
C++新特性
C++新特性
多嘴一句,vs中自动对齐代码:选中需要调整格式的内容(可用CTRL+A),然后再按Ctrl + K 和Ctrl + F 就好了
一:auto/decltype
1. auto:自动类型推导
auto关键字允许编译器自动推导变量的类型,特别是在初始化时,编译器可以根据右侧的表达式确定变量的类型。这在处理复杂类型时非常有用,比如模板、迭代器等。
优点
- 简化代码:尤其是在使用长或复杂类型时,不再需要手动写出类型。
- 增强可读性:通过减少冗长的类型声明,代码变得更加简洁明了。
- 避免错误:可以减少在手动写类型时出现的错误。
2.decltype:获取表达式的类型
decltype关键字用于从表达式中获取类型。这对于需要获取某个变量或表达式的精确类型时非常有用。
特点
- 类型推导:
decltype可以从表达式、变量、函数调用等推导出其类型。 - 与
auto配合:decltype常与auto配合使用来解决复杂类型推导的问题。 - 精确性:
decltype可以返回表达式的精确类型,包括引用类型或指针类型。
代码示例:
1 |
|
二:序列for循环
优势
“序列for循环”通常指的是C++11引入的范围for循环(range-based for loop),它允许你遍历一个容器或序列,而不需要手动管理迭代器或索引。这种循环结构使得代码更加简洁,并且避免了传统for循环中容易出错的部分(如越界问题)。
基本语法
范围for循环的语法如下:
1 | for (declaration : range) |
declaration:循环体中每次迭代时的变量,可以是值类型或引用类型。
range:要遍历的容器、数组或序列。
示例代码
1 |
|
三:lambda表达式
lambda简介
C++的Lambda表达式是C++11引入的一个强大功能,允许在函数中定义匿名函数(即没有名字的函数)。Lambda表达式非常灵活,可以用于简化代码,特别是在需要短小函数或回调时。它广泛用于STL算法、事件处理、并行编程等场景。
基本语法
1 | [capture-list](parameter-list) -> return-type |
各部分的含义:
**
[capture]**:捕获外部作用域中的变量。
**[=]**:捕获外部作用域中的所有变量,按值捕获。**
[&]**:捕获外部作用域中的所有变量,按引用捕获。**
[this]**:捕获当前类中的this指针,允许在Lambda表达式中访问类的成员。**
(parameters)**:参数列表,类似普通函数的参数列表。**
-> return_type**(可选):返回值类型,通常可以省略,编译器会自动推导。**
{}**:函数体,包含Lambda表达式的实际逻辑。
代码示例
1 | //捕获所有变量 |
Lambda表达式常用于STL算法中,如std::for_each、std::sort,可以减少编写回调函数的麻烦。
1 |
|
四:构造函数:委托构造和继承构造
在C++中,构造函数是用来初始化对象的特殊函数。C++11引入了委托构造函数和继承构造函数,以增强构造函数的功能,简化代码编写。这两种构造函数分别用于代码复用和基类构造函数的继承。
委托构造函数
委托构造函数是指一个构造函数调用同一类中的另一个构造函数。这可以让构造函数之间共享初始化代码,避免代码重复,简化维护。
基本语法及示例代码
基本语法:
1 | ClassName(parameters) : ClassName(other_parameters) |
示例代码:
1 |
|
运行结果如下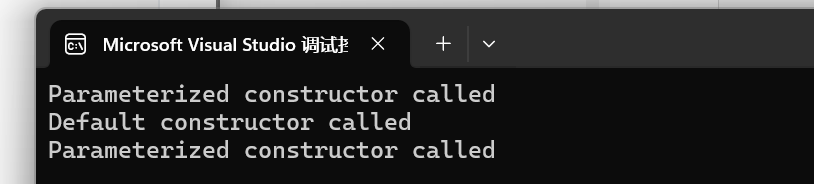
在这个例子中,MyClass()(默认构造函数)委托给MyClass(int, int, int)(参数化构造函数),从而避免了重复的初始化代码。
继承构造函数
继承构造函数是指派生类继承基类的构造函数。它允许派生类自动生成与基类构造函数相同的构造函数,而无需手动编写。C++11之前,派生类必须显式地调用基类构造函数,使用继承构造函数后可以让构造函数的继承更加简洁。
基本语法及示例代码
基本语法
1 | class Derived : public Base |
如果基类有多个构造函数,使用继承构造函数时,派生类将会继承基类的所有构造函数。C++会根据你在创建派生类对象时提供的参数,自动匹配最合适的基类构造函数。
示例代码:
1 |
|
五:容器(array/forward_list/tuple)
C++11引入了许多新特性,其中容器的改进和新增是非常重要的一部分。新加入的容器包括std::array、std::forward_list和std::tuple,它们分别提供了不同的功能和使用场景。
std::array
std::array是一个定长的数组封装,是C++标准库对C语言风格数组的改进,具备安全性和可扩展性。
特点及优势
特点:
- 固定大小:在编译时确定大小,数组大小不能在运行时改变。
- 安全性增强:与C风格数组相比,提供了边界检查功能(使用
at()方法)。 - 与C风格数组兼容:可以与C风格数组互相使用,也支持与STL其他容器的算法配合使用。
优势:
比C风格数组更安全(提供了边界检查)。
与标准库中的算法、迭代器接口兼容。
更具面向对象的特性(支持成员函数,如size()、at()、begin()、end()等)。
代码示例
1 |
|
如果我们代码改为std::cout << "Element at index 10: " << arr.at(10) << std::endl;,故意超出范围,然后调试运行,就会自动报错
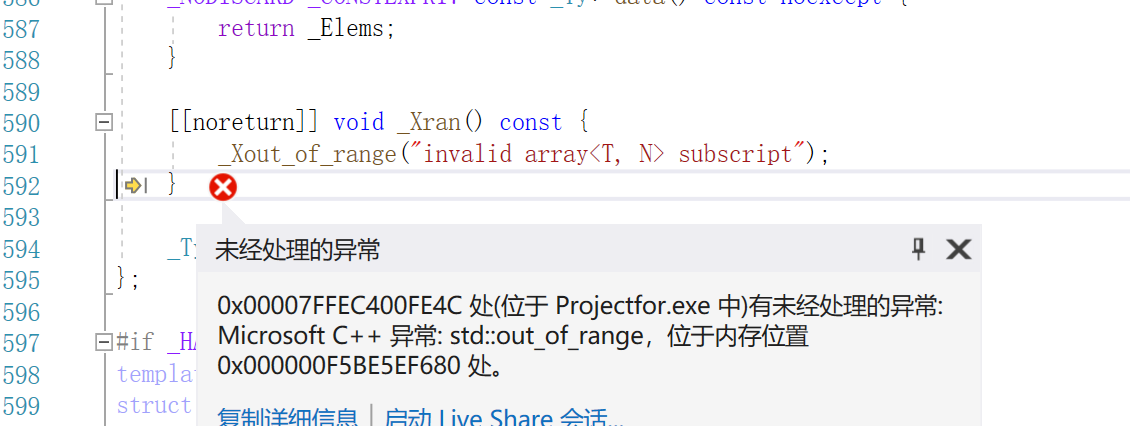
std::forward_list
std::forward_list是C++11引入的单向链表容器,它比传统的双向链表std::list更轻量,适合不需要反向遍历的场景。
特点
- 单向链表:只支持从头到尾的遍历,不支持反向遍历。
- 内存占用较少:与
std::list相比,std::forward_list的内存开销更低,因为它只有单个指向下一个节点的指针。 - 适合在头部插入/删除操作:由于它是单向链表,
push_front的效率非常高。
代码示例
1 |
|
std::tuple & std::tie
std::tuple是C++11引入的模板类,它是可以容纳任意类型、任意数量元素的通用容器。可以把std::tuple看作是std::pair的扩展,允许存储多种类型的数据。
std::tie 是 C++11 中引入的一个功能,用于将多个变量与一个元组(std::tuple)中的值进行解构绑定。通过使用 std::tie,你可以方便地将元组中的值分配给多个变量,而不必逐个提取。
优势
- 支持存储多个不同类型的值,使得它在需要多返回值的场景下非常有用。
- 可以通过
std::tie()和结构化绑定来解构tuple,方便地获取每个元素的值。 - 与
std::get配合使用,可以灵活访问tuple中的元素。
代码示例
1 |
|
六:正则表达式
C++11 引入了正则表达式(Regular Expressions)库,允许开发者通过模式匹配的方式进行字符串处理。这个库位于 <regex> 头文件中,提供了一套完整的正则表达式 API。
基本语法
std::regex 是一个类,用于表示正则表达式。它允许用户通过字符串创建正则表达式对象,支持各种正则表达式语法,如字符类、重复、分组等。
1 | std::regex pattern("^[a-zA-Z ]+$"); // 表示只匹配字母和空格的字符串 |
- 字符匹配:
.:匹配任何单个字符。[abc]:匹配括号内的任一字符(例如,[a-z]表示匹配小写字母)。[^abc]:匹配不在括号内的任一字符。
- 数量词:
*:匹配前面的元素零次或多次。+:匹配前面的元素一次或多次。?:匹配前面的元素零次或一次。{n}:匹配前面的元素恰好 n 次。{n,}:匹配前面的元素至少 n 次。{n,m}:匹配前面的元素至少 n 次,但不超过 m 次。
- 锚点:
^:匹配字符串的开始。$:匹配字符串的结束。
- 分组和选择:
(...):将括号中的表达式作为一个组,可以在数量词中使用。|:表示或操作(例如,a|b匹配a或b)。
- 转义字符:
\:转义字符,用于匹配特殊字符(例如,.、*、?、+等)。
| \d | 匹配数字[0-9] |
|---|---|
| \D | \d 取反 |
| \w | 匹配字母[a-z],数字,下划线 |
| \W | \w 取反 |
| \s | 匹配空格 |
| \S | \s 取反 |
1. 需要转义的元字符
以下是一些需要转义的元字符及其含义:
- **
.**:表示匹配任何单个字符。如果要匹配字面量的点.,就需要使用\.来转义。 - **
***:表示匹配前面的元素零次或多次。如果要匹配字面量的星号*,需要使用\*。 - **
+**:表示匹配前面的元素一次或多次。匹配字面量+需要使用\+。 - **
?**:表示匹配前面的元素零次或一次。要匹配字面量?,需要使用\?。 - **
^**:表示匹配字符串的开始。如果要匹配字面量^,需要使用\^。 - **
$**:表示匹配字符串的结束。要匹配字面量$,需要使用\$。 [和 **]**:表示字符类的开始和结束。如果要匹配字面量[或],需要分别使用\[和\]。(和 **)**:用于创建捕获组。如果要匹配字面量(或),需要使用\(和\)。{和 **}**:表示量词的开始和结束。如果要匹配字面量{或},需要使用\{和\}。- **
\**:用于转义其他字符。如果要匹配字面量反斜杠\,需要使用\\。
std::regex_match 用于检查整个字符串是否与正则表达式完全匹配。只有当整个字符串与正则表达式的模式相符时,返回 true。
1 | bool regex_match(const std::string& str, const std::regex& pattern); |
std::regex_search 用于检查字符串中是否包含与正则表达式匹配的子字符串。如果字符串中至少有一个子字符串符合正则表达式,则返回 true。
1 | bool regex_search(const std::string& str, std::smatch& matchresults, const std::regex& pattern); |
std::sregex_iterator 是 C++ 标准库中用于处理正则表达式匹配的一个迭代器。它的主要作用是遍历给定字符串中所有匹配正则表达式的部分。
1 | std::string str = "I have 2 apples and 10 oranges."; |
代码示例
1 |
|
正则表达式解释
R"( ... )"
R"( ... )"是 C++11 引入的原始字符串字面量(Raw String Literal)。- 原始字符串允许在字符串中使用不转义的字符,包括反斜杠
\,使得正则表达式的书写更清晰。 - 例如,
R"(\w+)"不需要将\转义为\\,而是可以直接使用。
(\w+@\w+\.\w+)
这是正则表达式的主要部分,我们来分解它:
- **
(\w+)**:\w是一个元字符,表示“单词字符”,包括字母(大写和小写)、数字和下划线。等同于[a-zA-Z0-9_]。+是一个量词,表示前面的元素(即\w)可以出现一次或多次。因此,(\w+)匹配一个或多个单词字符,并将其捕获为一个组。
- **
@**:- 这是字面量字符,表示电子邮件地址中的
@符号。
- 这是字面量字符,表示电子邮件地址中的
- **
(\w+)**:- 再次匹配一个或多个单词字符,用于匹配电子邮件地址中的域名部分。
- **
\.**:\.匹配字面量的点.。在正则表达式中,.是一个元字符,表示“任何单个字符”,因此需要用反斜杠\进行转义。
- **
(\w+)**:- 最后,再次匹配一个或多个单词字符,用于匹配电子邮件的顶级域名部分(例如
com、net等)。
- 最后,再次匹配一个或多个单词字符,用于匹配电子邮件的顶级域名部分(例如
std::smatch matchresults.size() 返回的是匹配结果的数量。在使用正则表达式时,如果你的模式包含分组(使用 () 创建的捕获组),那么这个函数可以用来获取所有匹配的组数。
1 |
|
运行结果是: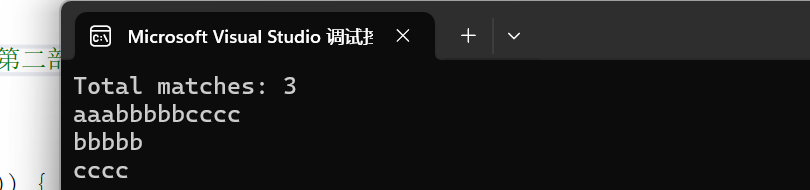
查找所有匹配项:
1 |
|
输出结果:
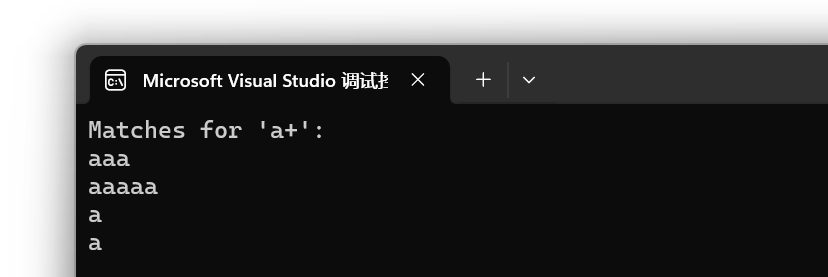
七:智能指针
C++11 引入了智能指针,用来简化动态内存管理,避免手动管理内存带来的资源泄漏、重复释放等问题。智能指针主要包括 std::unique_ptr、std::shared_ptr 和 std::weak_ptr,它们封装了原生指针,并提供了自动释放资源的功能。
std::make_shared & std::make_unique构造std::unique_ptr或者std::shared_ptr的时候,不能用来指定自定义的删除器
std::unique_ptr
std::unique_ptr 是一种独占型智能指针,保证同一时间只有一个指针拥有对象的所有权。它适用于那些只需要单一所有权的场景。
主要特点:
- 单一所有权:同一时间只能有一个
unique_ptr拥有资源。 - 不可复制:
unique_ptr不允许复制,只能移动。 - 自动释放:智能指针超出作用域时,会自动调用删除器释放资源。
使用方式
1 | std::unique_ptr<int> p1(new int(10)); // 通过 new 动态分配内存 |
还可以为std::unique_ptr提供自定义的删除器,用于释放资源
1 | struct Deleter |
std::shared_ptr
std::shared_ptr 是一种共享型智能指针,可以允许多个指针共享同一个对象的所有权。它内部维护一个引用计数,只有当所有的 shared_ptr 都被销毁时,才会释放资源。
主要特点:
- 共享所有权:多个
shared_ptr可以指向同一个对象。 - 引用计数:每个
shared_ptr内部维护一个引用计数,引用计数为 0 时,自动释放资源。 - 线程安全:
shared_ptr的引用计数是线程安全的,但对对象本身的访问不是线程安全的。
使用方式
1 |
|
std::shared_ptr的 自定义删除器的构造 和 std::unique_ptr有所不同,Deleter是写在后面的
1 | std::shared_ptr<int> p1(new int(10), Deleter()); |
运行结果为: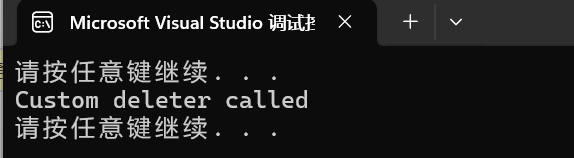
std::weak_ptr
std::weak_ptr 是一种弱引用指针,它不会影响 shared_ptr 的引用计数,通常用于解决循环引用问题。weak_ptr 不能直接访问对象,必须通过 lock() 方法获取一个 shared_ptr 才能访问对象。
主要特点:
- 不控制对象生命周期:
weak_ptr不会影响对象的引用计数,不会参与对象的内存管理。 - 解决循环引用:常用于
shared_ptr循环引用场景,避免资源无法释放。 - 需要 lock:使用前必须通过
lock()获取shared_ptr,并检查对象是否已被销毁。
使用方式:
例如下面的代码场景,node2,node3,node4都指向node1,导致node1指向的对象引用计数变成4了,但是只reset node1,引用计数仍然不为0,因此Deleter根本不会释放
1 |
|
运行结果就是,如果不执行到return 0 这个资源根本不会释放
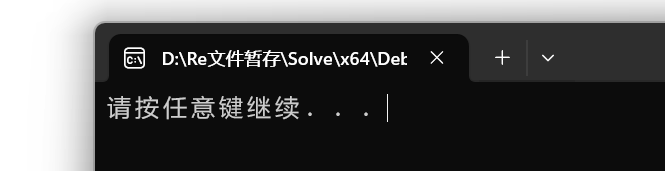
1 |
|
这样就成功释放力
八:nullptr和constexpr
nullptr
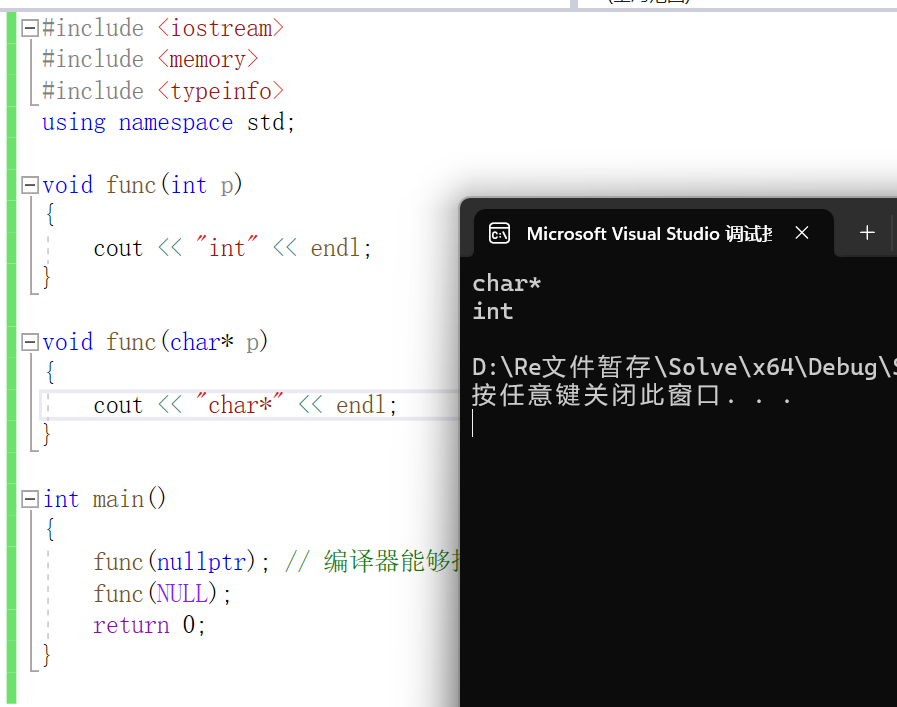
nullptr 是一个新的关键字,用于表示空指针。它的引入解决了 C++ 中 NULL 的一些问题。与传统的 NULL(通常被定义为 0)不同,nullptr 不会被错误地转换为整数类型,从而减少了潜在的错误。
例如下面的代码:
1 | void func(int* p) |
效果如下
constexpr
constexpr 是一个关键字,用于指示某个函数或变量在编译时就能被计算的常量表达式。 使用 constexpr 可以在编译时进行计算,从而提高程序的运行效率。
使用示例
1 | constexpr int square(int x) |
九:关联容器
在 C++ 中,关联容器是用于管理键值对(key-value pairs)或唯一元素(unique elements)的数据结构。与数组或 std::vector 这样的顺序容器不同,关联容器使用键来查找和存储数据,通常具有较高的查找效率。
关联容器分为有序和无序两大类:
- 有序关联容器:如
std::map和std::set,元素按键的顺序排列,基于平衡二叉树(如红黑树)实现。 - 无序关联容器(从 C++11 引入):如
std::unordered_map和std::unordered_set,基于哈希表实现,元素没有固定顺序。
set与unordered_set
std::unordered_set 是 C++11 引入的一种无序集合容器。与传统的 std::set 不同,std::unordered_set 使用哈希表来存储元素,因此元素是无序的,但插入、删除、查找等操作的平均时间复杂度为常数 O(1)。
特点
- 无序存储:
std::unordered_set中的元素没有特定顺序,因为它们是根据哈希值存储的,而不是按大小顺序排列。 - 唯一性:
std::unordered_set中的每个元素都是唯一的,不允许重复元素。 - 快速访问: 哈希表结构让
std::unordered_set的插入、删除和查找操作的平均时间复杂度为常数 O(1)O(1)O(1)。
适用于需要快速查找元素,且不关心元素顺序的场景。例如:
- 查找一组元素中是否存在特定的值。
- 实现去重操作。
和 std::set 的比较
- 底层实现:
std::set是基于红黑树实现的有序集合,而std::unordered_set是基于哈希表实现的无序集合。 - 时间复杂度:
std::set的查找、插入、删除的时间复杂度为 O(logn),而std::unordered_set则为 O(1)。 - 适用场景: 如果需要保持元素的顺序,选择
std::set;如果只关心元素是否存在,且希望更快的访问速度,选择std::unordered_set。
代码示例:
1 |
|
std::unordered_set的find方法
例如下面代码:
1 | std::unordered_set<int> uset = {1, 2, 3, 2}; //重复的“2”不会存储 |
**uset.find(3)**:在 uset 中查找值为 3 的元素。find 函数返回一个迭代器:
如果 3 存在,返回指向该元素的迭代器。
如果 3 不存在,返回 uset.end() 迭代器,这个迭代器表示超出集合的范围(相当于“未找到”)。
map与unordered_map
std::map 和 std::set 是 C++ 标准库中常用的关联容器。
std::map: 是一种键值对(key-value)容器,存储键(key)和对应的值(value),其中每个键都是唯一的。可以通过键找到对应的值。
std::set: 仅存储唯一的键(key),不包含值(value)。可以通过键判断集合中是否包含该元素。
代码示例:
1 |
|
在 std::map 和 std::unordered_map 中,每个元素都是一个 std::pair,其中 first 是键,second 是值。 这也是序列for循环如此写的原因
十:function函数对象
要包含头文件 #include
std::function是C++11标准库中提供的一种可调用对象的通用类型,它可以存储任意可调用对象,如函数指针,函数对象,成员函数指针和lambda表达式。std::function类模板是一个类似于函数指针的类型,但它是可以处理任意可调用对象的,并且可以检查调用对象是否为空。
特点
灵活性 :
std::function 可以封装多种类型的可调用对象,包括:
- 普通函数
- 成员函数
- 函数指针
- Lambda 表达式
- 任何实现了
operator()的对象
简化代码:
使用 std::function 可以使代码更加简洁和可读。你不需要明确地指定函数指针的类型,可以直接使用 std::function 来捕捉可调用对象,从而减少代码的复杂性。
例如下面的代码:
1 |
|
可存储不同类型的可调用对象
1 |
|
支持绑定
1 |
|
基本语法
1 | std::function<return_type(parameter_types)> var_name; |
其中,return_type是函数返回值类型,parameter_types是函数参数类型。
1 |
|
十一:atomic_flag应用
atomic_flag 是 C++11 引入的一种原子类型,用于实现线程安全的标志位。它提供了一种简单的方式来控制和协调多个线程之间的操作,避免了使用锁或其他同步机制带来的复杂性和开销。下面是 atomic_flag 的一些应用及其基本特性:
原子性:原子操作意味着在执行某个操作的过程中,不会被其他线程中断。换句话说,这个操作是不可分割的,要么完全执行成功,要么完全不执行。硬件通常提供了支持原子操作的指令集,使得操作在多线程环境中是安全的。
设置和清除: 主要有两个操作:
设置(test_and_set()):将标志位设置为 true(通常表示“锁定”状态),并返回设置之前的值。
清除(clear()):将标志位设置为 false(表示“解锁”状态)。
工作原理
atomic_flag 通常使用单个位(bit)来表示其状态。这个位在内存中是以原子方式读写的,确保即使多个线程同时尝试修改它,也不会导致数据损坏或不可预测的行为。
当一个线程调用 test_and_set() 方法时,操作会在底层使用 CPU 提供的原子指令(如 LOCK 前缀在 x86 架构中)来确保这个操作的原子性。该操作会在设置标志位之前读取其当前状态,并将标志位更新为 true。其他线程在调用 test_and_set() 时,如果该标志位已经被设置为 true,它们会得到这个已设置的状态,从而知道它们无法获得“锁”。当线程完成其操作后,可以调用 clear() 方法将标志位重置为 false,允许其他线程访问共享资源。
特点
比同步对象更加轻量级,因为是原子性的, 例如,互斥锁可能会使用操作系统的调度机制来挂起和恢复线程,这涉及上下文切换和内核态的操作,这些操作的开销较大。 相比之下,atomic_flag 的操作通常只涉及简单的原子指令
atomic_flag 不会导致上下文切换:在使用 atomic_flag 的情况下,如果一个线程在尝试获取锁时发现标志位已被设置,它可以选择忙等待(spin wait),即在循环中反复尝试获取锁,而不需要被挂起。这种方式避免了上下文切换的开销。
高性能要求的场景:在需要快速访问和锁定的高性能应用中,atomic_flag 提供了更低的延迟和开销。
示例代码:
1 |
|
十二:条件变量condition_variable
在 C++11 中,std::condition_variable 是一个非常重要的同步机制,通常用于线程之间的协调与通信。它允许一个线程等待某个条件满足后继续执行,而另一个线程可以在条件满足时通知等待的线程,使其继续运行。
与互斥锁 (std::mutex) 搭配使用时,std::condition_variable 能够在多个线程之间实现安全、有效的资源共享。
condition_variable基本语法
等待线程调用 wait 等待条件变量
1 | std::unique_lock<std::mutex> lock(mutex); // 先锁住互斥锁 |
其中 wait 的第二个参数是一个 lambda 表达式或函数,返回 true 表示条件满足,线程可以继续执行。如果条件不满足,线程会阻塞在这里。
wait的第二个参数不一定要写,也可以就一个lock
另外这里的wait的第二个参数,一定要在执行wait这个类方法之前就要满足,否则执行这个wait时,第二个参数即使一开始不满足,后面一段时间满足了,也是不能继续运行下去的,这是一个坑点
通知线程调用 notify_one 或 notify_all 唤醒等待中的线程:
1 | std::lock_guard<std::mutex> lock(mutex); // 锁住互斥锁 |
cv.notify_one() 的作用是唤醒 等待该条件变量的线程中的一个,但它并不会“选择”具体的线程。具体唤醒哪个线程由操作系统的调度器决定,通常是按照先等待的线程先唤醒,但这并不一定是确定的。
lock_guard&unique_lock
std::lock_guard 是一个简单的 RAII 风格的锁管理器,在构造时自动锁定互斥锁,并在析构时自动解锁。它没有额外的灵活性,比如锁的延迟上锁、手动解锁或重新锁定等。 std::lock_guard 在创建时会自动加锁,一旦创建,它会在作用域结束时(大括号 } 处)自动解锁,确保 mtx 始终会被正确解锁,避免死锁或锁未释放的问题。
std::unique_lock 是一个更灵活的锁管理器,提供了更多功能,比如可以延迟上锁(defer_lock)、手动解锁、重新锁定等。这使得它更适合复杂的同步场景。
它们的设计是为了方便管理 mutex 的锁定和解锁
代码示例:
1 |
|
运行如图: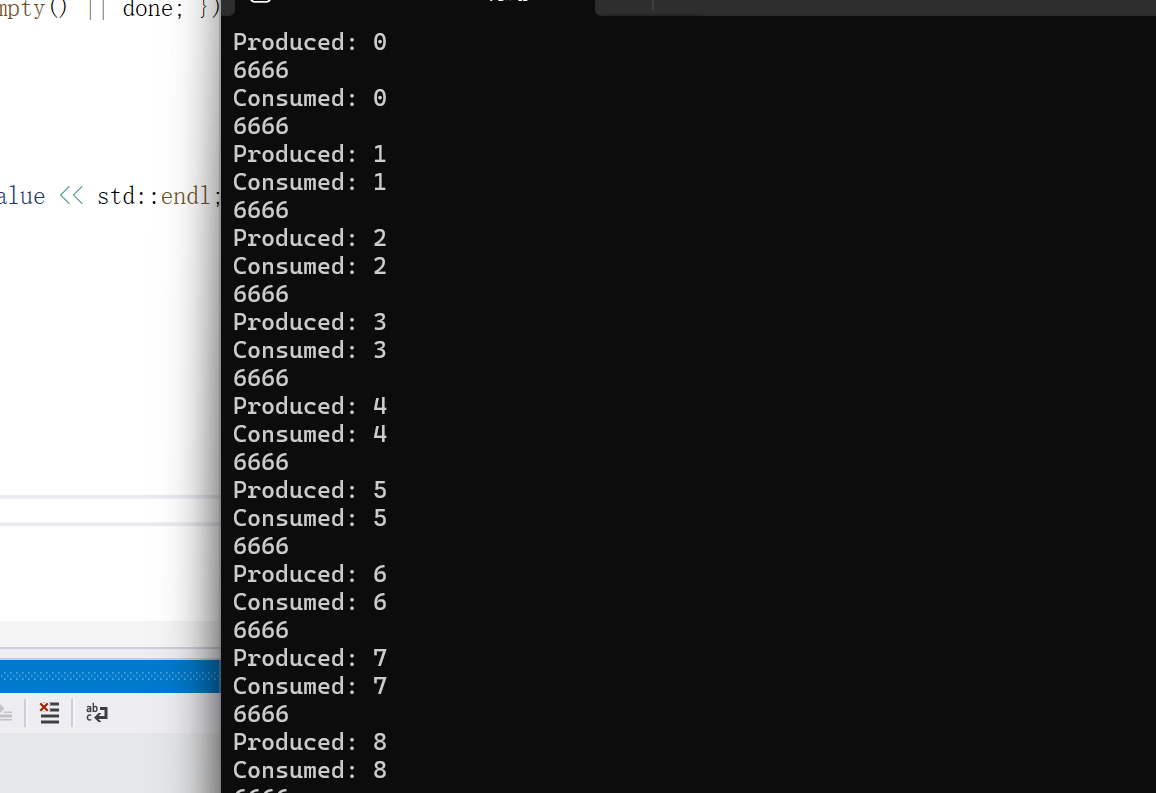
分析代码
让我们来分析一波为什么长这样:
首先先启动的是t1线程,也就是进行producer这个函数
1 | void producer() |
std::unique_lock<std::mutex> lock(mtx);这一句代码会尝试获取锁,如果没有,就会阻塞,线程被cpu挂起, 唤醒机制:当持有该锁的线程释放锁(例如调用 mtx.unlock() 或 std::unique_lock 的析构函数)
因为没有人比t1这个线程更先获取这个mtx,所以不会被阻塞,顺利地输出了Produced:
cv.notify_one();的作用是,给cv.wait()一个信号,让cv.wait()去检查参数是否为true,如果为true就停止cv.wait的阻塞, 如果条件仍然不满足,线程会继续阻塞,直到下一次 notify_one() 或 notify_all() 被调用,并且条件满足。
当Sleep(2000)结束以后,也就是出了},意味着出了lock这个类的作用域,那么就会自动析构,也就是调用lock.unlock(如果有锁),那么此时,t2线程,也就是consumer()迎来了获得锁的机会
1 | void consumer() |
一开始由于t1线程先获取了mtx,所以t2,也就是consumer()被阻塞在std::unique_lock<std::mutex> lock(mtx);,被迫进入休眠,但当producer()的lock析构了之后,consumer()迎来了机会,马上拿到了锁,于是开始执行consumer()的代码,轮到producer()在std::unique_lock<std::mutex> lock(mtx);被阻塞了
由于之前producer()已经调用过cv.notify_one(); 了,意味着cv.wait()知道了此时可以去检查条件了,因此就去看!goods.empty() || done; 是否不为0,于是成功输出"Consumed: "
如此反复