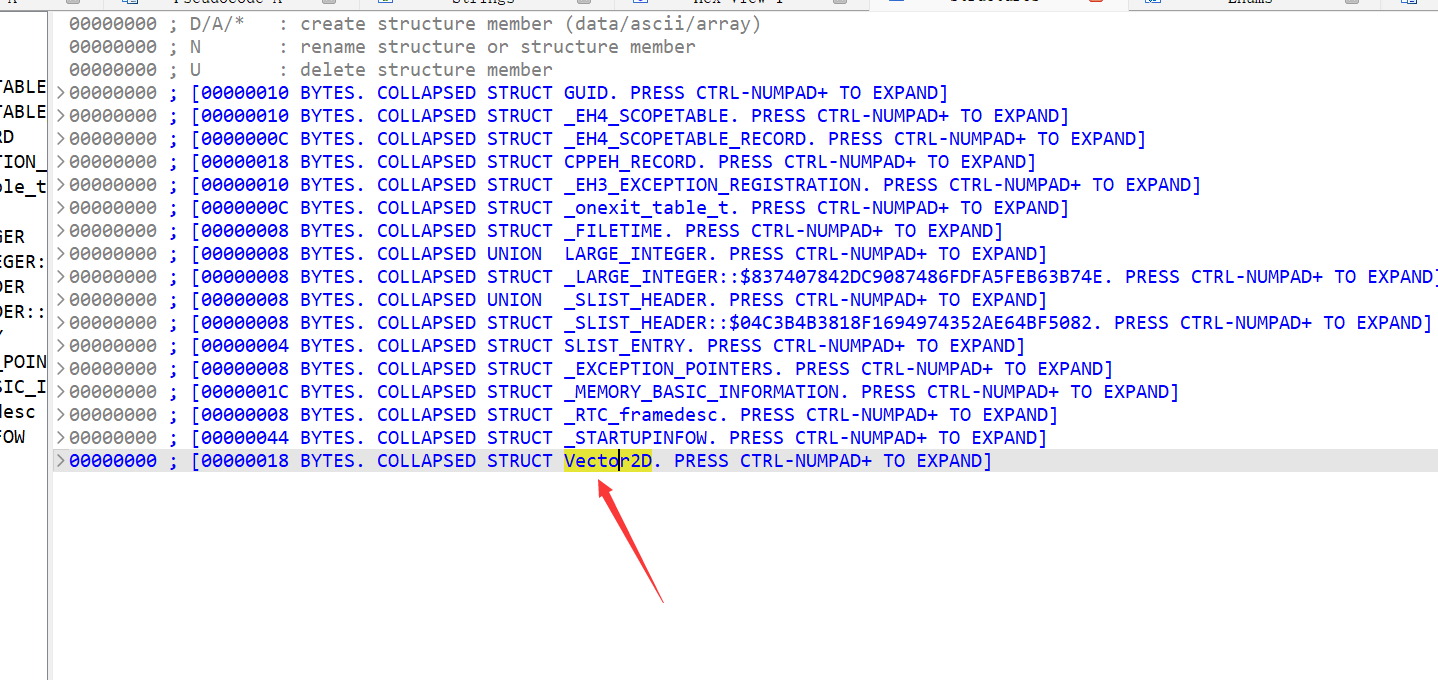
发现已经添加啦,然后可以按 ctrl 和 ‘+’ ,这样可以展开结构体
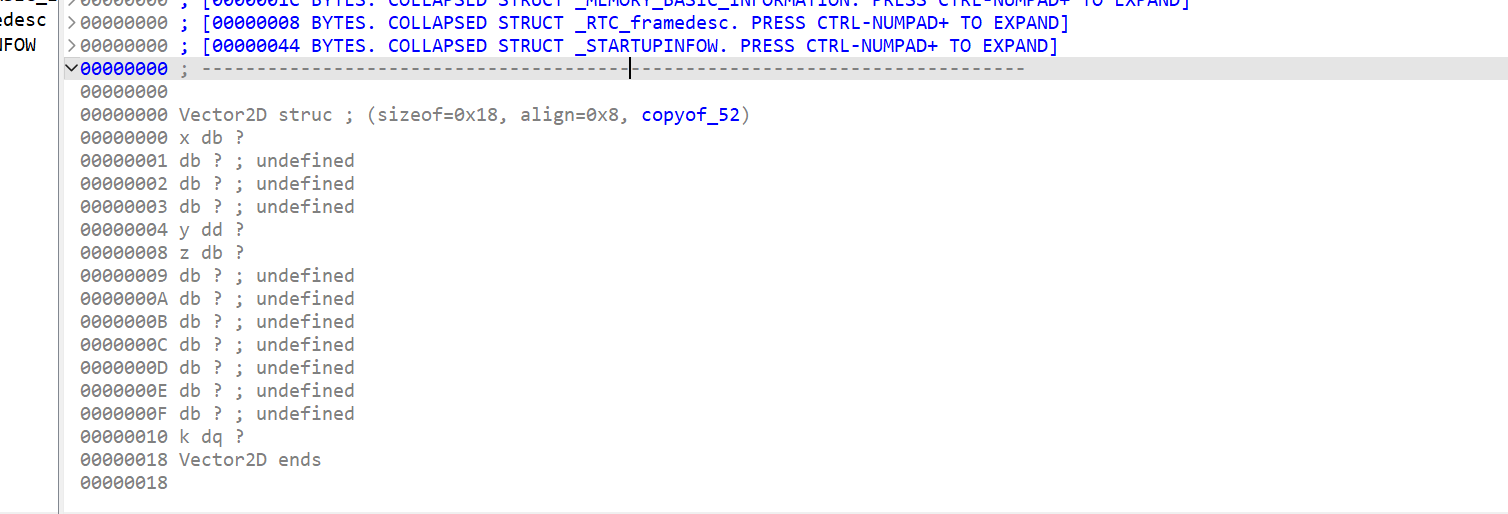
如何应用结构体?
首先找到结构体的首地址
双击进去查看,这里是var_1C,注意要按下k键转为 var
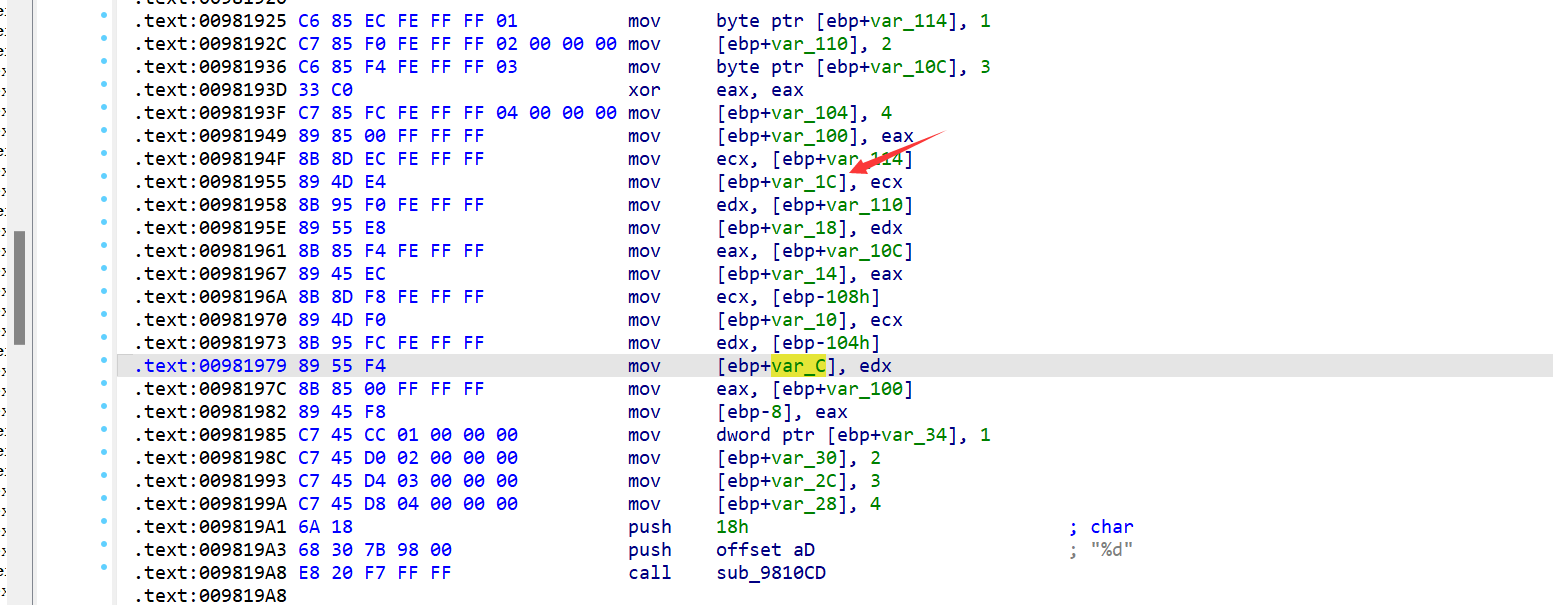
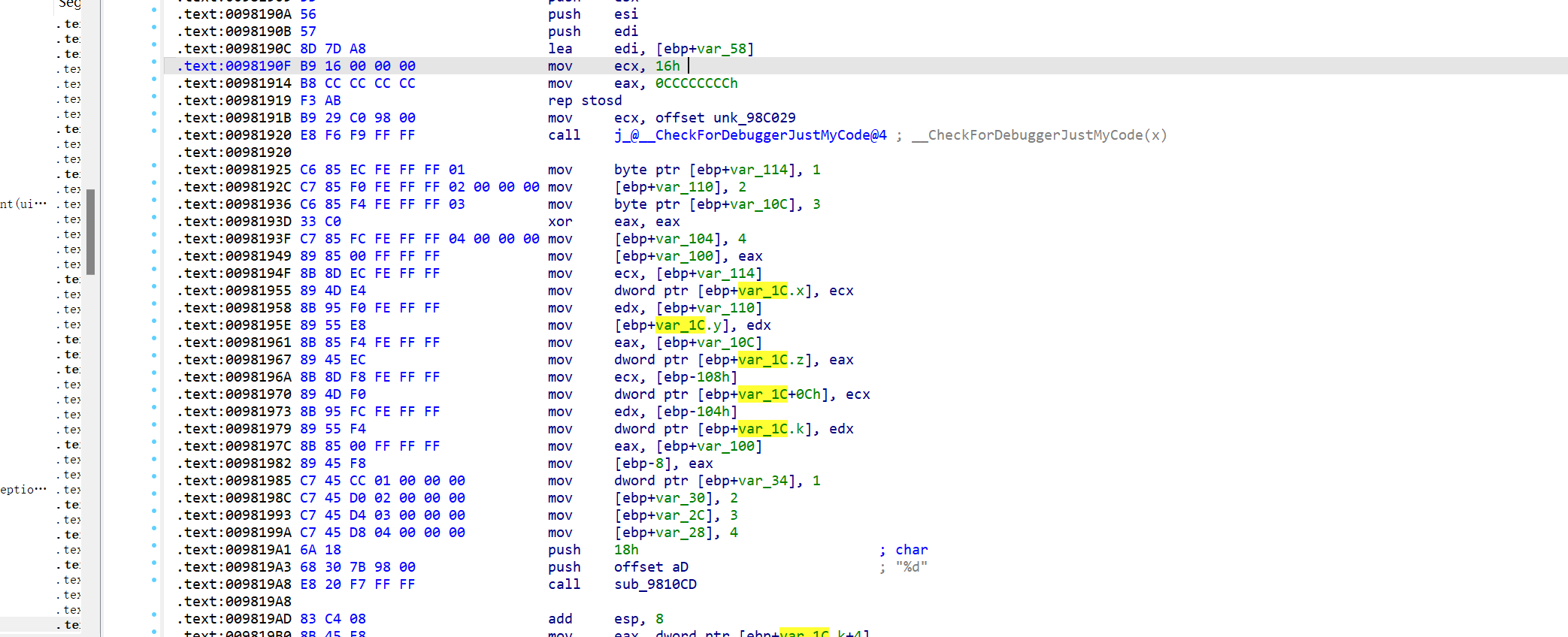
然后应用结构体
效果如下,非常好用
结构体作为返回值
1 | struct Vector2D |
当结构体里面成员很多的时候,就不会用寄存器来返回了,那编译器是如何做的呢?
我们可以看到
1 | .text:00401201 83 C4 08 add esp, 8 |
在调用 Func 之前,我们注意到多push了一个 ecx,是一个局部变量
然后我们看看它是怎么返回的:
1 | .text:00401136 83 C4 08 add esp, 8 |
发现将结果全部拷贝到了 传进来的 result 这个局部变量,然后返给eax
就好像一个指针,这样能节省很多指令
识别类的构造,析构函数
识别构造函数
识别类的构造函数总结:
1.构造函数是这个对象在作用域内调用的第一个成员函数,根据this指针可以区分每一个对象
2.这个成员函数是通过this call调用的
3.这个函数返回this指针
上述条件缺一不可
编译器何时会为类提供默认构造函数?
1.本类和本类中定义的成员对象或者父类中存在虚函数
这是因为要初始化虚表,且这个工作理应该在构造函数中隐式完成,所以在没有定义构造函数的情况下,编译器会添加默认的构造函数,用于隐式完成虚表的初始化工作
1 |
|
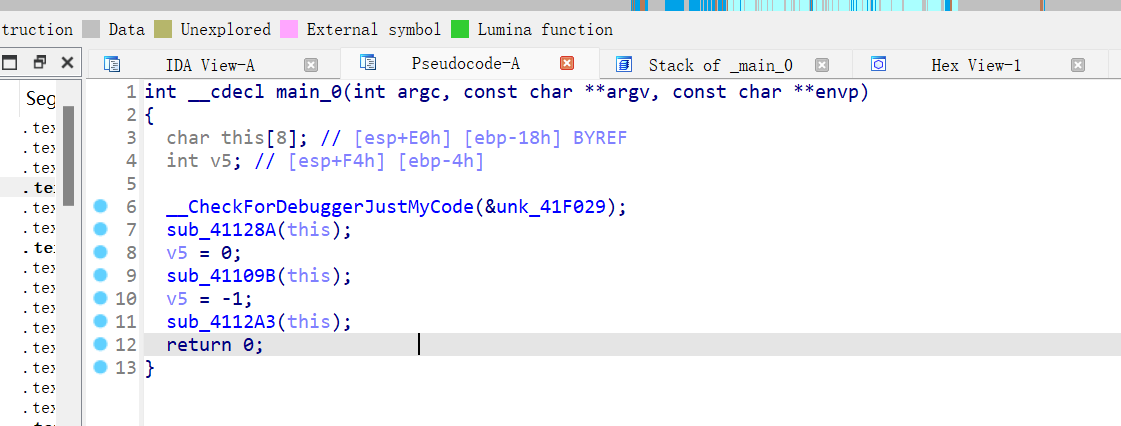
这里可以看到,虽然,没有写构造函数,但是编译器还是为我们生成了一个默认的构造函数
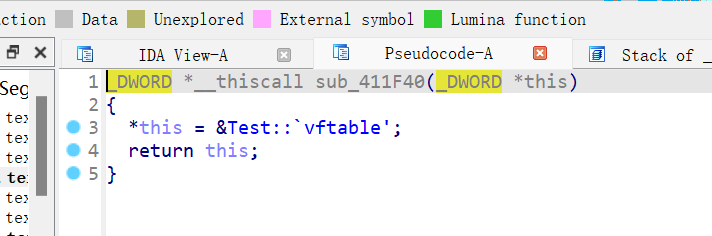
2.父类或本类中定义的成员对象带有构造函数
在对象被定义时,因为对象本身为派生类,所以构造顺序是先构造父类,再构造自身,当父类中带有构造函数的时候,将会调用父类的构造函数,而这个调用过程需要在构造函数内完成,因此编译器添加了默认的构造函数来完成这个调用过程
在没有定义构造函数的情况下,当类没有虚函数,父类和成员对象也没有定义构造函数的时候,提供默认构造函数已经没有任何意义,只会降低执行的效率,因此编译器没有堆这类情况提供默认的构造函数
C语言中malloc函数和c++中的new区别很大,尤其是malloc不负责触发构造函数,它也不是运算符,无法进行运算符重载
析构函数出现的时机
局部对象:作用域结束前调用析构函数
堆对象:释放堆空间前调用析构函数
参数对象:退出函数前,调用参数对象的析构函数

例如这样,传入一个Test2类的参数,执行完这个函数后,会自动调用Test2的析构函数返回对象:如无对象的引用定义,退出函数后,调用返回对象的析构函数,否则与对象引用的作用域一致
也就是说,返回对象是一个类对象,如果后续没有调用这个类,则出去构造这个类的函数以后,就会调用析构函数,否则和该函数一样的作用域
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21class Test
{
public:
Test2 GetTest2()
{
static Test2 t3;
return t3;
}
};
int main()
{
Test t;
Test2=t.GetTest2();
cout<<"6666"<<endl;
return 0;
}在上面代码中,如果对t.GetTest2();返回的变量没有引用的话,在还没调用 cout<<”6666”<<endl;这个语句的时候,就会去调用Test2类的析构函数
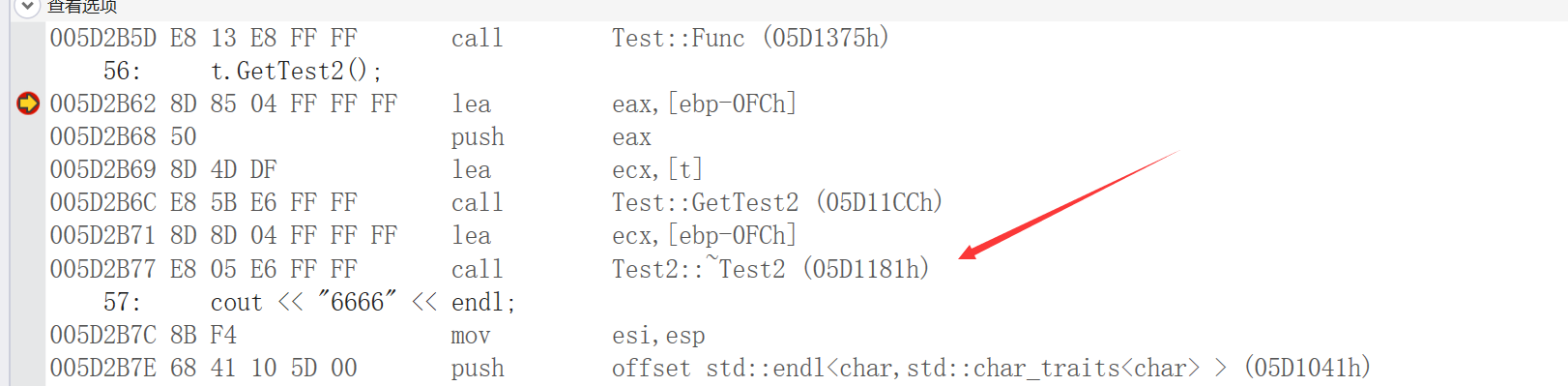
否则的话,就会
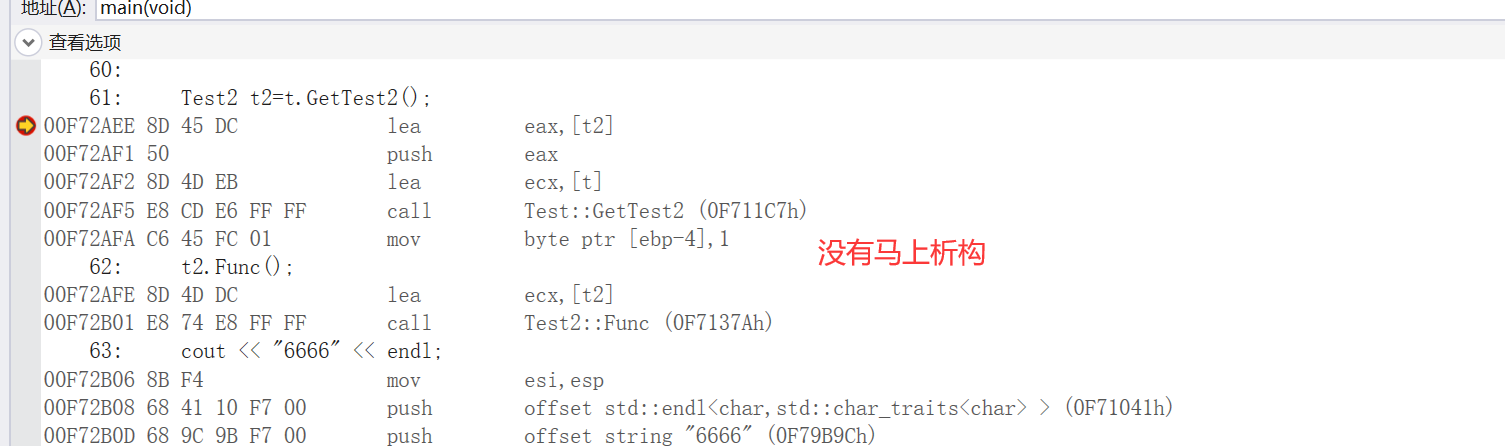
全局对象:main()函数返回后调用析构函数
静态对象:main()函数返回后调用析构函数
虚函数:
(一) 虚函数
- 识别面向对象的依据,因为虚表不可被优化。
- 关键字:virtual
构造函数时不能变成虚函数的,但是析构可以
虚表大概情况
如何查看虚表?
一种方法是用交叉引用,找到一个函数,如果按下X,交叉引用后,发现有在rdata出现,则证明这是一个虚函数,而且追过去可以查看整个类的虚函数数组
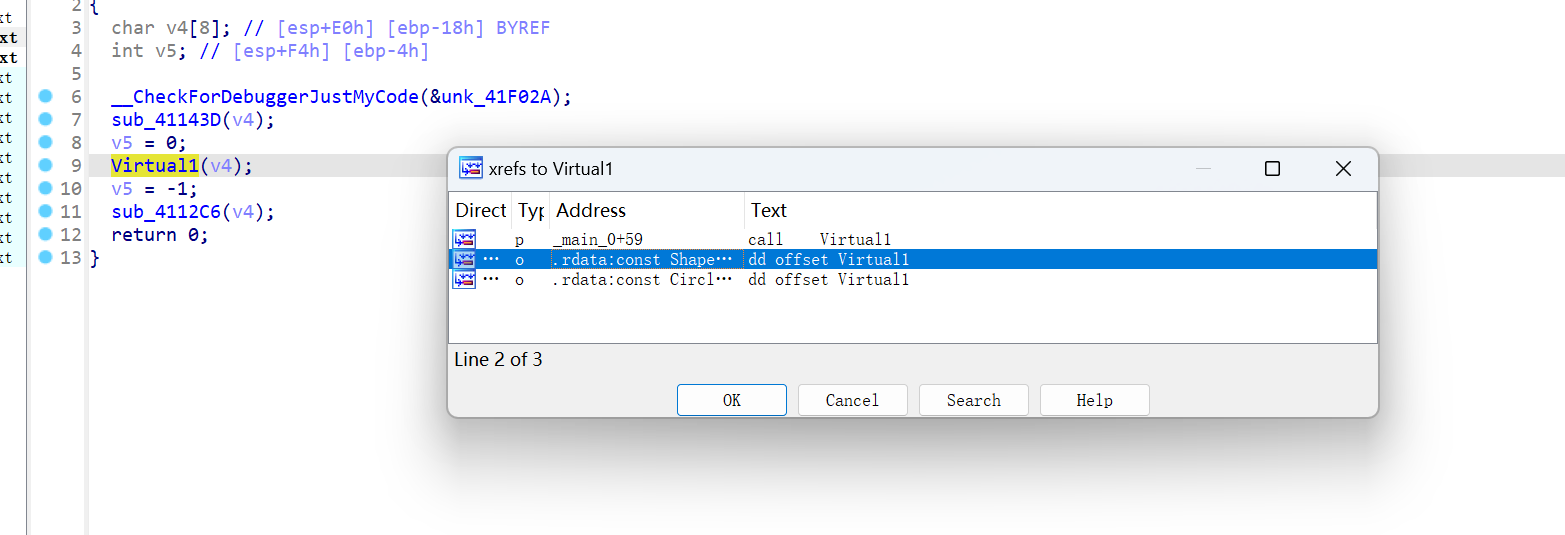
第二种方法是:
找到一个类的构造函数或者析构函数,然后查看它的反汇编: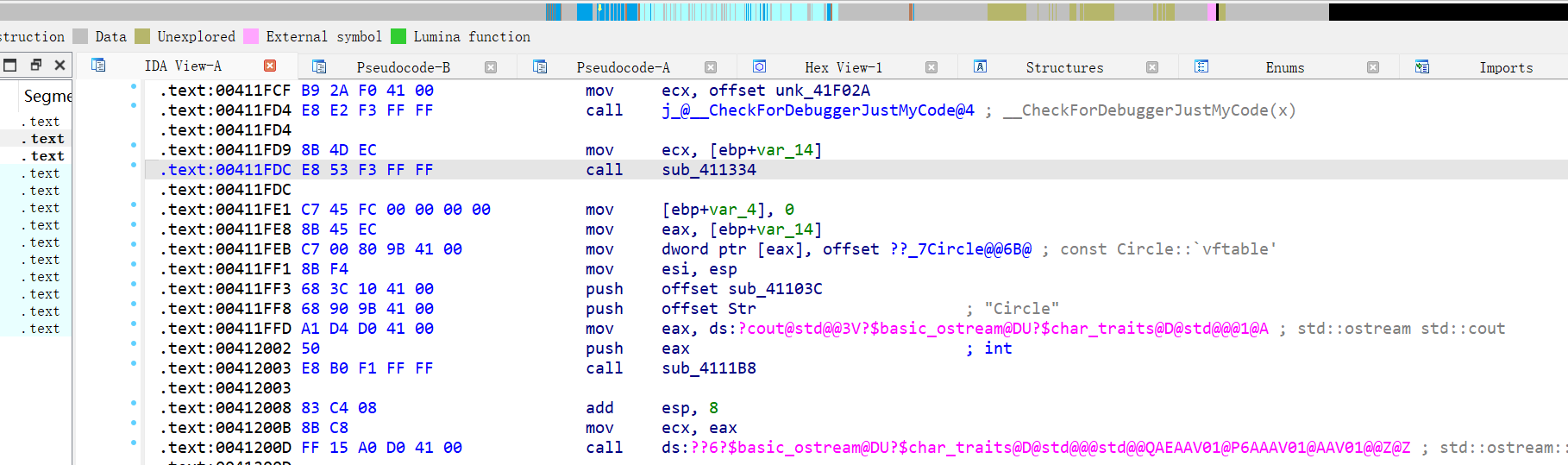
就可以看到虚函数数组的首地址
方法三:
虚表指针存在 this 指针的前四个字节
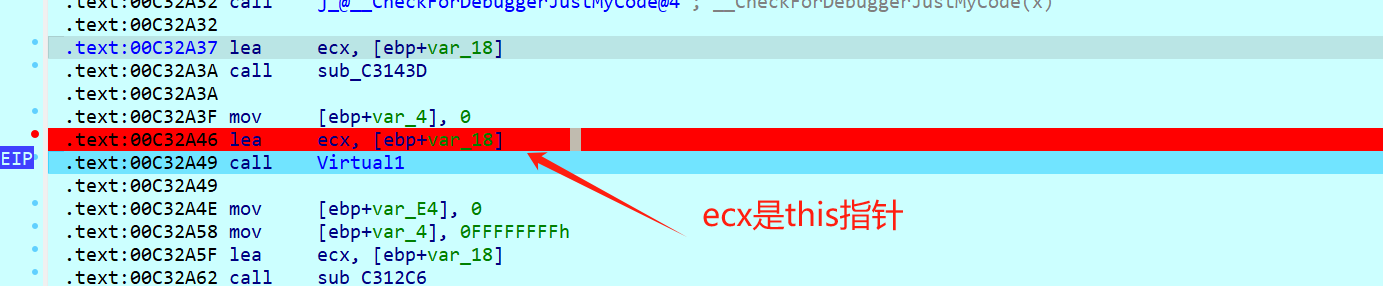
跟踪一下这个 this 指针
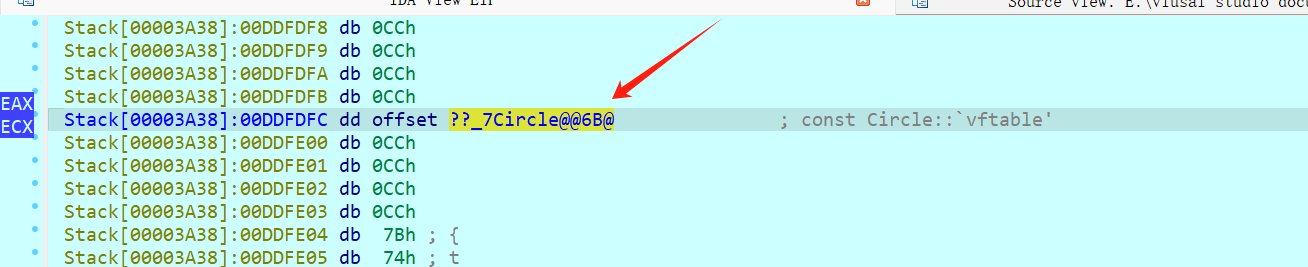
发现this指针的前四个字节就是虚表指针
具体操作是在构造函数:
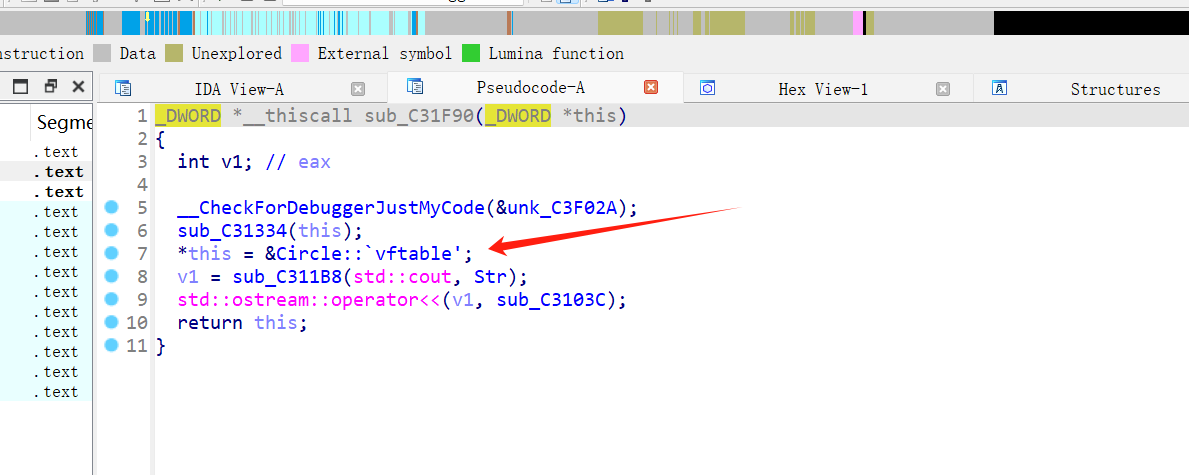
在构造函数中,将虚表指针写在了this指针的前四个字节
有了虚函数,就会比虚函数多四个字节
析构函数会重新对虚表赋值
在析构函数中要还原虚表指针,层层递归,一直到最终父类被析构结束
例如下面这个代码:
1 |
|
Circle类算是孙子类,往上面还有父类,爷爷类,我们用IDA反汇编看看析构是怎么个情况
发现在Circle的析构函数首先将Circle的虚表赋值给了this指针
然后回调用Circle父类的析构函数
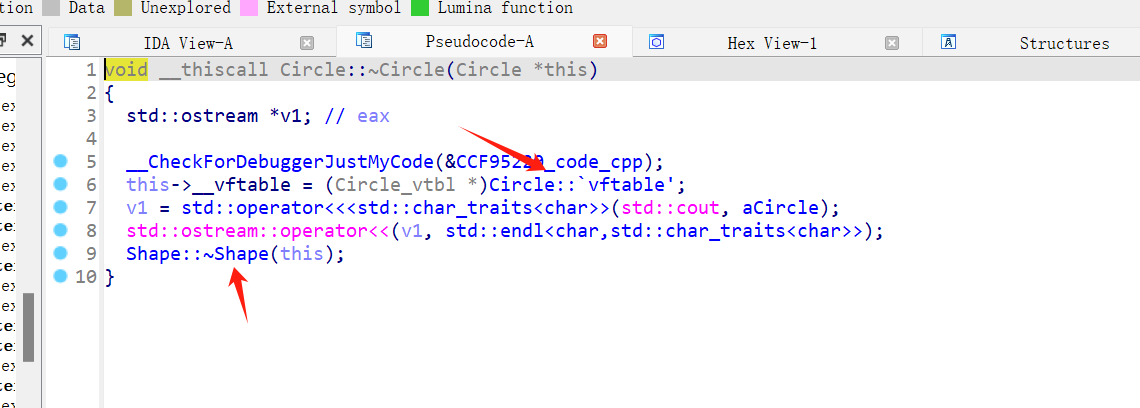
然后我们继续探
同样的,将父类的虚表赋值给this指针,然后调用父类的父类的析构函数
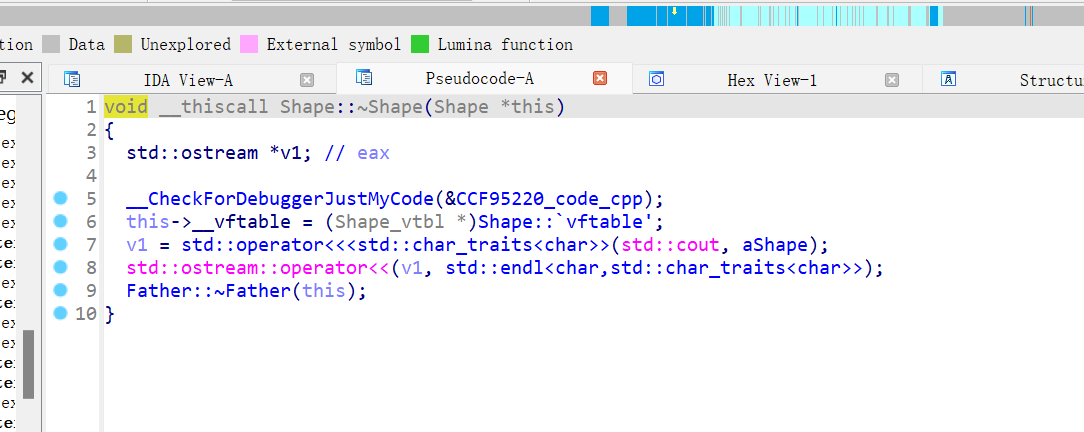
一直递归,直到最终的父类析构结束,一样的,这里也需要将自己的虚表赋值给this指针
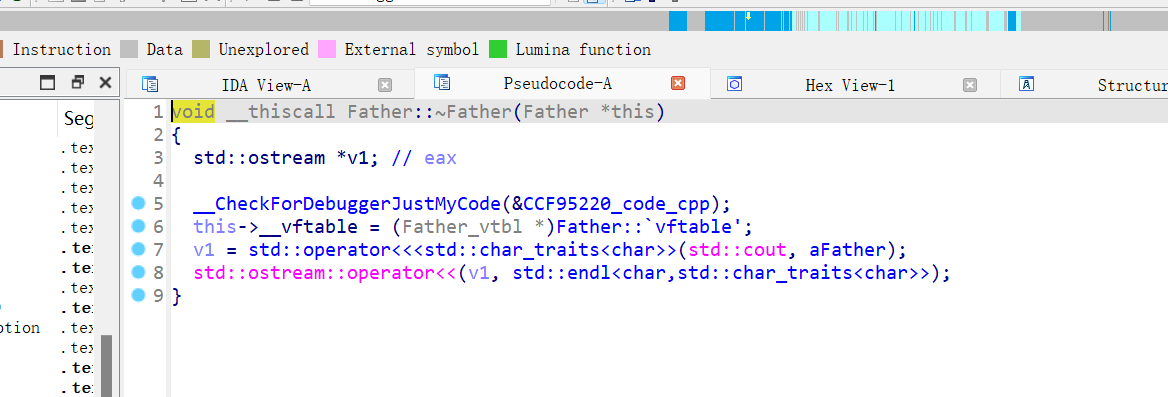
如何快速定位一个类的构造函数和析构函数
由刚刚的特征我们可以知道的是,构造函数和析构函数必然会去操作虚表,所以我们可以查看虚表的引用去找构造和析构,这一招非常好用
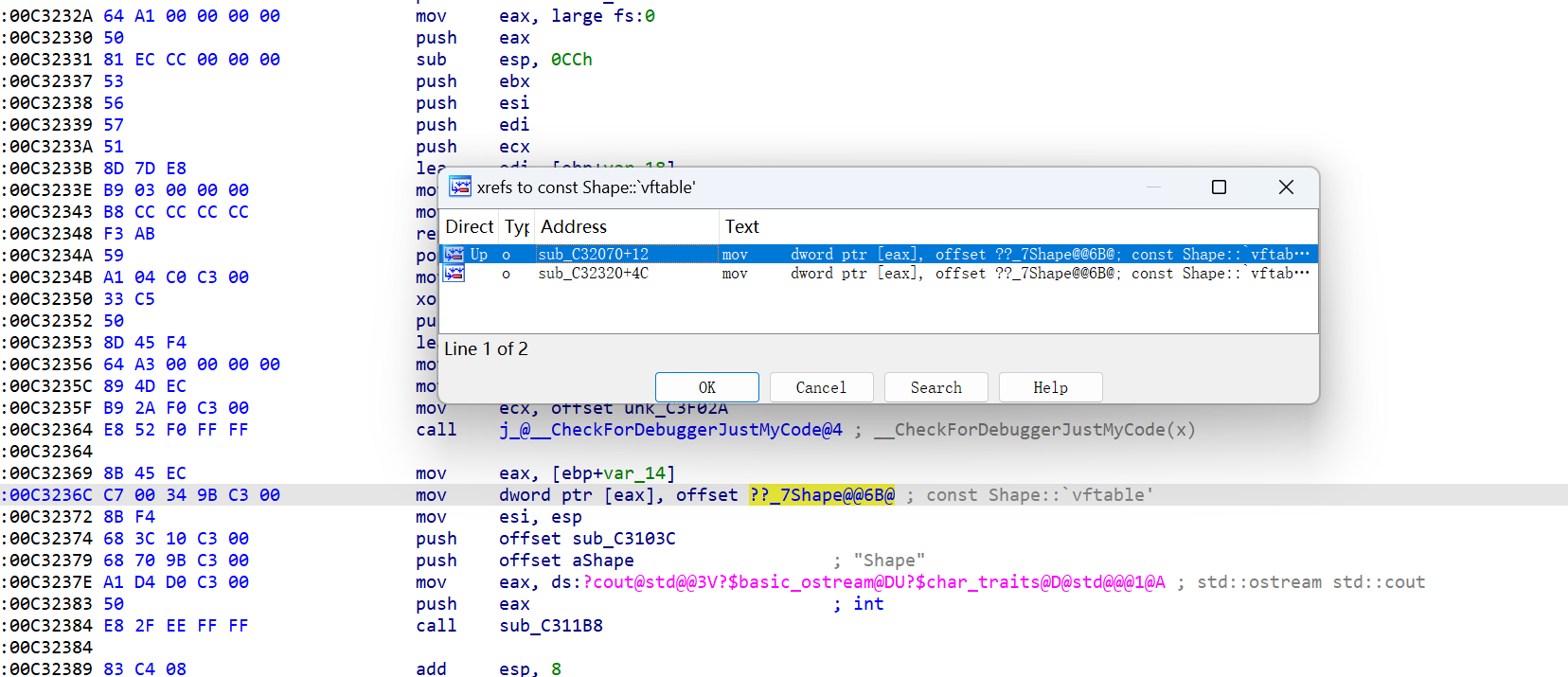
可能不一定有构造函数,但是一定有析构函数
这样不直观的话,可以查看引用图:
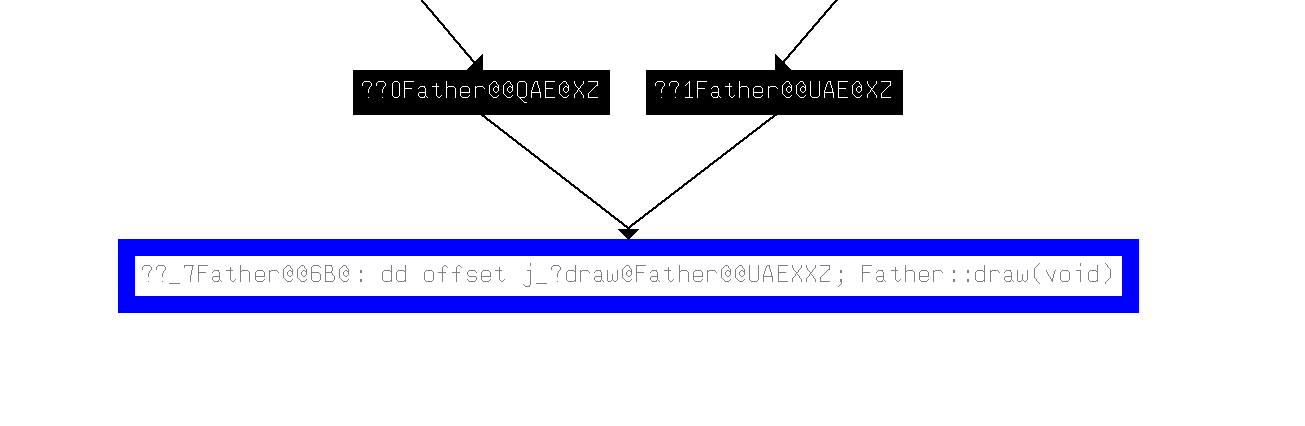
这俩其中一个是构造,一个是析构,地址低的是构造,高的是析构
虚表在编译的时候就已经生成
如果一个类至少有一个虚函数(virtual 修饰),那么就会有虚表。(继承过来的虚函数也算)
虚表在全局数据区 (vs放到 rdata段)
虚表指针在虚表首地址处理。
所有表项都指向成员函数指针,如果虚表数组每一个元素不是指向一个函数指针,那么就不是虚表
虚表不一定以0结尾。
值得注意的是,虚表的结尾不一定是0,具体分析具体判断
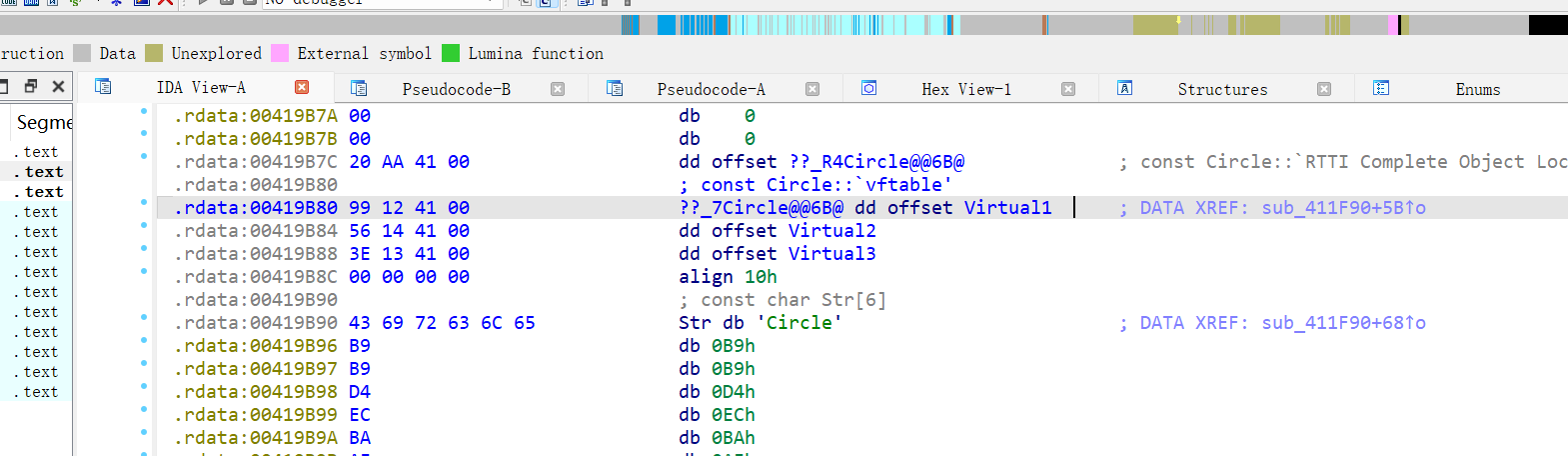
判断:同上上下文特征,判断有几个函数指针。
构造函数填充虚表指针
析构函数回填虚表指针
- 析构函数调用虚函数无多态性
为什么IDA没有PDB也能识别类名?
由于 C++ RTTI 新版本才有
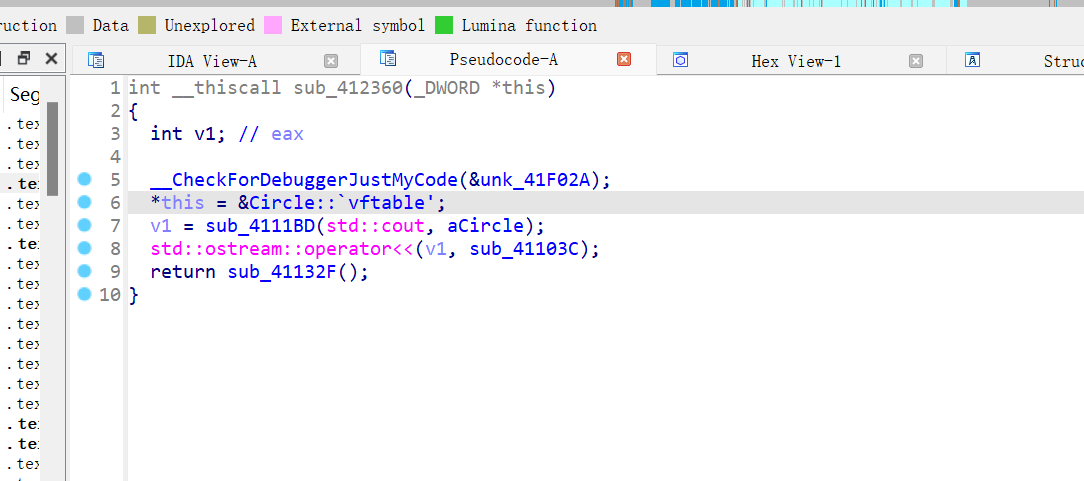
例如这样,明明没有加载PDB,但是还是识别出了虚表类是Circle,这是因为
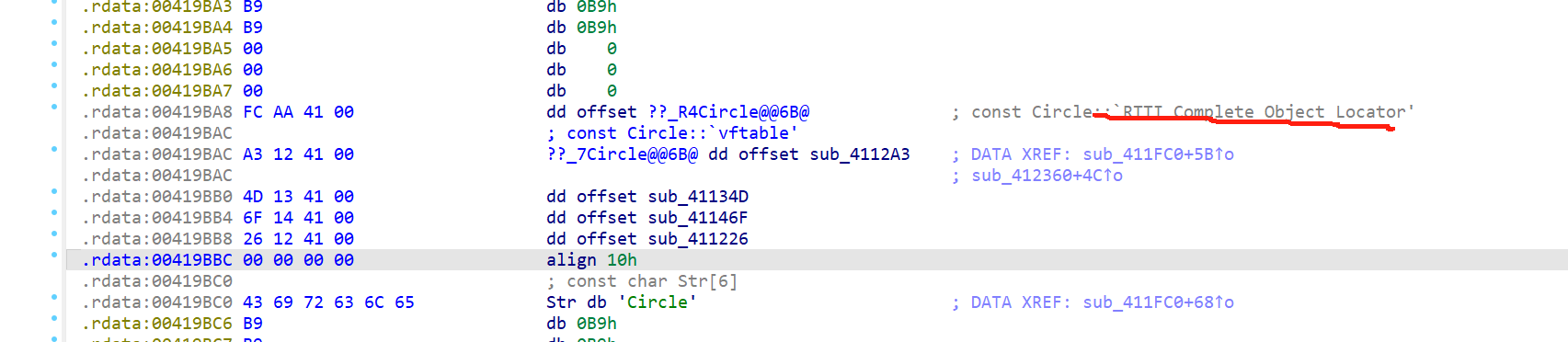
有个叫RTTI的东西
在编译器选项可以关闭:
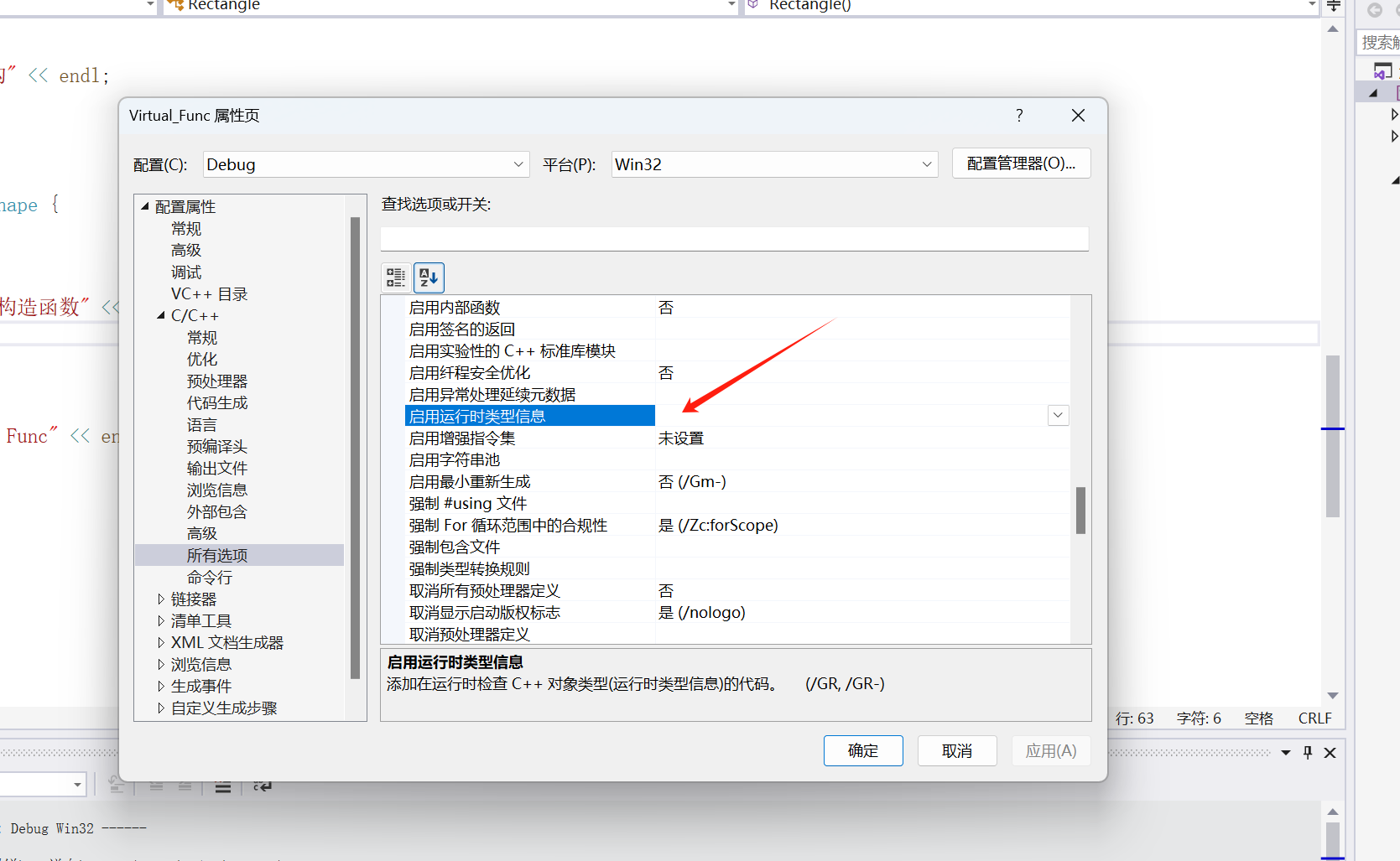
把这个改为 否 即可
这样虚表就没有信息了,增大逆向难度
如果用到Try catch,这会强制开启RTTI,因为Try要去识别类型
虚表的使用
成员函数产生多态
1.是虚函数
2.使用指针或者使用引用
3.调用的时候 Call Vftable[index] (如果是直接调用函数,那么就不是虚函数)
1 |
|
反汇编以后长这样:
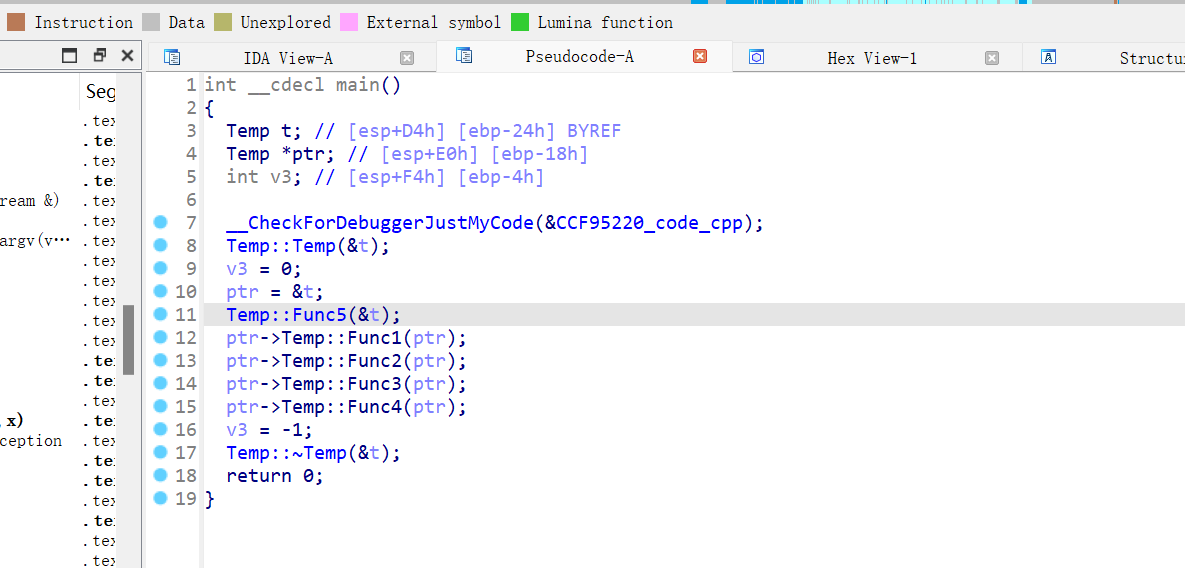
我们看看函数调用情况:
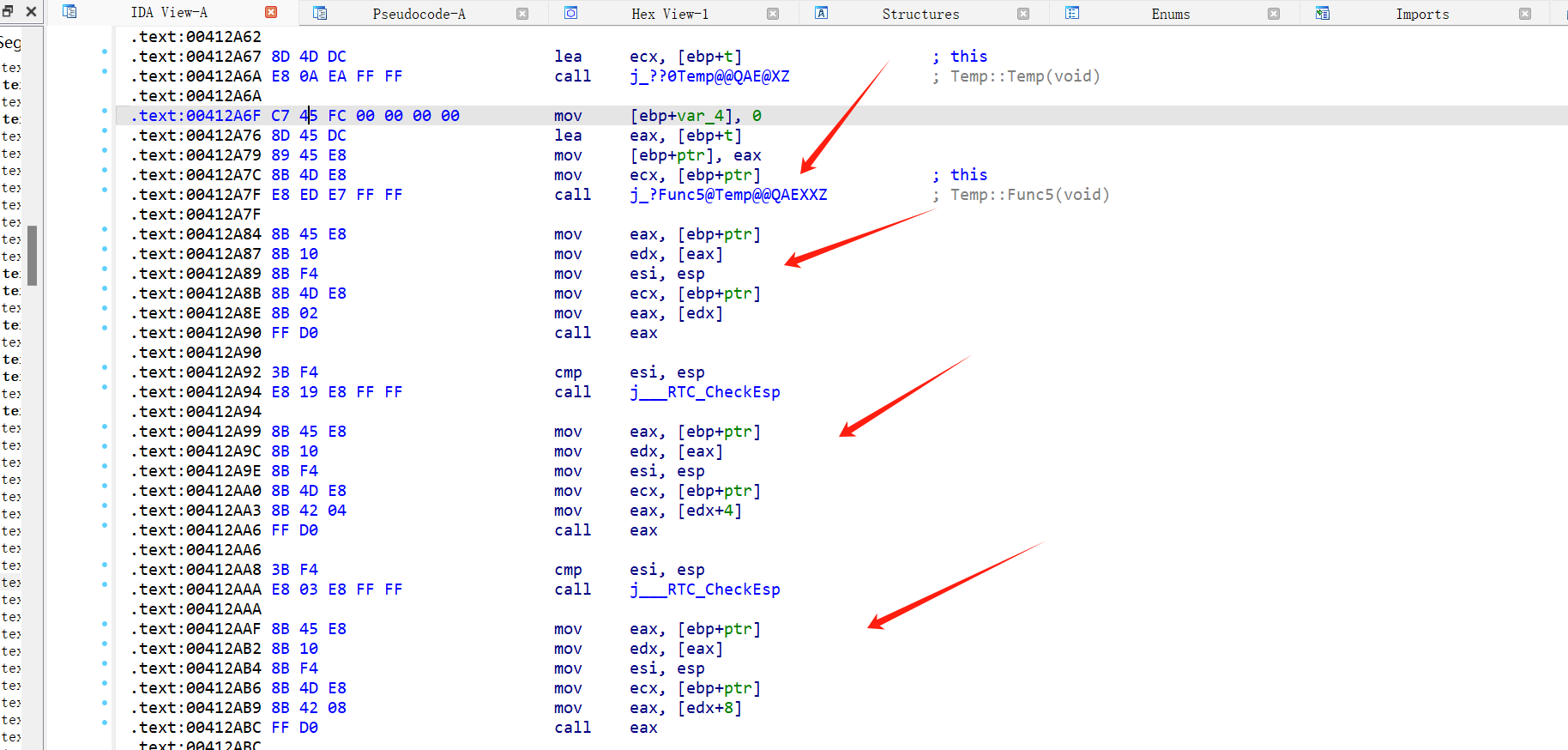
可以看到,如果不是虚函数,那么调用函数直接是call 函数名
但是如果是虚函数的函数,就会用间接调用
1 | ptr->Temp::Func1(ptr); |
我们来仔细分析一下这个 间接 call 是如何用到虚表的
我们发现 call eax 是来自[edx + xx],然后溯源发现edx其实就是 this 指针
然后后面的 + xx 其实就是对应的虚表偏移,这样就能拿到正确的函数
继承
构造函数的顺序:
1.构造基类
2.构造成员对象
3.自己
注意注意,这是一个递归的操作
具体来说,在进行构造基类的构造时,如果基类还有基类,那么又进入基类的基类的构造
直到结束递归
析构的顺序
1.自己
2.构造成员对象
3.构造基类
实践一下:
1 |
|
这样我们发现,最终递归先调用的会是A的构造,然后是B的,最后是C的
析构函数之前说过就不再细说了
如果是虚函数,那么先基类的构造,再填充自己的虚表
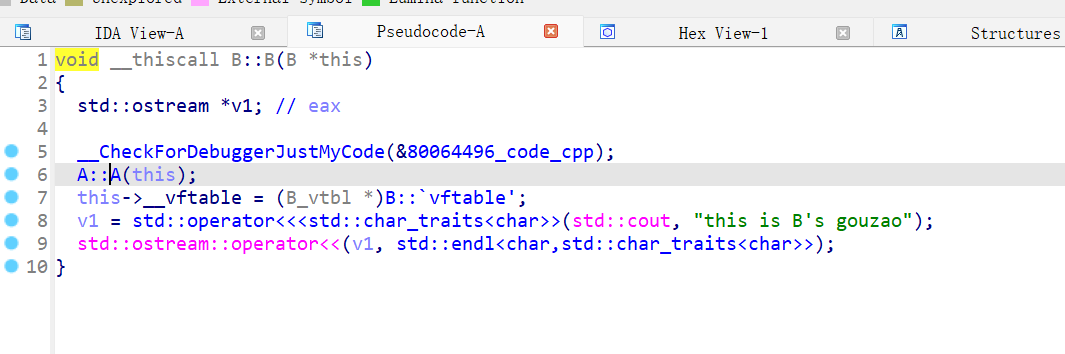
这样,也给我们识别继承提供了依据
实践可以发现,先调用的基类构造,然后再调用成员构造,最后调用自己的构造
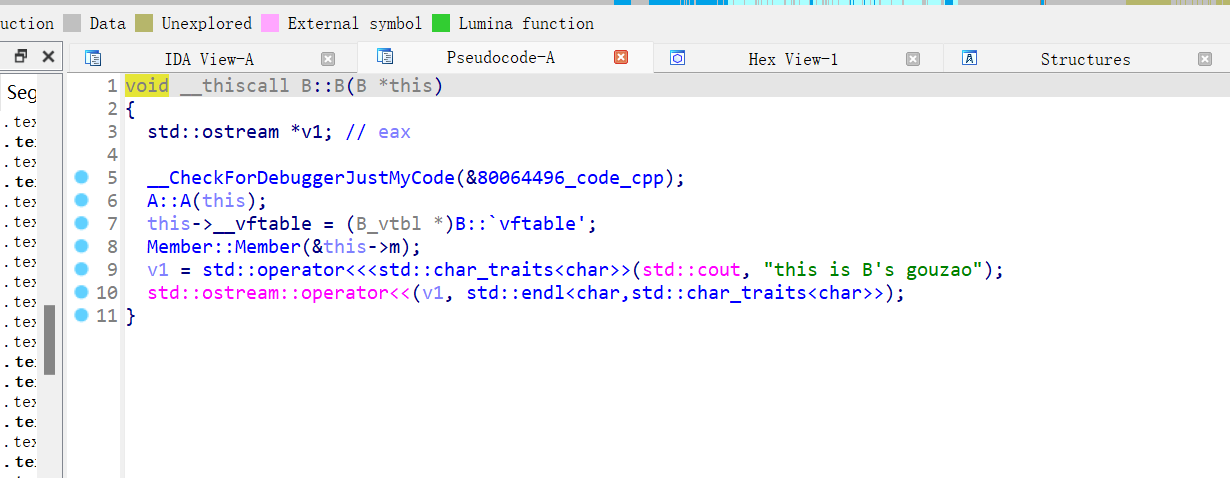
But,老版本的成员构造是在自己的构造之后,新版本才满足 基类构造 -> 成员构造 -> 自己的构造 这个顺序
成员函数和构造函数的区别就是,成员函数不填虚表
派生类的行为:
1.拷贝基类的虚表
2.覆盖(跟基类同名·,同参,同返回值)
3.新增加的虚函数,追加
另外虚函数会进行传递,就是A中的Func函数是虚函数,然后B继承A,C继承B,这个
继承的原理:
父类指针可以指向子类,并调用子类的函数,这是为什么呢?
这就涉及到继承的问题,具体来说是因为 构造函数中,虚表的覆盖
派生类的构造函数之前说过了,
构造函数的顺序:
1.构造基类
2.构造成员对象
3.自己
所以,最终子类的虚表是自己的,及时是父类指针指向子类,也可以去调用子类的虚函数,因为虚表已经被覆盖了
继承的特征:
找到虚表的地方,然后查看交叉引用,如果发现虚函数有交叉引用,就说明存在继承
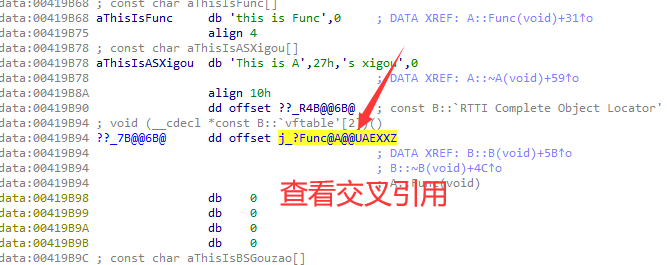
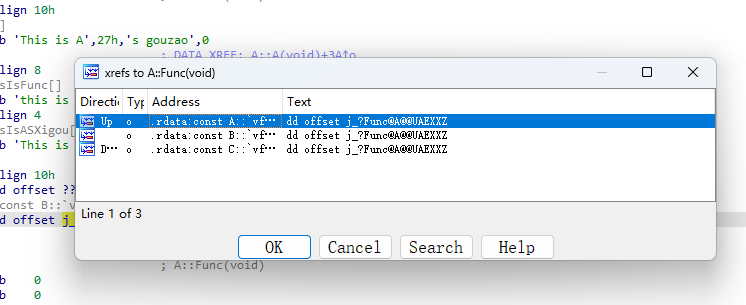
实战:
如果调用了delete,那么就会产生析构代理
可以通过查看对虚表的引用,去迅速找到 构造和析构函数
多重继承
内存结构
A的内存结构
A::vftable
A::member
B的内存结构
B::vftable
B::member
AB的内存结构应该长这样
A::vftable
A::member
B::vftable
B::member
AB::member
但是要覆盖虚表,因此长这样
AB::vftable
A::member
AB::vftable
B::member
AB::member
1 |
|
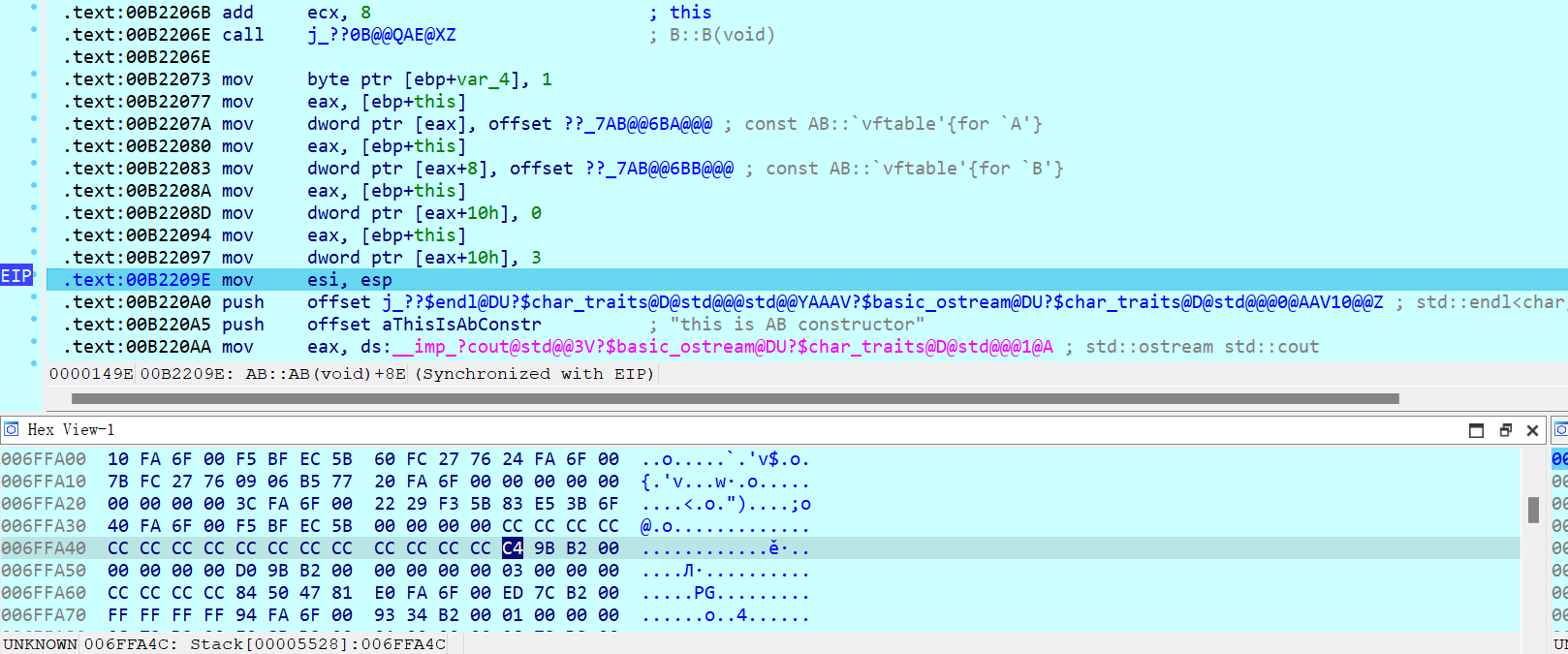
观察内存结构也确实如此
另外如果AB这个类也有一个虚函数,那么覆盖虚表的时候,有必要在A表和B表都塞入AB的虚函数,例如func3吗?
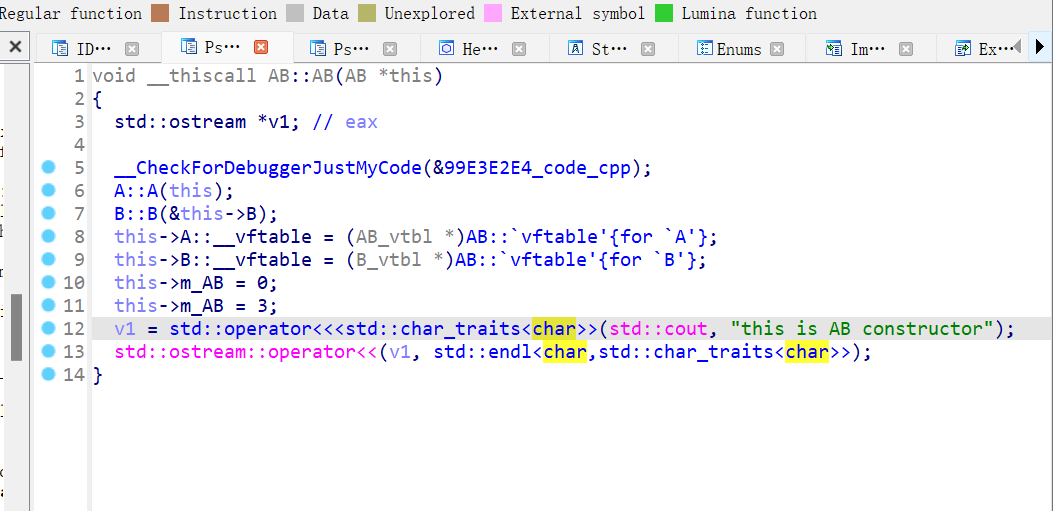
事实上只有在拷贝A的虚表有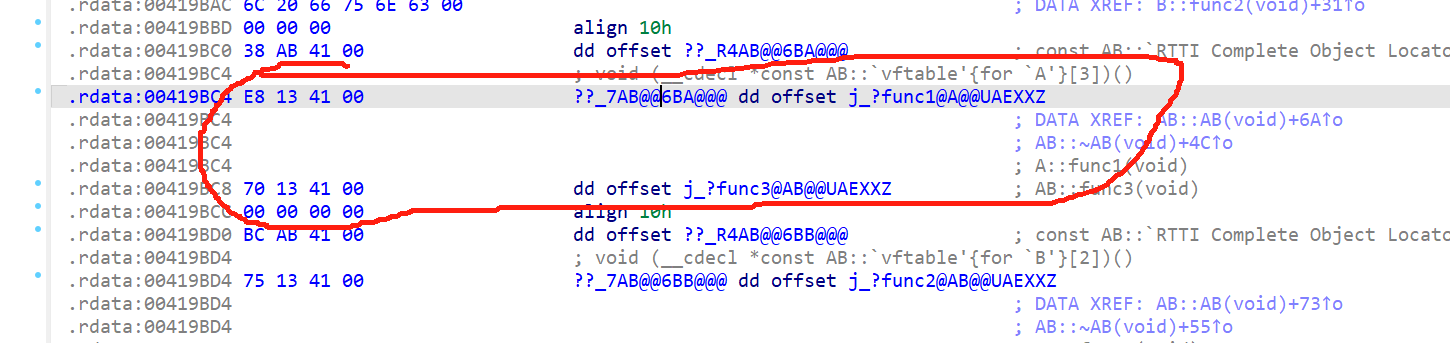
但是B没有,因为没必要拷贝两份
所以自己类新增加的函数,会加在第一个虚表里面
ptr->func3(); 这个代码对应的汇编

1 | .text:00112D5A 8B 45 CC mov eax, [ebp+ptr] //将this指针赋值给eax |
构造析构顺序
构造顺序:
1.构造第一个基类
2.构造第二个基类
……
3.构造成员对象
4.构造自己
析构顺序:即构造顺序反过来
特征:多次覆盖虚表
纯虚函数
在C++中,抽象类是一种不能直接实例化的类。它的主要目的是为派生类提供接口(即一组纯虚函数)。抽象类通常用于定义派生类必须实现的接口,从而确保所有派生类都有一致的接口实现。
纯虚函数会在虚表填一个 _purecall函数,避免未实现而调用,如果直接调用未实现的纯虚函数,那么将会报错
下面是一个包含纯虚函数的抽象类Shape,以及它的派生类Circle和Rectangle。
1 |
|
特征:
1.有偏移表
2.构造顺序:
- 构造虚基类
- 一次构造基类
- 构造成员对象
- 构造自己
析构顺序相反
c++异常处理
1 |
|
一旦try内的语句有抛出(throw)异常,就会去搜索对应的catch块执行语句
值得注意的是,在C++中,当一个异常被抛出时,程序会在找到第一个匹配的catch块之后处理该异常,然后继续执行后续代码。并且,一旦异常被捕获并处理,程序不会再继续搜索其他的catch块来处理同一个异常。
事件查看器
介绍下事件查看器这个工具
可以用来查看具体是什么异常,但是貌似也可以用调试??
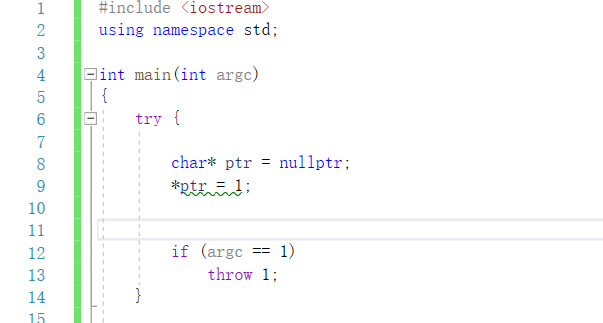
这里手动造一个异常
打开事件查看器,就可以发现具体的错误码和错误偏移,还有路径
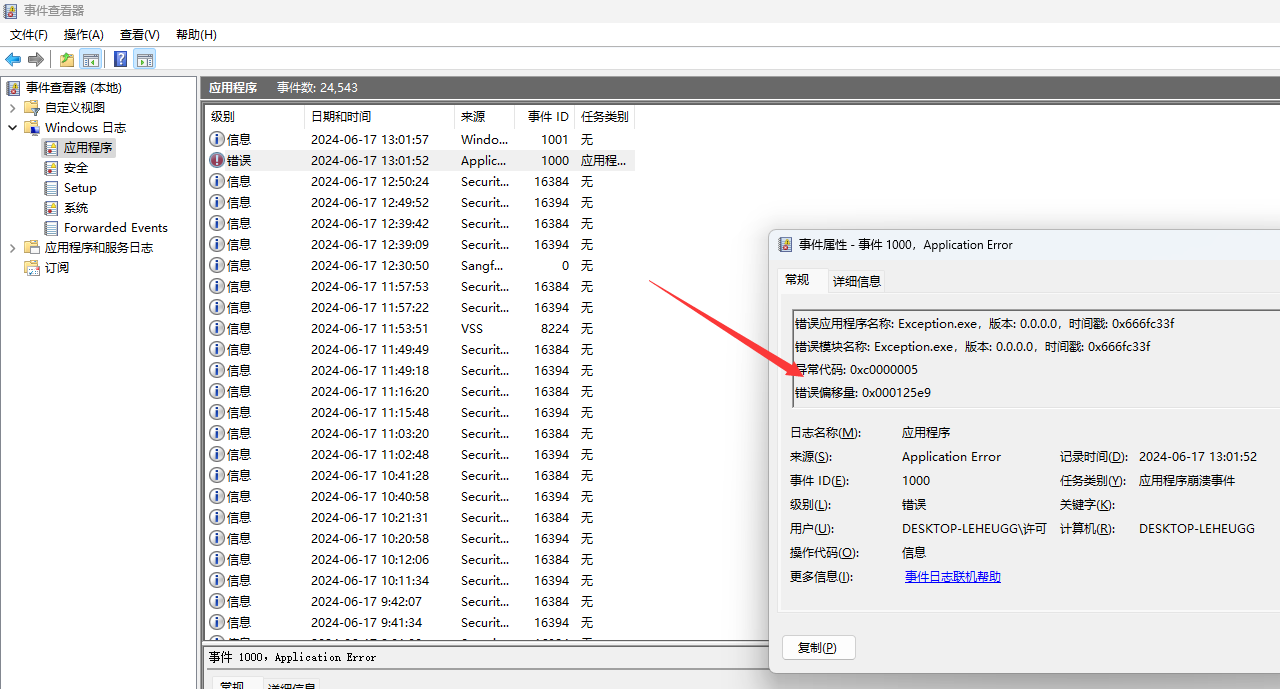
值得注意的是,这个偏移量是ROV,相对于ImageBase的偏移
具体分析C++异常过程
测试代码:
1 |
|
当某个函数有try catch的时候,会在函数头注册一个异常回调函数:
例如下面的main函数开头:
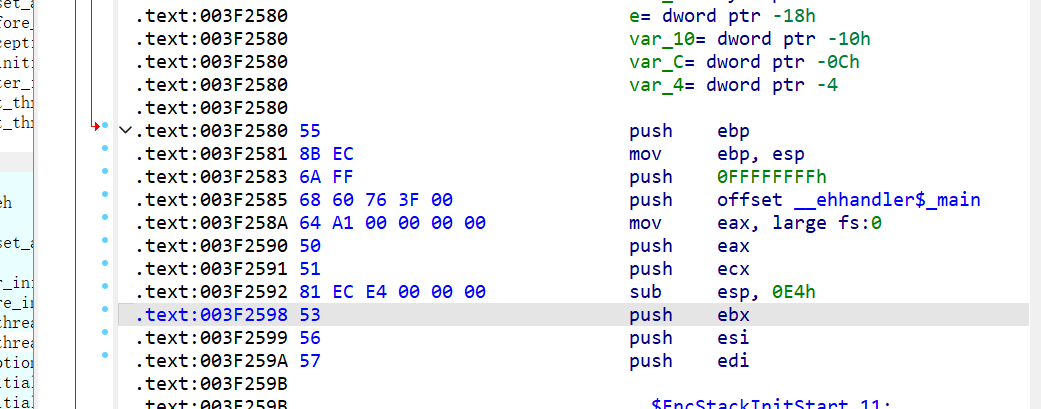
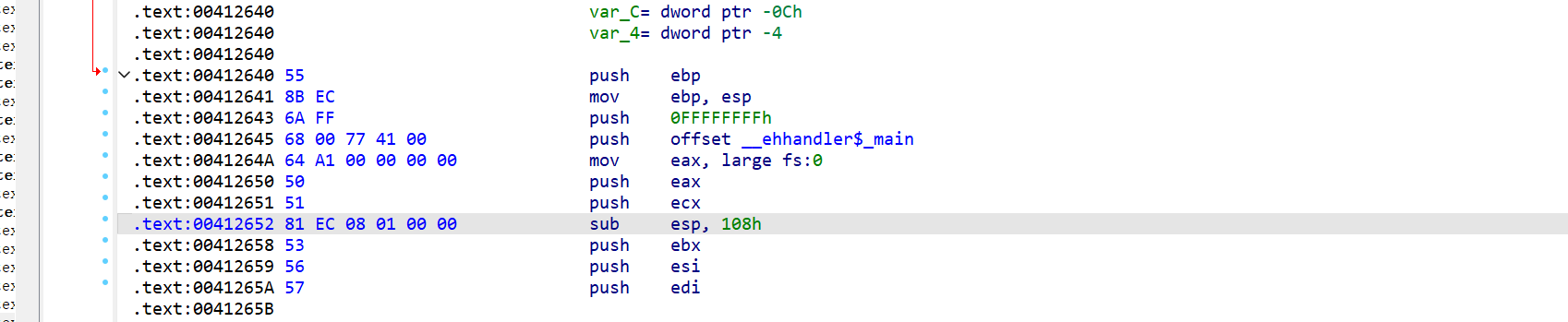
分析一下这个代码是干啥的:
1 | .text:00412640 55 push ebp |
push offset __ ehhandler$ _main,这是一个函数指针,放入栈中
mov eax, large fs:0 将异常链表存入eax
后续会有
1 | .text:00412675 8D 45 F4 lea eax, [ebp-0Ch] |
这个就是将__ehhandler $ _main这个函数置为链表头,原来的作为Next指针存着
这样就实现了将函数_ _ehhandler$ _main 挂入异常链表
在含有try的函数结束之后
1 | .text:008527A6 8B 4D F4 mov ecx, [ebp+var_C] |
会有一个注销异常链表的操作,这里就是拿出next,然后覆盖掉原来的异常链表,这样,就恢复了原来的异常链表(即注销)
之前的 push 0FFFFFFFFh,代表try还没开始,也就是说 [ebp-0x4] 位置代表着 trylevel,如果是0xffffffff则代表try块还未开始,如果是0,就代表进入try块
当结束try块以后,还是会将这个trylevel置为-1
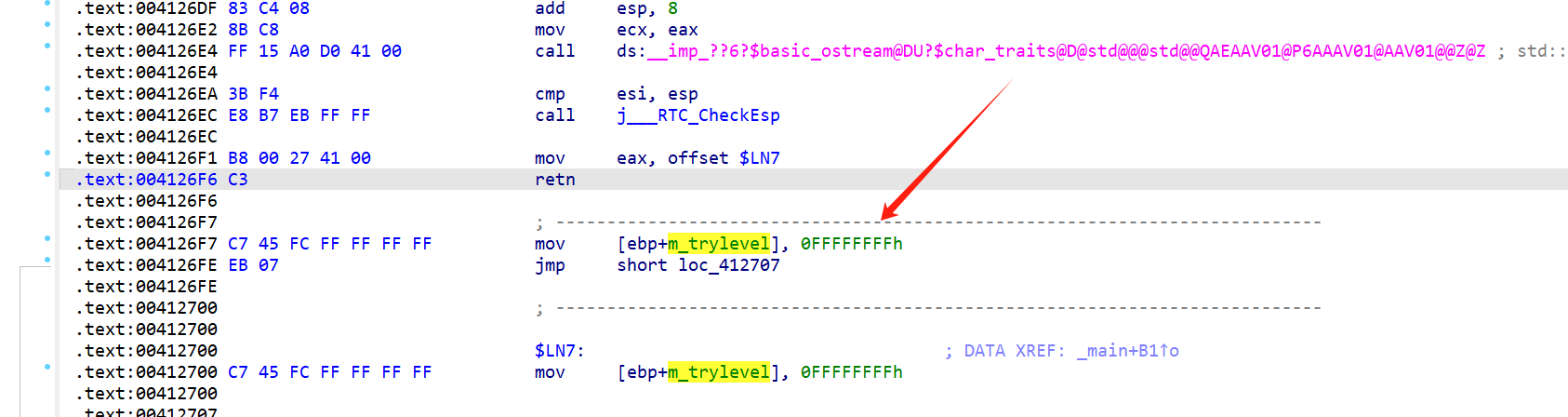
如果有try嵌套:
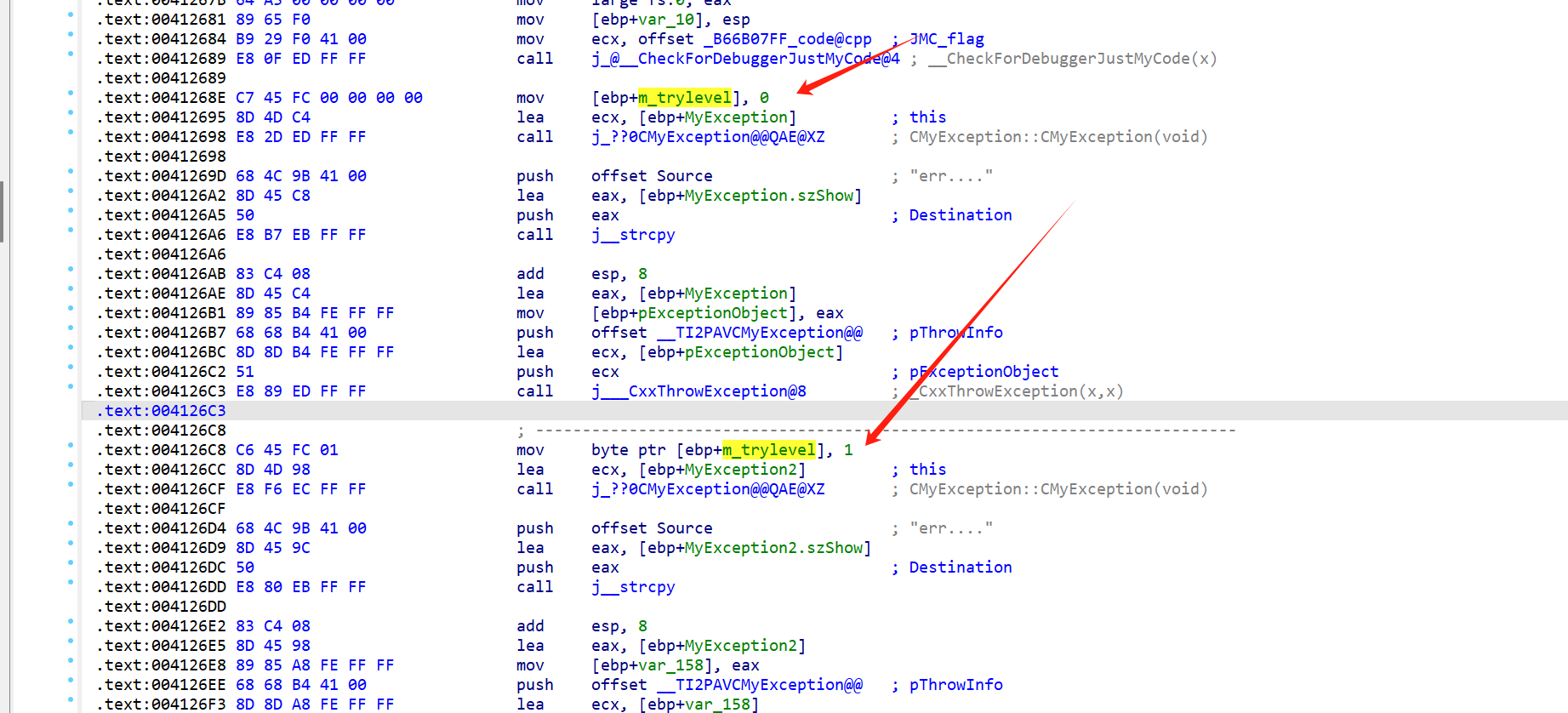
反正也是赋值为非负的一个数
双击__enhandler__$main
在调用函数__CxxFrameHandler之前,会传递一个参数,这里就是eax
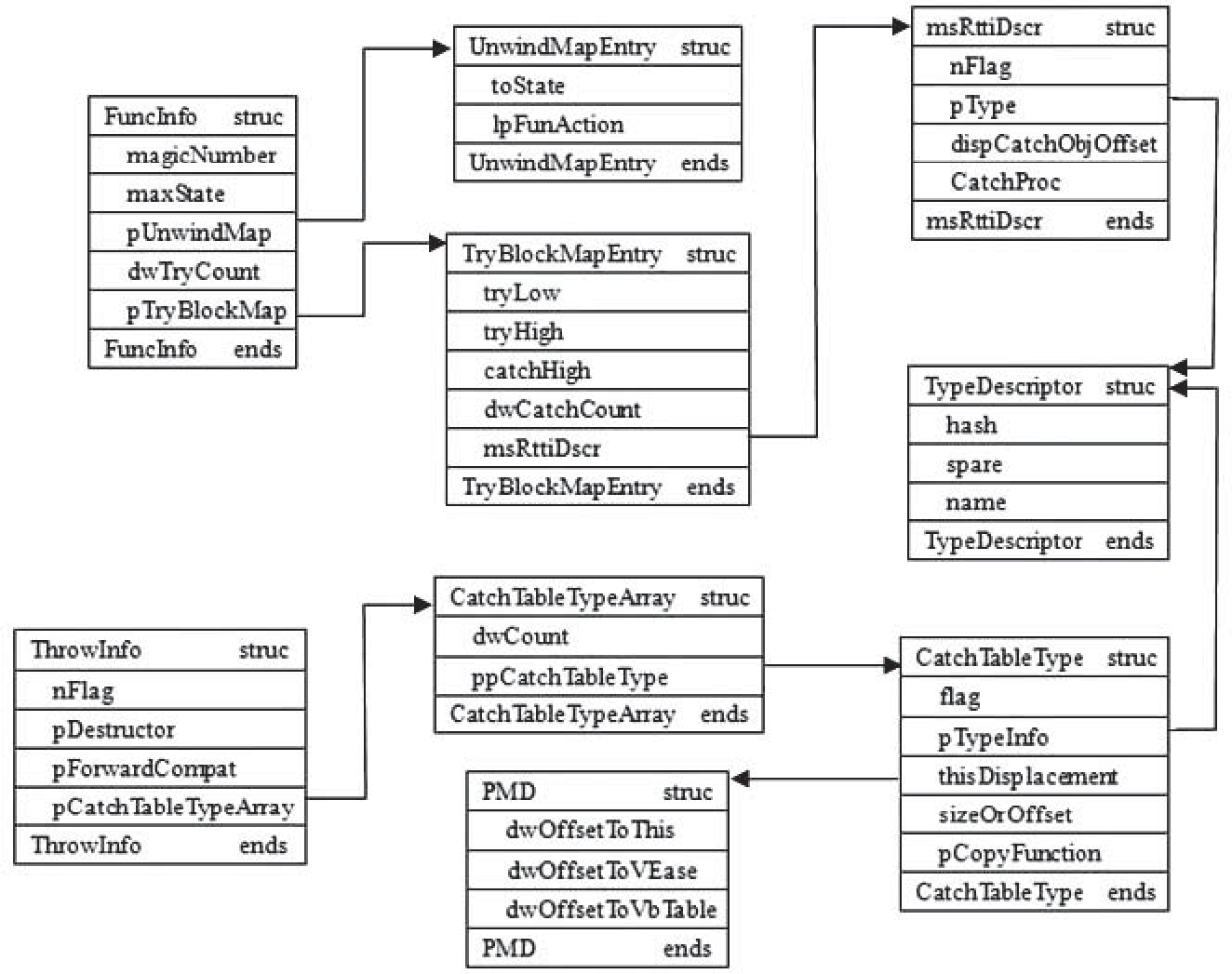
其实这就是FuncInfo函数信息表
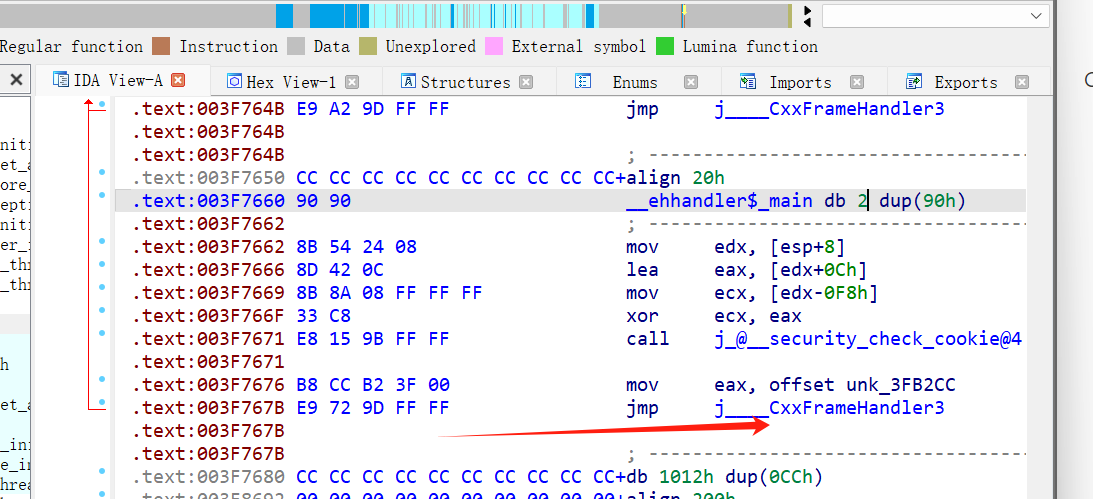
FuncInfo结构
介绍一下FuncInfo
1 | struct FuncInfo |
其中pUnwindMap和pTryBlockMap分别指向 UnwindMapEntry 和 TryBlockMapEntry 结构
UnwindMapEntry要配合FuncInfo里面的maxState使用。
UnwindMapEntry的作用:栈展开的时候需要执行的函数由UnwindMapEntry表记录
TryBlockMapEntry的作用:这个结构用来判断异常产生在哪一个Try块
UnwindMapEntry结构
这个结构记录了需要执行函数
1 | struct UnwindMapEntry |
由于栈展开存在多个对象,因此以数组的形式记录每个对象的析构信息
toState 项用来判断结构是否属于处于数组中,lpFuncAction用于记录析构函数所在的地址
TryBlockMapEntry结构
在这个结构体中可以知道对应的Try有几个Catch,并且能找到对应的Catch块
TryBlockMapEntry块成员长这样:
1 | struct TryBlockMapEntry |
TryBlockMapEnrty 表结构用于判断异常产生在哪一个try块,tryLow,tryHigh 项用于检查产生的异常是否来源于try块中
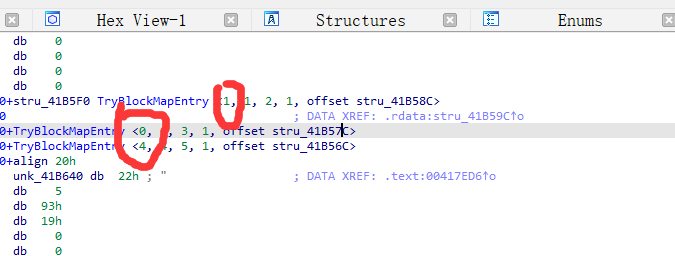
最左边的TryLow才是真正的trylevel下标,另外一个TryHigh是用来描述范围的
_msRttiDscr 结构
这个结构用于描述try块中的某一个catch块的信息
1 | struct _msRttiDscr |
具体来说:
nFlag标记用于检查catch块的类型匹配:
如果是 1 :常量 2:变量 4:未知 8:引用
异常的匹配信息存在pType所指向的结构
这个结构便是 TypeDescriptor
TypeDescriptor结构
这是一个记录 异常类型的结构:具体结构长这样:
1 | struct TypeDescriptor |
有了这些信息之后,就可以通过与抛出异常时的信息进行对比,得到对应的表结构
再通过_msRttiDscr结构中的CatchProc得到catch块的首地址
关于throw
抛出异常的工作 由 throw 抛出,在源代码含有throw的函数体中可以找到 __CxxThrowException 这个函数,和之前 _CxxFrameHandler 类似,之前传进去的参数是 FuncInfo,这回是 ThrowInfo
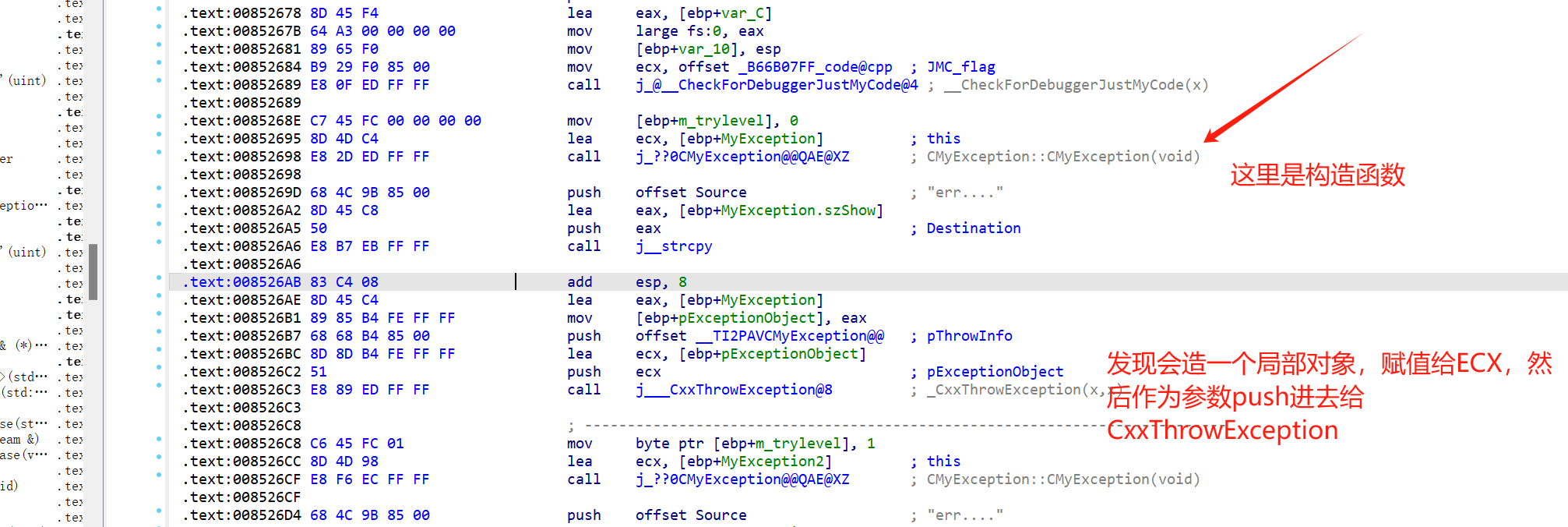
这样可以通过参数,去获取抛出的对象(或者数值)
另外一个参数就是ThrowInfo
每一个throw都对应一个ThrowInfo和一个拷贝的对象。里面包含着对应的信息,包括抛出对象的类型(ThrowInfo),里面放了什么(从拷贝对象可知)
下面是通过ThrowInfo和拷贝对象识别值和类型的过程
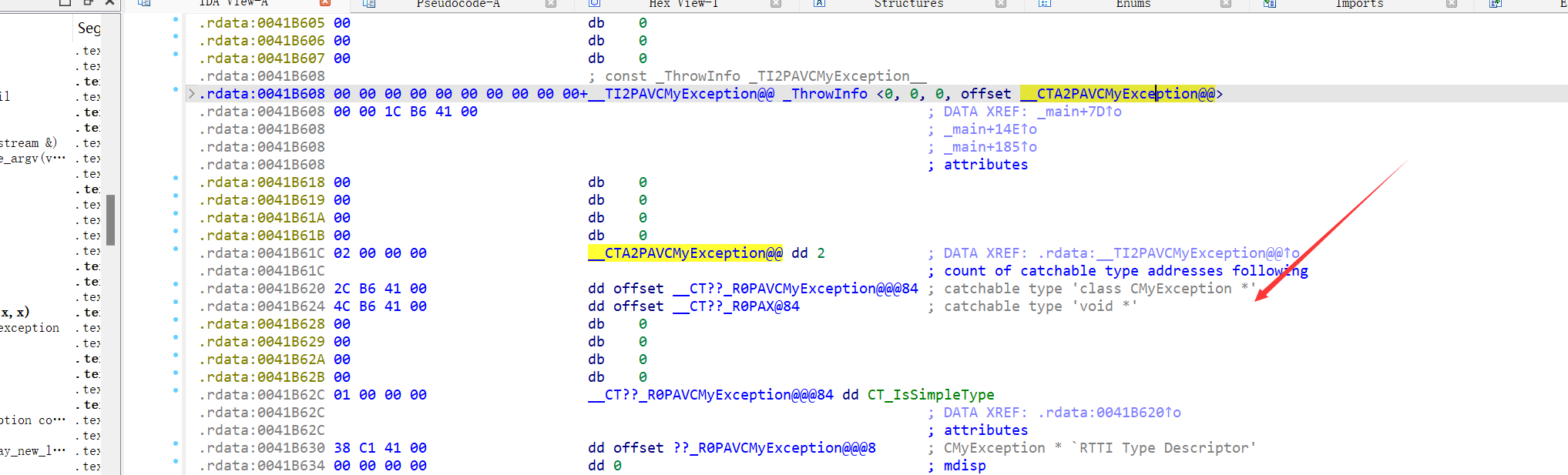
但是为什么会有两个RTTI,这是表示CMyException *的类型和void *类型的异常都可以被接收
ThrowInfo结构
1 | struct ThrowInfo |
nFlag为1的时候,表示抛出常量类型的异常; 2 表示抛出变量类型的异常
由于在try块中产生的异常被处理后就不会再返回try块了。因此pDestructor的作用就是记录try块里面的异常对象的析构函数地址,当异常处理完成以后调用异常对象的析构函数
抛出异常所对应的catch块的类型的信息被记录在pCatchTableTypeArray所指向的CatchTableTyoeArray表结构
ThrowInfo 结构体用于描述异常的类型、析构函数等信息,帮助运行时了解如何处理和清理异常对象。
CatchTableTypeArray结构
1 | struct CatchTableTyoeArray |
ppCatchTableType是一个指向数组的指针,dwCount用来描述数组中元素的个数
CatchTableType中含有含有处理异常时的所需相关信息
CatchTableType结构
CatchTableType中含有含有处理异常时的所需相关信息
1 | struct CatchTableType |
flag用于标记异常对象属于哪一种类型,例如指针,引用,对象等,标记值所代表的含义为:
1:简单类型复制 2:已被捕获 4:有虚表基类复制 8:指针和类型引用复制
当异常类型为对象的时候,由于对象存在基类等相关信息,因此需要将他们也记录下来,thisDisplacement保存了记录基类信息结构的首地址
PMD结构:
1 | struct PMD |
注意注意:
如果Try内有定义对象并且Throw了,那么就要进行析构,Try里面全部对象都要被析构
还原代码的逻辑:
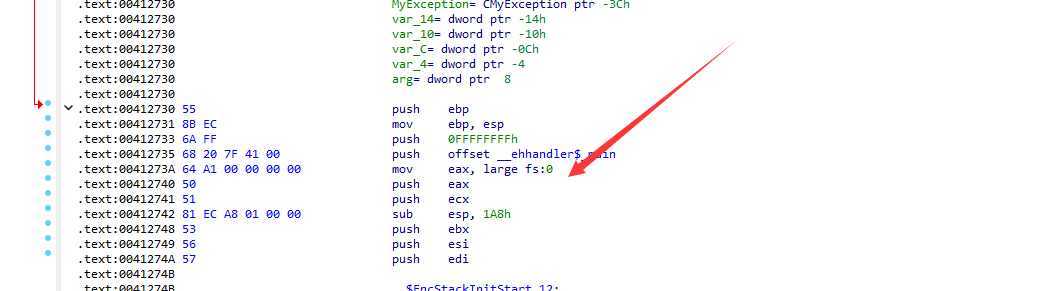
进入一个函数首先看看有没有调用__CxxFrameHandler,和有没有对fs:[0]这个地址进行操作,这个是有异常的标志。
然后一顿操作,把FuncInfo解析出来,有maxState个UnwindMapEntry结构,里面有存析构函数(如果存在析构,具体执行顺序看下标),然后还有dwTryCount个TryBlockMapEntry结构,里面存着Catch块的具体地址(_msRttiDscr 结构)
catch可能不在IDA反编译出来的函数,所以看到try我们需要去自己找对应的catch
解决了这些结构体,就可以看汇编还原代码了。
不要把Catch当成一个函数,而是要把它当成代码块
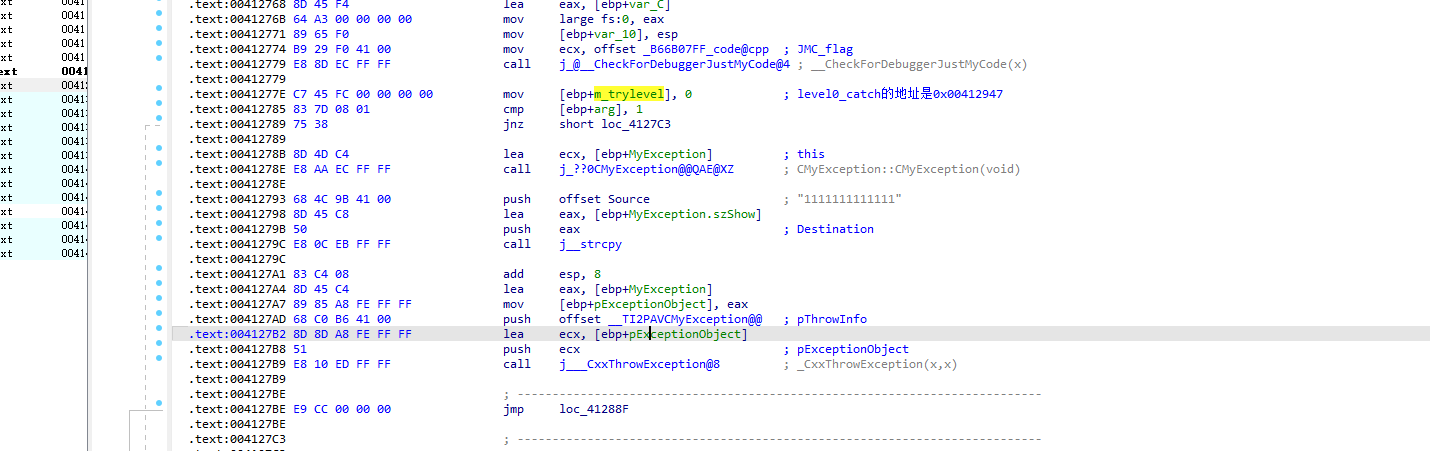
看见trylevel为0,就可以匹配到对应的catch块了
Lambda表达式
在C++中,lambda表达式是一种匿名函数,它可以在需要函数的地方定义和使用。这种表达式可以捕获所在作用域中的变量,并且可以用来简化代码,提高可读性和灵活性。(我的理解是首先可以减小占用的空间,而且可以无脑直接用函数里面定义的参数)下面是lambda表达式的几个主要用途和它们与普通函数调用的区别:
主要用途
- 内联定义简单函数:避免为了定义小函数而额外创建一个函数。
- 回调函数:常用于事件处理和异步编程,例如在GUI编程或网络编程中。
- 函数对象:可以用作标准库算法(如
std::sort,std::for_each)的参数。 - 函数式编程:允许更自然地使用函数作为数据处理的第一类对象。
基本用法
lambda表达式的基本语法如下:
1 | [capture](parameters) -> return_type { |
其中:
capture:捕获列表,用于捕获外部变量。
1.按值捕获
1 | int x = 10; |
2.按引用捕获
1 | int x = 10; |
3.捕获所有外部变量
可以使用[=]按值捕获所有外部变量,或使用[&]按引用捕获所有外部变量。
1 | int a = 1, b = 2, c = 3; |
- 混合捕获
可以混合使用按值捕获和按引用捕获,具体说明要捕获的变量及其捕获方式。
1 | int a = 1, b = 2, c = 3; |
5.隐式捕获和显式捕获
可以同时使用隐式捕获和显式捕获来控制捕获的变量。
1 | int a = 1, b = 2, c = 3; |
6.捕获this指针
在类的成员函数中,lambda表达式可以捕获this指针,从而访问类的成员变量和成员函数。
1 | class MyClass { |
parameters:参数列表,类似于普通函数的参数列表。return_type:返回类型,可选。如果编译器能够推断返回类型,可以省略。function body:函数体,包含lambda的实现代码。
实际逆向
在实际逆向的时候,Lambda实际上是由构造一个类,加函数体实现的
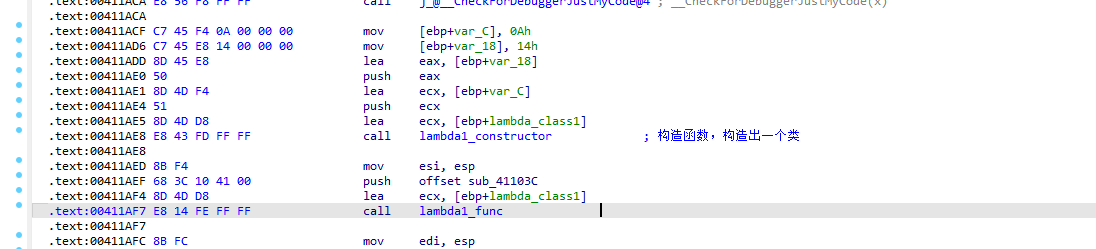
1 | int n1 = 10, n2 = 20; |
1 | .text:00411ACF C7 45 F4 0A 00 00 00 mov [ebp+var_C], 0Ah |
看到类构造+函数调用的,用的是同一个ecx,可以考虑还原为lambda表达式
运算符重载:
没有还原依据
函数模板:
函数模板只在编译阶段有效,本质上是编译器对使用者的方便性设计,实际上不同类型的模板实际上是同的函数,这就需要我们根据可读性进行还原模板。(如果调用模板函数少,不如当成普通函数得了
正是因为这个特性,所以模板函数是无法做成Sig文件给IDA识别的,那么就会导致一个大问题,就是STL函数,本质上也是模板,那么IDA识别STL函数其实是一个难题,会导致可能逆向了很久,最后发现逆的是一个STL函数,那确实令人崩溃
令人悲伤的是:STL函数逆向靠经验
但是可以用字符串比对法,查看错误日志(就是报错的字符串),IDA ctrl+F12去找即可
可以看一下源码对照:
1 |
|
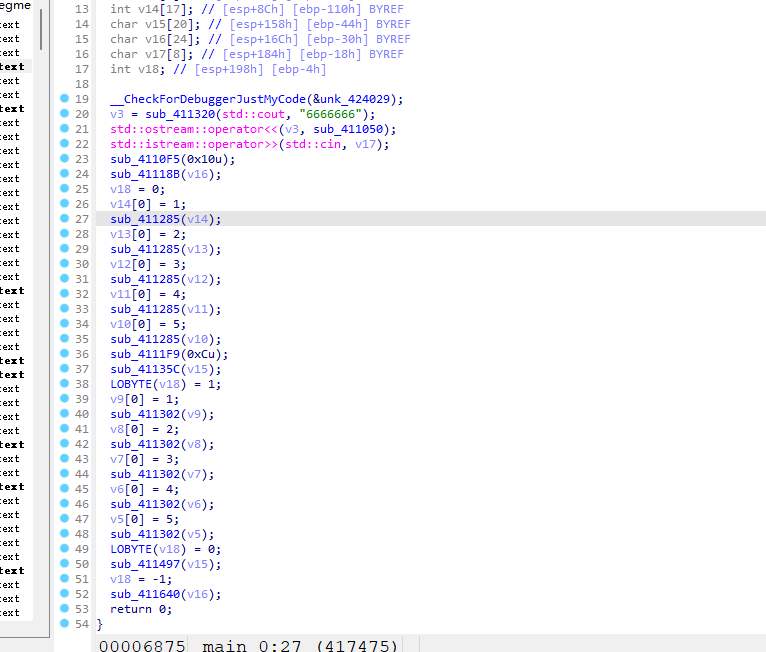
发现除了cout,cin这些是有符号的,其他都没有符号。
原因是:
像 cout 和 cin 这样的流对象,通常是通过具体的函数实现的,并且这些函数在标准库中有固定的位置和符号名,容易被识别。这个模板参数是固定的,所以可以动态链接,有了符号信息,进而被IDA识别
而 vector 和 list 这样的容器是模板类,它们在编译时会实例化生成具体的代码,这些代码在不同的使用场景下可能有所不同,没有固定的位置和符号名,增加了识别难度。这个模板参数不固定,什么变量类型都可以,因此不可以动态链接,只能是静态链接,导致不能被IDA识别。