网络编程 Visual Studio跨平台 因为我是一个Windows选手,VS用惯了,叫我去用别的IDE确实比吃了xx还难受,所以研究了一下如何在Windows桌面端用Visual Studio编译,运行,调试,附加调试Linux的程序
首先要按照 Visual Studio IDE跨平台编写和调试Linux C/C++程序_visual studio跨平台编译-CSDN博客 这篇博客的内容,用ssh协议,让虚拟机和Visual Studio建立连接
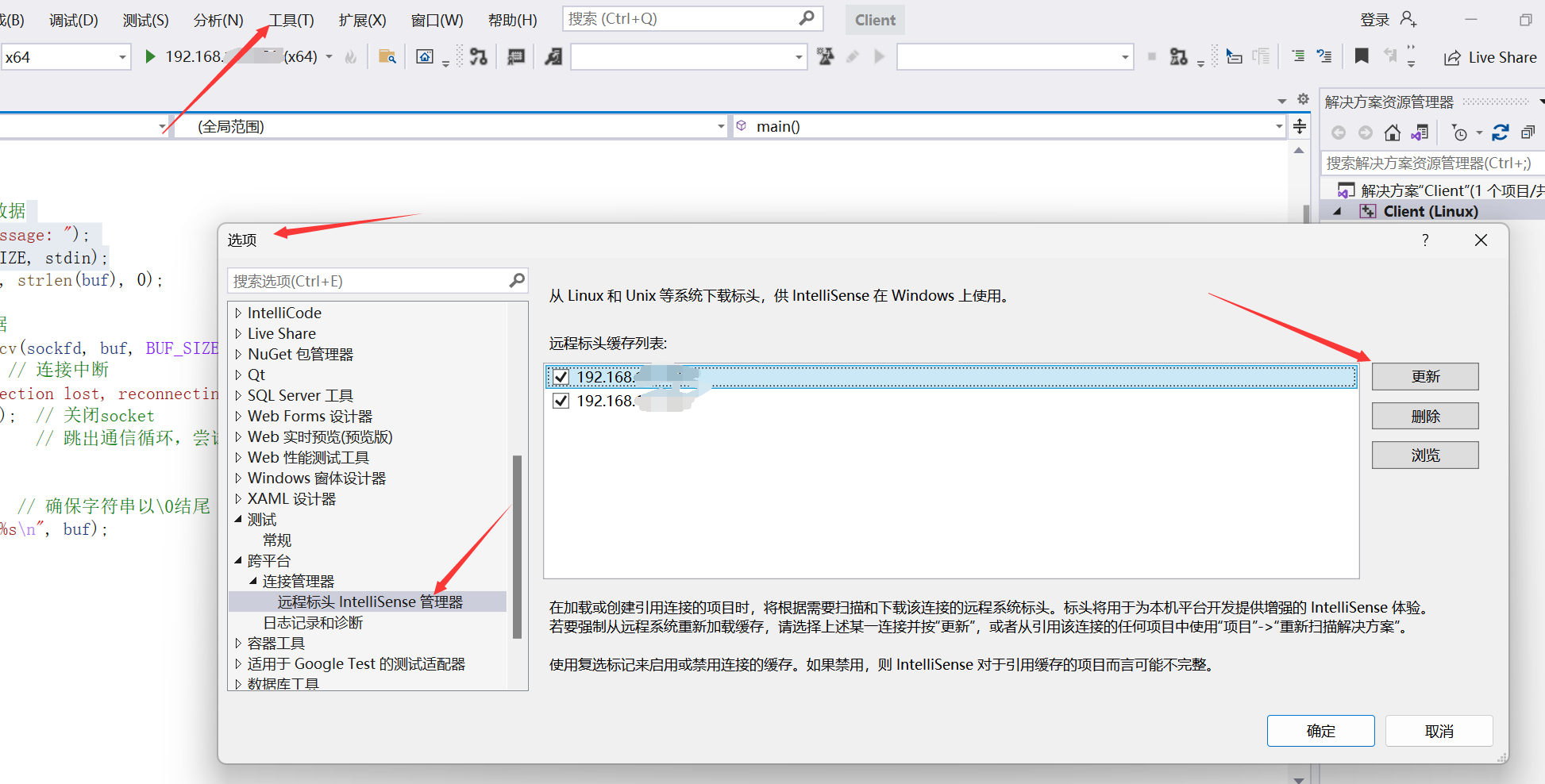
其次,会遇到一个问题,Visual Studio大规模遇到不认识的库,疯狂报错,飘红,但是可以编译成功,这是因为VS还没把库全部拷贝过来,具体要在这里设置,点击更新或者下载即可
还有,记得要以root帐户登录,这样才有足够的权限附加调试
但是ubuntu默认不能以root帐户登录,具体看这一篇文章 Ubuntu 系统直接使用 root 用户登录实例 - 知乎
然后就可以快乐地附加调试了
Linux前置知识 主要是为了网络编程的考试
因为我是一个Windows选手,所以Linux的恶补了下
Linux下的编译和链接 Linux下的动态链接 在Linux系统中,ldd 命令用于显示一个可执行文件或共享库所依赖的动态链接库信息。
1 2 3 4 aichch@sword-shield:~/桌面$ ldd chall linux-vdso.so.1 (0x00007ffe64ded000) libc.so.6 => ./libc.so.6 (0x00007fb193153000) ./ld-linux-x86-64.so.2 => /lib64/ld-linux-x86-64.so.2 (0x00007fb193383000)
在Linux中,linux-vdso.so.1、libc.so.6 和 ld-linux-x86-64.so.2 类似于 Windows 的一些系统级 DLL 和运行时库。
linux-vdso.so.1 是 Linux 虚拟动态共享对象 (VDSO),它帮助用户态程序快速访问某些内核功能,而无需通过系统调用进入内核模式。常见功能包括获取时间(如 gettimeofday)等。 类似于 Windows 内核中的一些优化机制,比如 ntdll.dll 中提供的快速路径函数(如直接与内核交互的函数)。 libc.so.6 是 GNU C 库(glibc)的共享库,提供标准 C 函数(如 printf、malloc、memcpy 等)。它是绝大多数 Linux 应用程序的基础运行时库。 类似于 Windows 的 C 运行时库(CRT),如 msvcrt.dll 或更现代的 ucrtbase.dll,它们提供标准的 C 函数。 ld-linux-x86-64.so.2 是动态链接器(dynamic linker),负责加载和解析程序运行时所需的共享库,并启动程序。 类似于 Windows 的动态链接加载机制,尤其是 LoadLibrary 和 GetProcAddress 相关功能,动态链接器还可以类比为 Windows 中处理 PE 文件动态加载的功能模块。
GCC的编译常见选项 基本编译选项
-c:仅编译,不进行链接,生成目标文件(.o)。
-o :指定输出文件名。
-E:仅进行预处理,不进行编译。
-S:将代码编译成汇编代码,而不是目标文件。
-v:显示详细的编译过程。
--help:显示可用选项的帮助信息
优化选项
-O0:关闭优化(默认)。
-O1:基本优化,编译速度快。
-O2:进一步优化,包括更多代码改进。
-O3:最高级别优化,启用 CPU 密集型优化(如循环展开)。
-Os:优化生成的代码大小。
-Ofast:极致优化,不考虑标准兼容性。
-funroll-loops:展开循环,可能提高性能。
调试相关选项
-g:生成调试信息,用于调试工具(如 gdb)
调试的时候,不要开优化
1 2 3 4 5 gcc -c test.c -g -O0 -o test.o gcc test.o -o test gcc test.c -g -O0 -o test
标准和架构支持
-std=<standard>:指定使用的 C 或 C++ 标准,如:-std=c89、-std=c99、-std=c11(C 标准)。-std=c++98、-std=c++11、-std=c++17(C++ 标准)。
-m32:生成 32 位代码。
-m64:生成 64 位代码
makefile Makefile 文件描述了 Linux 系统下 C/C++ 工程的编译规则,它用来自动化编译 C/C++ 项目。一旦写编写好 Makefile 文件,只需要一个 make 命令,整个工程就开始自动编译,不再需要手动执行 GCC 命令。
具体参考这篇文章吧,用到了再用AI生成浅显易懂 Makefile 入门 (01)— 什么是Makefile、为什么要用Makefile、Makefile规则、Makefile流程如何实现增量编译_makefile是干什么的-CSDN博客
和Windows的一些类比 鉴于本人技能树全点Windows了,看到Linux的一些专业术语真的是懵的一批,下面介绍下我认为的类比
Linux的文件描述符: 是Linux操作系统内核用来标识和管理文件资源的整型标识符。它是一个非负整数,用于指代被打开的文件,所有执行I/O操作的系统调用都通过文件描述符来实现。文件描述符不仅用于文件,还可以表示其他资源,如套接字、管道等。
一些函数 fork和exec
fork 是一个系统调用,用于创建一个新的进程。新进程(子进程) 是 父进程 的副本,包括代码段、数据段、文件描述符等,但两者运行在独立的内存空间中。
子进程从 fork
父进程中,fork 返回子进程的 PID。
子进程中,fork 返回 0。
exec 是一组系统调用,用于替换当前进程的内存空间并执行新的程序。
调用 exec 后,当前进程的代码、数据段被新程序替换,但 PID 不变。
适合用于加载新的二进制文件,配合 fork 实现父子进程的分工。
实现类似Windows的CreateProcess的代码a 程序调用 fork 创建子进程,然后在子进程中用 exec 加载并运行 b 程序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include <unistd.h> #include <stdio.h> #include <stdlib.h> #include <sys/wait.h> int main () pid_t pid = fork(); if (pid < 0 ) { perror ("fork failed" ); exit (EXIT_FAILURE); } else if (pid == 0 ) { printf ("Child process: Starting program b\n" ); execl ("/path/to/b" , "b" , NULL ); perror ("execl failed" ); exit (EXIT_FAILURE); } else { printf ("Parent process: Waiting for child process\n" ); int status; waitpid (pid, &status, 0 ); if (WIFEXITED (status)) { printf ("Child process exited with status %d\n" , WEXITSTATUS (status)); } } return 0 ; }
wait函数:
wait 函数用于使父进程暂停执行,直到一个或多个子进程结束。这个函数通常与 fork 函数一起使用,以确保父进程在继续执行之前等待其子进程完成它们的任务。wait 函数可以获取子进程的终止状态,这对于获取子进程的退出代码或了解子进程是否因为信号而终止非常有用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 int main () pid_t pid1 = fork(); pid_t pid2 = fork(); if (pid1 == 0 || pid2 == 0 ) { printf ("This is a child process.\n" ); sleep (2 ); return 0 ; } else { int status; pid_t wpid; wpid = waitpid (pid1, &status, 0 ); if (wpid == -1 ) { perror ("waitpid error" ); return 1 ; } printf ("First child process with PID %d has finished.\n" , wpid); wpid = waitpid (pid2, &status, 0 ); if (wpid == -1 ) { perror ("waitpid error" ); return 1 ; } printf ("Second child process with PID %d has finished.\n" , wpid); } return 0 ; }
在Windows与之对应的是WaitForSingleObject和WaitForMultipleObjects
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 #include <windows.h> #include <iostream> int main () STARTUPINFO si1 = { 0 }, si2 = { 0 }; PROCESS_INFORMATION pi1 = { 0 }, pi2 = { 0 }; si1.cb = sizeof (si1); si2.cb = sizeof (si2); const char * processName1 = "notepad.exe" ; const char * processName2 = "calc.exe" ; if (!CreateProcess ( NULL , (LPSTR)processName1, NULL , NULL , FALSE, 0 , NULL , NULL , &si1, &pi1)) { std::cerr << "Failed to create first process. Error code: " << GetLastError () << std::endl; return 1 ; } if (!CreateProcess ( NULL , (LPSTR)processName2, NULL , NULL , FALSE, 0 , NULL , NULL , &si2, &pi2)) { std::cerr << "Failed to create second process. Error code: " << GetLastError () << std::endl; return 1 ; } std::cout << "Processes created. Waiting for both to finish..." << std::endl; HANDLE handles[2 ] = { pi1.hProcess, pi2.hProcess }; DWORD waitResult = WaitForMultipleObjects (2 , handles, TRUE, INFINITE); if (waitResult >= WAIT_OBJECT_0 && waitResult < WAIT_OBJECT_0 + 2 ) { std::cout << "Both processes finished." << std::endl; DWORD exitCode1 = 0 , exitCode2 = 0 ; if (GetExitCodeProcess (pi1.hProcess, &exitCode1)) { std::cout << "First process exit code: " << exitCode1 << std::endl; } else { std::cerr << "Failed to get first process exit code. Error code: " << GetLastError () << std::endl; } if (GetExitCodeProcess (pi2.hProcess, &exitCode2)) { std::cout << "Second process exit code: " << exitCode2 << std::endl; } else { std::cerr << "Failed to get second process exit code. Error code: " << GetLastError () << std::endl; } } else { std::cerr << "Failed to wait for processes. Error code: " << GetLastError () << std::endl; } CloseHandle (pi1.hProcess); CloseHandle (pi1.hThread); CloseHandle (pi2.hProcess); CloseHandle (pi2.hThread); return 0 ; }
Linux 信号(Signal) 信号是一个轻量级的机制,它允许进程通过发送一个信号来通知另一个进程发生了某些事件。每个信号都与特定的事件相关联,例如:
SIGINT :终端中断(通常是 Ctrl+C)。SIGTERM :请求终止进程。SIGKILL :强制终止进程。SIGSEGV :段错误(访问无效内存)。SIGCHLD :子进程状态变化(如子进程退出)。
信号的类型
标准信号 :例如 SIGKILL、SIGTERM、SIGINT 等,它们用于通知进程发生的事件。自定义信号 :应用程序可以使用 SIGUSR1 和 SIGUSR2 作为用户定义的信号来执行某些自定义行为。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #include <signal.h> #include <stdio.h> #include <stdlib.h> void signal_handler (int signal) if (signal == SIGINT) { printf ("Caught SIGINT, exiting program...\n" ); exit (0 ); } } int main () signal (SIGINT, signal_handler); while (1 ) { printf ("Running... Press Ctrl+C to send SIGINT\n" ); sleep (1 ); } return 0 ; }
Windows 中的类似机制是 事件 和 异常处理 。
Linux下的同步机制 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 #include <pthread.h> #include <stdio.h> #include <stdlib.h> #include <unistd.h> #define BUFFER_SIZE 1 int buffer = 0 ;pthread_mutex_t mutex;pthread_cond_t cond;void * producer (void * arg) while (1 ) { sleep (1 ); pthread_mutex_lock (&mutex); while (buffer == BUFFER_SIZE) { printf ("Producer: Buffer is full, waiting for consumer...\n" ); pthread_cond_wait (&cond, &mutex); } buffer = 1 ; printf ("Producer: Produced data, buffer = %d\n" , buffer); pthread_cond_signal (&cond); pthread_mutex_unlock (&mutex); } return NULL ; } void * consumer (void * arg) while (1 ) { sleep (2 ); pthread_mutex_lock (&mutex); while (buffer == 0 ) { printf ("Consumer: Buffer is empty, waiting for producer...\n" ); pthread_cond_wait (&cond, &mutex); } buffer = 0 ; printf ("Consumer: Consumed data, buffer = %d\n" , buffer); pthread_cond_signal (&cond); pthread_mutex_unlock (&mutex); } return NULL ; } int main () pthread_t producer_thread, consumer_thread; pthread_mutex_init (&mutex, NULL ); pthread_cond_init (&cond, NULL ); pthread_create (&producer_thread, NULL , producer, NULL ); pthread_create (&consumer_thread, NULL , consumer, NULL ); pthread_join (producer_thread, NULL ); pthread_join (consumer_thread, NULL ); pthread_mutex_destroy (&mutex); pthread_cond_destroy (&cond); return 0 ; }
执行流程:
生产者线程执行(producer 函数)
进入循环 :生产者线程不断地执行生产过程。模拟生产 :每次生产数据前,调用sleep(1)模拟生产需要的时间,暂停1秒。获取互斥锁 :使用pthread_mutex_lock(&mutex)获取互斥锁,确保缓冲区的访问是安全的。缓冲区已满:如果缓冲区已满(buffer == BUFFER_SIZE),生产者线程会进入while循环,调用pthread_cond_wait(&cond, &mutex)等待消费者消费数据。
在pthread_cond_wait时,生产者线程会自动释放mutex锁,并阻塞,直到消费者线程调用pthread_cond_signal来唤醒生产者。
生产数据 :生产者将buffer设为1,表示缓冲区有数据可以消费。通知消费者 :生产者通过调用pthread_cond_signal(&cond)来唤醒消费者线程,通知消费者有数据可以消费了。释放互斥锁 :生产者线程通过pthread_mutex_unlock(&mutex)释放互斥锁,允许其他线程访问缓冲区。
消费者线程执行(consumer 函数)
进入循环 :消费者线程不断地执行消费过程。模拟消费 :每次消费数据前,调用sleep(2)模拟消费过程中的等待时间,暂停2秒。获取互斥锁 :使用pthread_mutex_lock(&mutex)获取互斥锁,确保缓冲区的访问是互斥的。缓冲区为空:如果缓冲区为空(buffer == 0),消费者线程会进入while循环,调用pthread_cond_wait(&cond, &mutex)等待生产者生产数据。
在pthread_cond_wait时,消费者线程会自动释放mutex锁,并阻塞,直到生产者线程通过调用pthread_cond_signal唤醒消费者。
消费数据 :消费者将buffer设为0,表示缓冲区已经被消费。通知生产者 :消费者通过调用pthread_cond_signal(&cond)来唤醒生产者线程,通知生产者可以继续生产数据了。释放互斥锁 :消费者线程通过pthread_mutex_unlock(&mutex)释放互斥锁,允许其他线程访问缓冲区。
注意, 当条件变量收到信号 pthread_cond_signal 会先重新尝试获取互斥锁。也就是说,当条件满足后,线程会再次尝试获得互斥锁,并在成功获得锁后才会继续执行后续的代码。
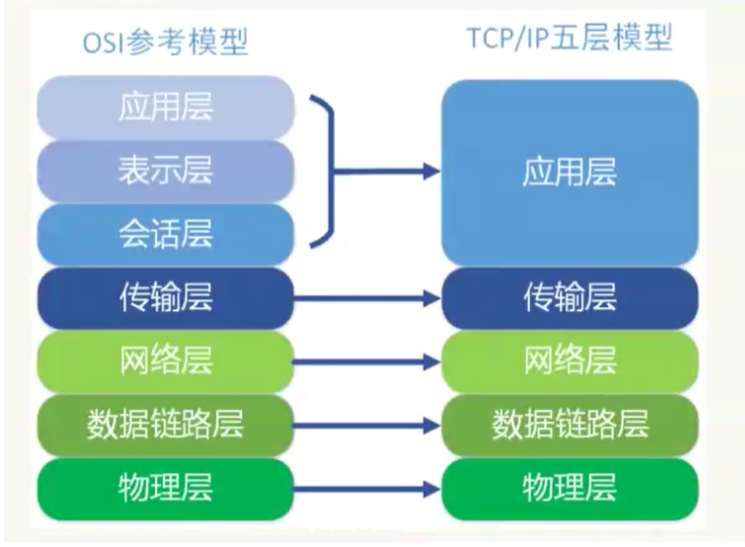
网络前置知识: 网络模型
物理层理解为网卡驱动,链路层是让数据在局域网传播,网络层让数据满世界传输,传输层理解为决定是打电话还是发短信这样的,会话层类似于QQ的在线与否,表示层类似于中文还是英文,应用层表示是类似网页还是视频…
物理层:是指实际传输数据的硬件和信号机制,例如电缆、光纤、无线信号、连接器等。
链路层:它负责节点之间(直接相连的设备)数据帧的可靠传输。它解决了物理层可能出现的错误,比如比特翻转,并通过 MAC 地址(硬件地址)来定位同一链路上的设备。
网络层: 网络层通过 IP 地址实现设备的全局定位,确保数据包能够跨越多个子网传输到目标设备。可以理解为从发件人地址到收件人地址,确保快递包裹送达。最常见的协议是 IP(如 IPv4 和 IPv6)。
传输层: 决定是打电话还是发短信,TCP :类似“打电话”,需要确认接收方在场、内容完整,建立可靠连接。 UDP :类似“发短信”,无需确认对方是否收到,快速但不可靠。
应用层 :应用层直接面向用户,为用户提供各种服务,比如 HTTP(网页)、FTP(文件传输)、SMTP(邮件)等。它相当于决定了数据的“用处”,比如浏览网页、看视频或发邮件。
具体来说,如果要把数据通过互联网传递到另一台主机,五层模型分别做了什么?
应用层: 你在浏览器中输入 URL 并按下回车键,应用层负责生成 HTTP 请求报文(比如 GET /index.html HTTP/1.1)。
传输层: 如果你使用 HTTP 协议,传输层可能选择 TCP 协议,负责为数据添加目标端口号(如 80)和序列号。
网络层 : 网络层为数据包添加了你的主机 IP 地址(如 192.168.1.100)和目标主机 IP 地址(如 8.8.8.8)。
数据链路层: 数据链路层将你的网卡的 MAC 地址(如 00:11:22:33:44:55)和默认网关的 MAC 地址添加到帧中。
物理层 : 数据通过网线以电信号的形式发送到路由器或交换机。
Ipv4和Mac地址:
特性
IPv4地址
MAC地址
协议层
网络层
数据链路层
作用
标识网络中的设备,主要用于路由
标识局域网中网络接口的硬件地址
范围
可以跨越多个网络(全局可见)
仅在同一个局域网(本地可见)使用
可变性
动态分配(通过DHCP或者手动设置)
静态(网卡烧录,可以伪造)
为什么局域网通信需要 MAC 地址 ?
局域网中设备通信通常是通过 以太网协议(Ethernet) 实现的,而以太网协议运行在 数据链路层。数据链路层的核心是通过 MAC 地址 标识设备。
以太网相对底层,而Ipv4是动态的,MAC是静态的,所以用MAC地址进行局域网通讯没问题,IPV4主要是设备间通讯的
以太网: 是一种使用有线连接的局域网(LAN)通信技术 , 以太网通过物理线缆将设备连接到网络交换机或路由器,提供稳定和高带宽的网络通信。
以太网帧(Ethernet Frame)是局域网(LAN)中数据传输的基本单元,遵循以太网协议,通常按照IEEE 802.3标准进行封装。
帧头(Header) :
目的地址(Destination Address) :6字节,表示数据帧的接收方MAC地址。源地址(Source Address) :6字节,表示数据帧的发送方MAC地址。类型(Type) :2字节,表示上层协议类型,如0x0800表示IP协议。
数据负载(Payload) :
这是实际传输的数据部分,长度可以是46到1500字节。如果数据部分小于46字节,通常会用填充(padding)来补足到46字节。
帧校验序列(Frame Check Sequence, FCS) :
4字节,用于错误检测。在发送端计算整个帧(包括帧头和数据负载)的CRC(循环冗余校验)值,并附加在帧的末尾。接收端会重新计算接收到的帧的CRC值,并与接收到的FCS进行比较,以验证数据的完整性。
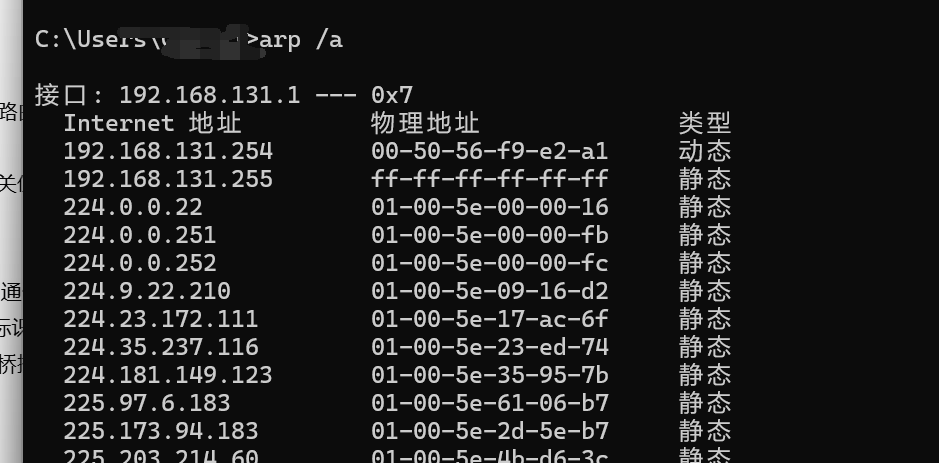
ARP地址解析协议 ARP(Address Resolution Protocol,地址解析协议)是一种网络层协议,用于将网络层的IP地址解析为数据链路层的MAC地址。 通俗来说,就是为了不同机器之间找目标机器的网卡MAC地址进行通讯
具体可以在WireShark进行抓包,发现会向全部端口发送信号,询问某个IPv4地址属于来自哪个网卡,只要有回应,就会做成一张表,记录对应的IP和MAC地址
子网,子网掩码,网关 子网(Subnetwork)是网络的一个子集,它由一个较大的网络划分而成,通常用于提高网络性能、增强安全性、优化广播域和路由效率。 通过创建子网,可以限制广播流量只在子网内部传播,而不是在整个大网络中,这有助于减少网络拥塞和提高效率。
子网掩码是例如255.255.255.0这样的,将它和任意IP地址异或,可以获得子网的基地址
网关的作用:
局域网内通信 :同一子网内的设备可以直接通信,无需经过网关。跨子网通信 :当两个设备属于不同子网时,需要通过网关进行数据的转发。访问外网 :当设备需要与互联网通信时,数据会发送到网关,由网关转发到外部网络。
跨子网通信(需要网关)
场景 :设备 A(192.168.1.10)想与设备 C(192.168.2.10)通信,它们在不同子网:
A 的子网:192.168.1.0/24。
C 的子网:192.168.2.0/24。
网关地址:192.168.1.1(A 的默认网关)。
过程 :
A 检查目标地址 C 是否在同一子网:
A 的网络部分:192.168.1。
C 的网络部分:192.168.2。
结果:不在同一子网。
A 将数据包发送到网关(192.168.1.1):
A 通过 ARP 协议获取网关的 MAC 地址。
数据包的目标 MAC 地址设为网关的 MAC,目标 IP 地址保持为 C 的 IP。
网关接收数据包,检查目标 IP 地址(C 的 IP),发现它不在自己的子网内。
网关根据路由表决定如何将数据转发到 C 所在的子网:
如果网关与 C 在同一子网,直接转发。
如果不在,则继续向上游网关转发,直到数据到达目标子网。
数据到达 C。
VMWare的桥接和NAT的区别 桥接 的原理相当于是在局域网内加了一台和本机地位一样的机器,例如本机的IP地址是192.168.6.90,那么桥接出来的机器,IP地址可能是192.168.6.88,可以理解为这两个机器都平等地接在一个交换机上
NAT 的话是通过一个NAT设备进行地址转换,所以相当于本机是一个服务端(IP地址假设为192.168.6.90),然后接了一个NAT盒子IP地址是192.168.132.1,然后虚拟机192.168.132.128接在这个NAT盒子上。这样就是虚拟机可以访问外网,但是从外面找不到虚拟机
如果路由器坏了,桥接模式之间就不能进行通讯了,但是NAT可以
TCP协议 特点:
面向连接(有连接) :
TCP是一个面向连接的协议,这意味着在数据传输开始之前,必须在通信的两个端点之间建立一个连接。这个过程称为三次握手,确保了双方都能发送和接收数据。
可靠 :
TCP通过使用序列号、确认应答(ACK)、重传机制和数据校验和来确保数据的可靠传输。如果数据包在传输过程中丢失或损坏,TCP会请求重传丢失的数据包,并重新组装数据以确保正确无误。
有序 :
TCP保证数据包按照发送的顺序到达接收端。即使在网络中数据包可能乱序到达,TCP也会在接收端对数据包进行排序,确保应用程序接收到的数据是有序的。
端到端 :
TCP提供端到端的通信,这意味着它负责在发送端和接收端之间建立和管理连接,而不需要中间网络设备(如路由器)参与数据传输的控制。
全双工 :
TCP允许数据在两个方向上同时传输,即发送方和接收方都可以同时发送和接收数据。这种全双工通信模式提高了网络的效率。
流量控制 :
TCP通过流量控制机制(如滑动窗口协议)来防止发送方发送数据过快,导致接收方来不及处理。这有助于避免网络拥塞和数据丢失。
拥塞控制 :
TCP还实现了拥塞控制算法(如慢启动、拥塞避免、快速重传和快速恢复),以适应网络条件的变化,减少网络拥塞的影响。
错误检测 :
TCP使用校验和来检测数据在传输过程中是否发生错误。如果检测到错误,TCP会请求重传损坏的数据包。
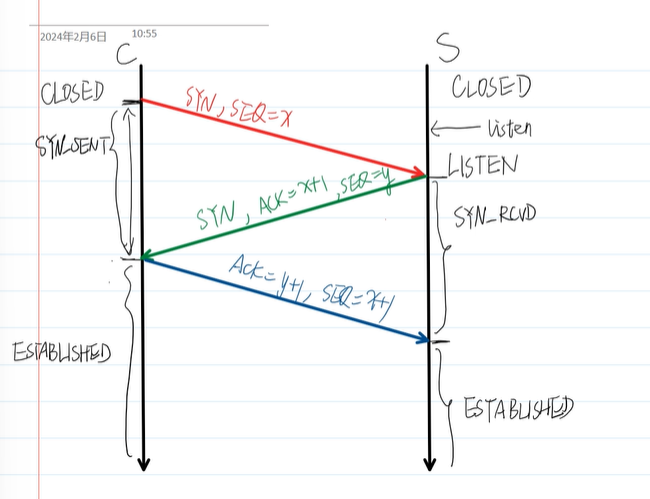
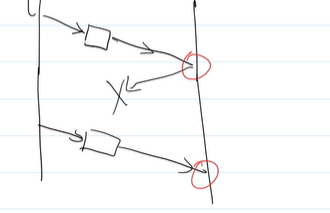
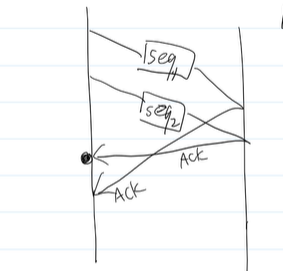
四次握手->三次握手
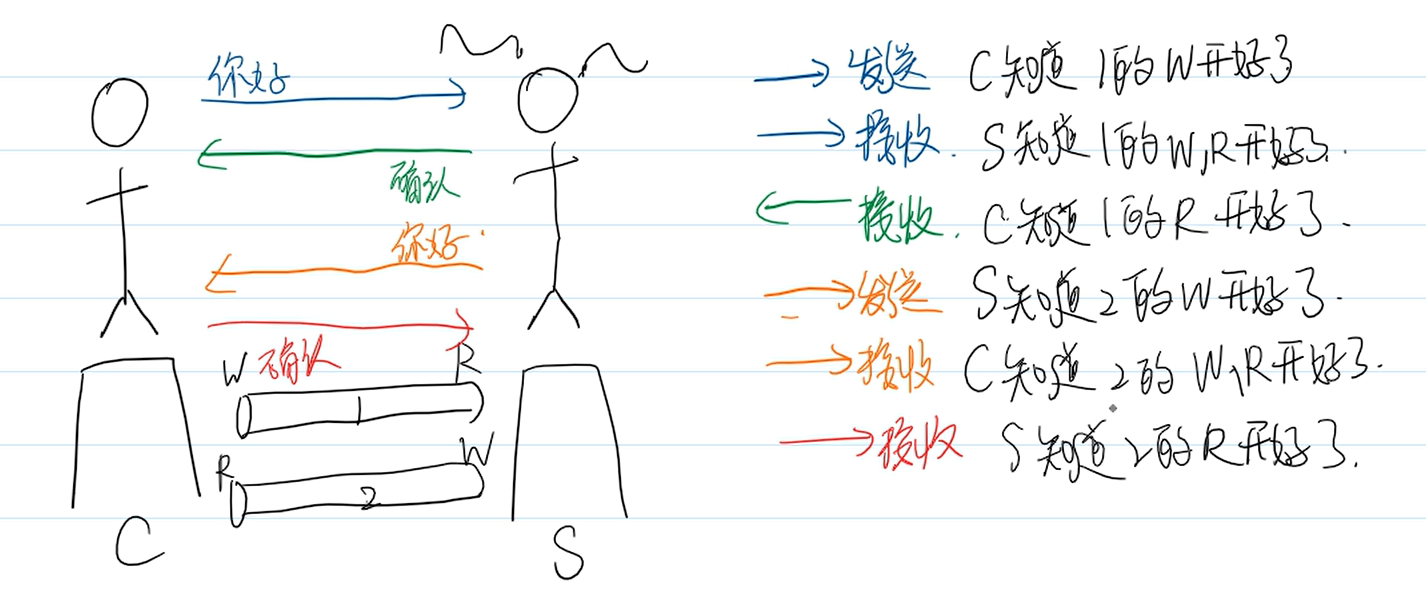
如上图,阿强是Client,阿珍是Server端,两个人要建立通讯,也就是C和S端都要确保管道1,2的读写端都开启
首先C向S发送一条“你好”的信息,这样可以C知道管道1的W端已经开放
然后S端收到来自C端的信息,这样S端可以知道管道1的W,R已经开启
接着S端向C端发送 确认 的信息,这样C端就知道管道1的R开好了
接下来是S端向C端发送一个”你好”的请求,这样S端知道了管道2的W开好了
C端接收到了S端的信息,这样C端就知道了管道2的R,W端都开好了
于是C端返回一个“确认”给S端,S端接收到以后,S端就知道管道2的R开好了
至此,C和S都知道了管道1 2的W R都开放了,就可以开始通讯了
以上是四次握手
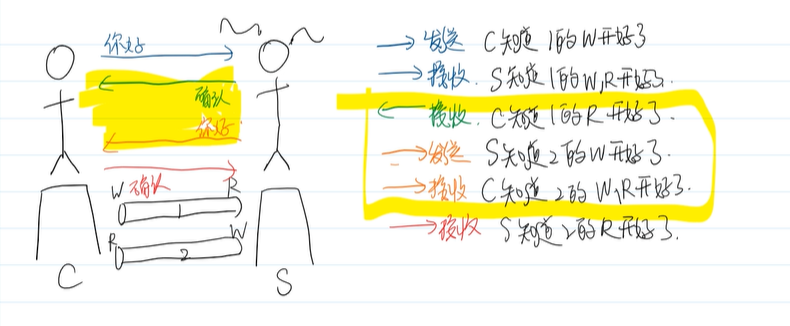
但是我们从网上查到的是三次握手啊??
这是因为,S端发送确认和你好,C端接收 其实应该是在同一次完成的
(这里要注意下建立连接不走管道),所以是三次握手
简化来说就是这样:
三次握手的状态变化:
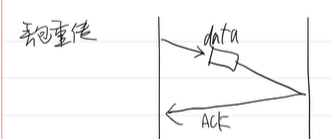
可靠性的实现 丢包重传:
客户端发出去一个包,服务器要回复一个ACK(表示收到),如果一定时间内没收到ACK,客户端会重新发包
但是服务端没发ACK又有两种情况,一种是服务端收到消息了,但是ACK发不出去,另一种是没收到,那么这个如何解决呢?
TCP引入了序号机制,让接收方区分是新包还是重传包,还解决了有序性
另外一个个包等待接收到才继续发效率太低了,一般都是先不管确认,直接发的,所以ACK也要带上序号信息
当然不确认发信息是有风险的,所以TCP有一个已发未确认是有上限的
三次握手的状态变化
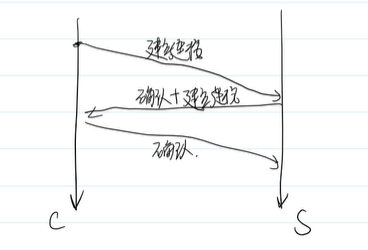
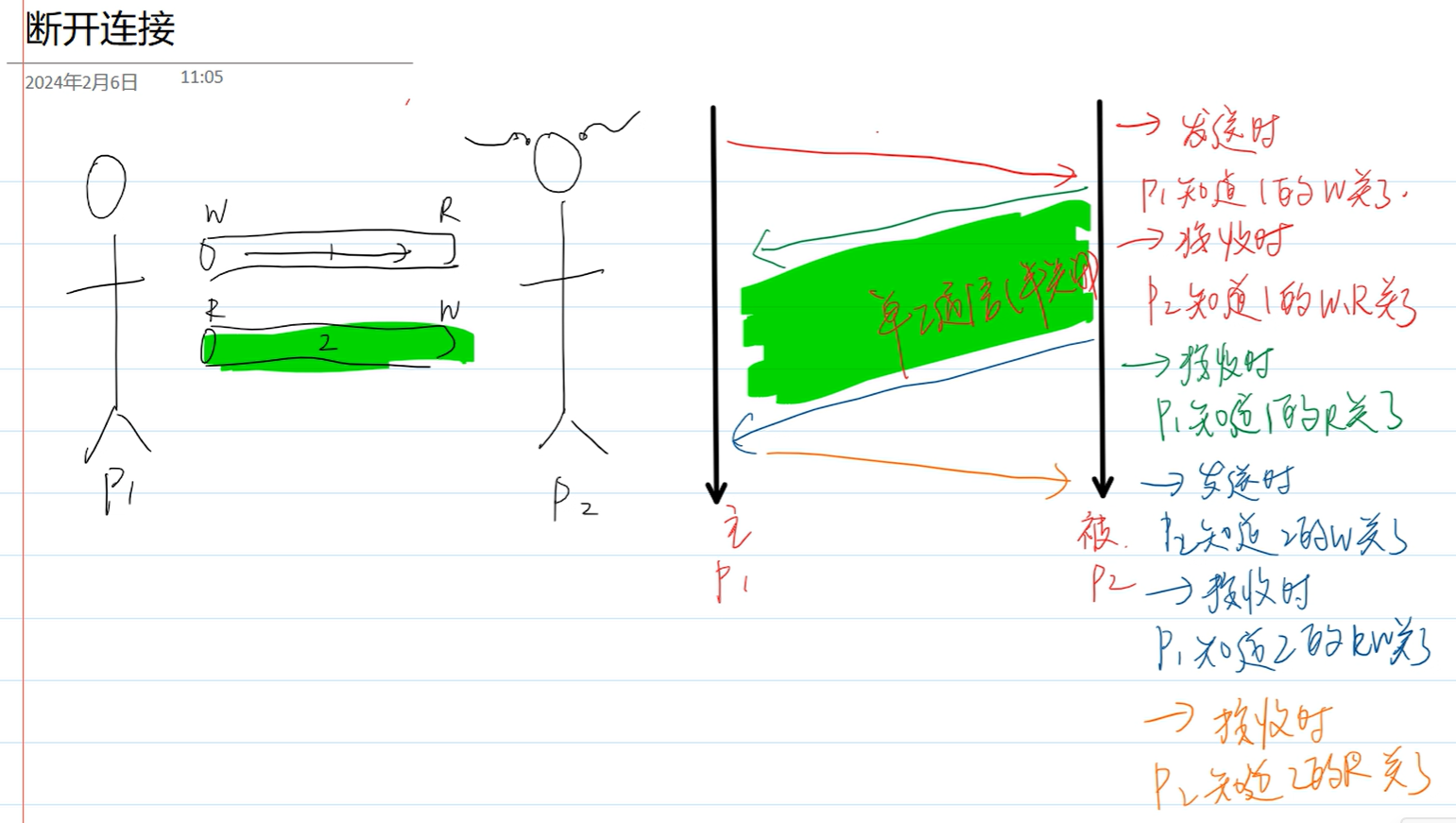
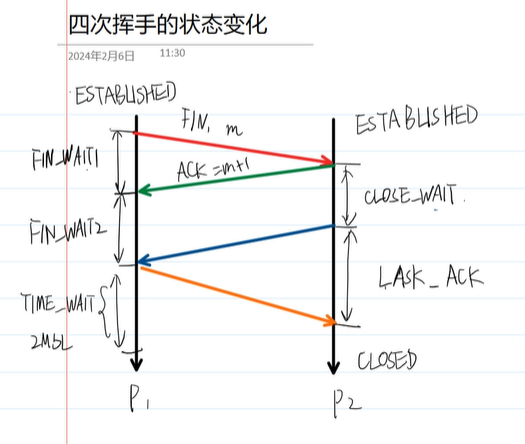
四次挥手 断开连接 时,双方的发送数据和接收数据是完全独立的过程 。一方停止发送数据,并不意味着另一方也同时完成了数据发送。因此,双方需要分别关闭发送方向:
过程是这样的,如上图
p1发送给P2一个关闭的信号
发送时,P1知道了管道1的W关了
接收时,P2知道管道1的WR关了
P2给P1发送一个收到的信息
发送时,P2知道管道1的WR关了
接收时,P1知道管道1的WR关了
至于为什么要分开,可以这么理解,一个人不得给另一个人写点小作文😂(也就是还有数据要传输)
所以还有单向的数据需要传输,所以不能合并
结束以后P2再给P1发送关闭的信息
发送时,P2知道管道2的W关了
接收时,P1知道管道2的WR关了
P1再给P2发送一个收到的信息
发送时,P1知道管道2的WR关了
接收时,P2知道管道2的WR关了
至此,结束
四次挥手的状态变化:
FIN:是断开连接的请求
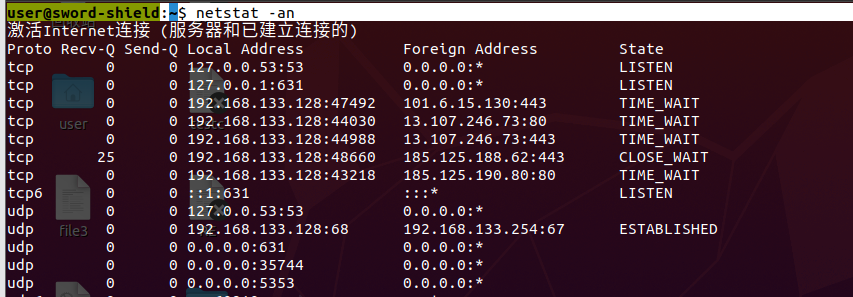
查看TCP连接 1 user@sword-shield:~$ netstat -an
State有以下几种状态:
ESTABLISHED 状态表示两端之间的三次握手已经完成,连接进入可用状态,可以发送和接收数据。
LISTEN : 表示服务器端在等待连接请求。对方发来建立连接的请求,此时服务端必须在处于LISTEN的状态
SYN_SENT / SYN_RECV : 表示三次握手的中间状态。
TIME_WAIT : 表示连接已经关闭,但系统等待确保远程端接收到最后的ACK。
CLOSE_WAIT : 表示连接已被远端关闭,本地仍需要完成关闭操作。
TCP协议重要字段: URG (Urgent)
描述 : 表示当前数据段包含紧急数据。
作用 :
紧急数据需要优先处理,而无需等待接收方的缓冲队列。
紧急指针 字段指示紧急数据在TCP数据段中的结束位置。
RST (Reset) :
TCP报文头中的一个标志位,用于强制终止连接。
当一方收到一个无法识别的包或认为连接出错时,会发送一个带有RST标志的包通知对方立即终止连接。
SYN (Synchronize)
描述 : TCP报文头中的一个标志位,用于发起连接请求(同步序列号)。
作用 : 用于三次握手中的第一步,通知对方要建立连接并同步序列号。
**ACK (Acknowledgment) **
描述 : TCP报文头中的一个标志位,表示对收到数据的确认。
作用 : 用于确认接收到的数据包。每个TCP报文都会包含ACK以指明收到的最后一个字节的序列号。
**SEQ (Sequence Number) **
描述 : TCP报文头中的一个字段,表示数据包中的字节序列号。
作用 : 用于标记当前报文中的数据在整个数据流中的位置,保证数据的有序性和完整性。
PSH (Push)
描述 : 提示接收方尽快将当前数据推送到上层应用。
通知接收方不再等待更多数据,立即处理本段数据。
通常用于实时性要求较高的场景。
UDP协议
TCP 和 UDP 是不同的协议,它们各自有独立的端口号空间 。尽管同一台机器上使用相同的端口号(如 80),但 TCP 和 UDP 的服务互不干扰。
本机地址和本地环回地址 127.0.0.1 是回环地址(loopback address),始终指向本机,且不依赖任何物理网络设备。
192.168.xxx.xxx 是本机在局域网 (LAN) 中的 IP 地址,是分配给本地网络接口的有效地址。
区别是
特性
127.0.0.1
192.168.xxx.xxx
地址类型
回环地址,只能用于本机
局域网地址,可以与其他设备进行通讯
是否需要网络支持
不需要,完全本地化
需要,以来网络接口和配置
通信范围
仅限本机
本机和局域网其他设备
速度
高速,直接本地处理
取决于网络宽带和延迟
测试用途
常用于测试本地服务
用于验证设备间或者服务间的连接
使用 192.168.xxx.xxx 在本机和本机通讯时,通信数据会经过网卡 等设备,绕一圈再回到本机,相比于127.0.0.1确实慢不少
Linux下的网络编程 ip地址结构和字节序 在Linux找对应结构体:
因为Linux是一个开源的操作系统,所有头文件都放在了/user/include这个文件夹,我做的是把这玩意拖出来放到windows端,然后把文件夹扔到vscode里面,这时候就可以通过符号进行查找结构体
这是Ipv4的具体类型
1 2 3 4 5 6 7 8 9 10 11 struct sockaddr_in { __kernel_sa_family_t sin_family; __be16 sin_port; struct in_addr sin_addr; struct in_addr { __be32 s_addr; };
这是IPV6的具体类型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 struct sockaddr_in6 { unsigned short int sin6_family; __be16 sin6_port; __be32 sin6_flowinfo; struct in6_addr sin6_addr; __u32 sin6_scope_id; }; #if __UAPI_DEF_IN6_ADDR struct in6_addr { union { __u8 u6_addr8[16 ]; #if __UAPI_DEF_IN6_ADDR_ALT __be16 u6_addr16[8 ]; __be32 u6_addr32[4 ]; #endif } in6_u;
IP类型那么多,有没有办法统一?不然代码要一直重写?
struct sockaddr 是一个统一的类型,它在网络编程中作为一个通用的套接字地址结构,允许在不同的地址族(如 IPv4、IPv6 等)中共享一个统一的接口。 可以看到struct sockaddr用的是IPV4和IPV6的公共部分
1 2 3 4 struct sockaddr { __SOCKADDR_COMMON (sa_); char sa_data[14 ]; };
**__SOCKADDR_COMMON (sa_)**: 这是一个宏,它定义了与地址族相关的共同字段。通常,这些字段包括:
sa_family:地址族,通常是 AF_INET(IPv4)或 AF_INET6(IPv6),表示地址类型。sa_len:这个字段在某些系统上(如 BSD 系列)用于表示地址结构的长度。它是为了确保传递地址时不会发生缓冲区溢出的问题。
**char sa_data[14];**: 这是一个固定大小的字符数组,用于存储地址族特定的地址信息。具体内容取决于地址族的类型。
对于 IPv4,sa_data 会包含 4 字节的 IP 地址和 2 字节的端口号。
对于 IPv6,sa_data 会包含 16 字节的 IP 地址和 2 字节的端口号。
大小端转换
在网络设备都是大端序,在主机设备是小端序
大小端转换是为了保持真值不变
相关函数:
htons : Host TO Network Short。 将 16位短整型数(short) 从主机字节序转换为网络字节序。
ntohs : Network TO Host Short。 将 16位短整型数(short) 从网络字节序转换为主机字节序。
htonl : Host TO Network Long。 功能 :将 32位长整型数(long) 从主机字节序转换为网络字节序。
ntohl : Network TO Host Long。 功能 :将 32位长整型数(long) 从网络字节序转换为主机字节序。
inet_addr : 功能 :将 字符串格式的IPv4地址 转换为 网络字节序的整数值(uint32_t) 。
inet_ntoa : 功能 :将 网络字节序的IPv4地址 转换为 字符串格式的IPv4地址 。
inet_ntop : 功能 :将 网络字节序的二进制格式的IP地址 转换为 字符串格式 。
inet_pton :功能 :将 字符串格式 转换为 网络字节序的二进制格式的IP地址 。
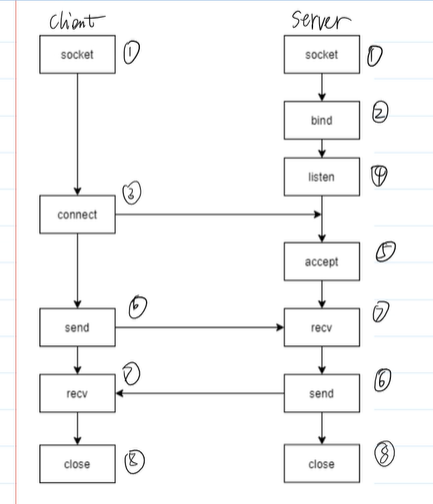
TCP编程过程 TCP的底层操作系统已经帮我们实现了,我们只需要在应用层做动作就行
这图有点瑕疵,3和4顺序要反过来
重要函数 getThostbyname
gethostbyname 函数
将主机名(如域名 www.google.com)解析为对应的IP地址。
使用DNS协议,根据域名获取IP,这个API断网不能用
1 2 #include <netdb.h> struct hostent *gethostbyname (const char *name);
1 2 3 4 5 6 7 struct hostent { char *h_name; char **h_aliases; int h_addrtype; int h_length; char **h_addr_list; };
可以获取一个主机名的所有域名,还有所有IP地址
socket :套接字,理解为 IP+端口
1 2 #include <sys/socket.h> int socket (int domain, int type, int protocol)
**domain (协议族)**: 指定通信的地址族或协议族。
常用选项 :
AF_INET: 用于 IPv4 网络。AF_INET6: 用于 IPv6 网络。AF_UNIX (或 AF_LOCAL): 用于本地套接字(文件系统中的套接字文件)。AF_PACKET: 用于低级别访问网络接口(数据链路层)。
作用 :决定套接字的地址格式和通信域。
**type (套接字类型)**: 指定套接字的类型,决定通信的特性。(传输层)
常用选项:
SOCK_STREAM: 提供可靠的、面向连接的通信(如 TCP)。SOCK_DGRAM: 提供无连接的、不可靠的通信(如 UDP)。SOCK_RAW: 允许直接操作 IP 数据报(需要超级用户权限)。
作用 :定义数据传输的方式。
**protocol (协议)**: 指定具体的协议,一般设为 0 让系统自动选择默认协议。
常用选项:
IPPROTO_TCP: TCP 协议(仅适用于 SOCK_STREAM)。IPPROTO_UDP: UDP 协议(仅适用于 SOCK_DGRAM)。IPPROTO_ICMP: ICMP 协议(常用于 SOCK_RAW)。
作用 :决定传输协议。如果只有一种协议与所选的 type 和 domain 匹配,可以使用 0。
返回值
成功:返回一个文件描述符(非负整数),表示新创建的套接字。
失败:返回 -1,并设置 errno 以指示错误类型。
创建出来的socket,自带读写两个管道
服务端需要暴露出IP和端口,客户端不用,所以服务端必须bind,客户端可以bind,不推荐
因为客户端不bind可以无视TIME_WAIT ,在 TCP 协议中,当一方主动关闭连接时,连接会进入 TIME_WAIT 状态。 如果客户端不调用 bind(),操作系统会为套接字分配一个临时端口(ephemeral port)。 如果连接关闭,且临时端口进入了 TIME_WAIT 状态,系统会避免分配到同一个端口,而是选择新的临时端口。
bind函数
1 2 3 #include <sys/types.h> #include <sys/socket.h> int bind (int sockfd, const struct sockaddr *addr, socklen_t addrlen)
功能:
将指定的 IP 地址和端口绑定到套接字。
常用于服务器程序,绑定特定的网络接口和端口以接收客户端的连接请求。
addr
指向 struct sockaddr
对于 IPv4 通信,通常是 struct sockaddr_in,通过强制转换为 struct sockaddr *。(注意要强制转换,配合长度让Bind知道是什么类型)
connect函数
客户端调用,建立连接
1 int connect (int sockfd, const struct sockaddr *addr, socklen_t addrlen)
功能:
主动发起连接到指定的服务器(远程主机)。
用于客户端程序,建立到服务器的连接。
listen函数
在 Linux 网络编程中,listen 函数是一个用于在服务器端设置待接收连接的函数,通常在创建套接字后使用。它的主要作用是将一个套接字设置为被动监听状态,等待客户端连接。
调用listen以后,这个socket只能用来建立连接
1 int listen (int sockfd, int backlog)
参数说明
sockfd :是之前通过 socket() 系统调用创建的套接字描述符,它用于标识该套接字。backlog :定义了可以排队等待连接的最大数量。如果有多个客户端尝试连接服务器,且服务器的接受队列已满,连接请求会被拒绝或被丢弃。通常值设置为一个合理的整数,常见的设置是 5 或 10,具体数值依赖于应用的需求。
listen这个函数比较复杂:
进入listen后,它会重建内部的数据结构, 销毁 SND 和 RCV 缓冲区 , 创建半连接队列和全连接队列
listen() 后的处理过程
当服务器调用 listen() 后,服务器的监听套接字进入了被动监听模式。此时,套接字不再用于主动发送和接收数据,而是进入了连接管理模式,专门用于等待客户端的连接请求。SND 和 RCV 缓冲区被销毁,替换为用于连接管理的队列(半连接队列和全连接队列)。
第一次握手 (客户端发送 SYN):
此时,服务器的监听套接字接收到这个连接请求,但并没有直接与客户端交换数据。此时服务器没有数据缓冲区 (没有 SND 和 RCV 缓冲区),但是服务器的内核会在监听套接字的 半连接队列 中暂存这个连接请求。
第二次握手 (服务器发送 SYN-ACK):
服务器收到客户端的 SYN 包后,服务器会向客户端发送一个 SYN-ACK 包,表示愿意接受连接,并等待客户端的确认。此时服务器确实没有用到传统的 SND 和 RCV 缓冲区 ,但它会使用操作系统内核中的 网络栈 来处理这些控制包的发送和接收。
第三次握手 (客户端发送 ACK):
客户端收到 SYN-ACK 后,会向服务器发送一个 ACK 包,表示连接建立完成。这时,客户端和服务器的连接正式建立,服务器会从 半连接队列 中移除这个连接,并将它移到 全连接队列 中,等待服务器应用程序通过 accept() 来接受这个连接。
一旦连接建立,操作系统会为该连接分配一个新的套接字(已经拥有 SND 和 RCV 缓冲区 ),并开始为该套接字分配数据缓冲区,用于数据传输。
accept
我们知道,之前由于调用listen,socket的SND,RCV缓冲区已经被删除掉了,建立好连接后,我们应该需要重建SND和RCV这俩管道发送信息
accept 是一个用于服务器程序的系统调用,它从服务器的 全连接队列 中取出一个已经完成三次握手的连接,并返回一个新的套接字(用于与客户端通信)。这个新的套接字与原来的监听套接字是分开的,新的套接字专用于和该客户端的数据通信,而监听套接字仍然负责监听新的连接请求。
此时新的套接字就拥有SND和RCV 缓冲区
1 2 3 4 #include <sys/types.h> #include <sys/socket.h> int accept (int sockfd, struct sockaddr *addr, socklen_t *addrlen)
参数说明
sockfd
一个已经调用了 socket() 和 bind() 并设置了监听状态的套接字描述符。
它是服务器的监听套接字。
addr
用于存储客户端的地址信息。
是一个指向 sockaddr 结构的指针,可以通过它获取客户端的 IP 地址和端口号。
如果你不关心客户端的地址信息,可以传 NULL。
addrlen
是一个指向 socklen_t 类型变量的指针,表示 addr 的大小。
函数返回时,它会被设置为实际的地址长度。
如果 addr 为 NULL,可以将 addrlen 也设置为 NULL。
addrlen这个参数有点奇葩,这玩意一开始指向的值不能为空,得是可能的长度最大值 ,另外addr和addrlen全都是NULL,否则都要填写。
如下面的代码,listen是一个持续的过程,accept是阻塞的过程 ,**listen()** 看作是让服务器的套接字进入监听状态,而 accept()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <string.h> #include <sys/socket.h> #include <arpa/inet.h> #define PORT 8080 int main () int server_fd, new_socket; struct sockaddr_in address; int addrlen = sizeof (address); if ((server_fd = socket (AF_INET, SOCK_STREAM, 0 )) == 0 ) { perror ("socket failed" ); exit (EXIT_FAILURE); } address.sin_family = AF_INET; address.sin_addr.s_addr = INADDR_ANY; address.sin_port = htons (PORT); if (bind (server_fd, (struct sockaddr *)&address, sizeof (address)) < 0 ) { perror ("bind failed" ); exit (EXIT_FAILURE); } if (listen (server_fd, 3 ) < 0 ) { perror ("listen failed" ); exit (EXIT_FAILURE); } printf ("Waiting for connections...\n" ); while (1 ) { if ((new_socket = accept (server_fd, (struct sockaddr *)&address, (socklen_t *)&addrlen)) < 0 ) { perror ("accept failed" ); exit (EXIT_FAILURE); } printf ("New connection accepted\n" ); char *message = "Hello from server!" ; send (new_socket, message, strlen (message), 0 ); close (new_socket); } return 0 ; }
send函数
send函数的作用并不是发送,而是将数据拷贝到SND缓冲区,真正发送由内核协议栈发送,send的功能类似write,甚至功能更弱
1 2 3 4 #include <sys/types.h> #include <sys/socket.h> ssize_t send (int sockfd, const void *buf, size_t len, int flags)
参数说明
**sockfd**:
已经建立连接的套接字描述符。
由 socket() 创建并通过 connect()(客户端)或 accept()(服务端)建立连接。
**buf**:
**len**:
**flags**:
指定数据传输的选项,常用值:
0:普通模式。MSG_DONTWAIT:非阻塞发送。MSG_OOB:发送紧急数据。MSG_NOSIGNAL:避免向断开的连接发送信号(防止进程崩溃)。
返回值
成功:
失败:
返回 -1,设置 errno 指示错误原因(如连接断开、套接字非阻塞等)。
recv 函数
作用不是接收,而是将数据从内核缓冲区拷贝到用户态的buf
1 2 3 4 #include <sys/types.h> #include <sys/socket.h> ssize_t recv (int sockfd, void *buf, size_t len, int flags)
参数说明
**sockfd**:
已经建立连接的套接字描述符。
数据从这个套接字接收。
**buf**:
**len**:
**flags**:
指定数据接收的选项,常用值:
0:普通模式。MSG_PEEK:查看数据但不移除(数据仍然留在接收缓冲区)。MSG_WAITALL:阻塞直到接收到指定长度的数据。MSG_DONTWAIT:非阻塞接收。
返回值
成功:
返回实际接收到的字节数。
如果返回 0,表示连接被对方关闭。
失败:
select函数
函数原型:
1 2 3 4 #include <sys/select.h> #include <unistd.h> int select (int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout)
nfdsint 说明:这是文件描述符的范围,应该设置为你关注的最大文件描述符加 1(即 max_fd + 1)。
readfdsfd_set 类型的结构体,select() 会检查这些文件描述符是否有可读事件发生(例如,套接字是否有数据可以读取)。
writefdsfd_set 类型的结构体,select() 会检查这些文件描述符是否有可写事件(例如,套接字是否可写入数据)。
exceptfdsfd_set 类型的结构体,select() 会检查这些文件描述符是否有异常事件(例如,网络连接是否断开,或者套接字上是否有错误发生)。
timeouttimeout 是一个 struct timeval 结构体,表示等待事件发生的最大时间。如果指定为 NULL,select() 将会无限期地等待,直到某个文件描述符准备好。否则,select() 将会在指定的时间内等待事件发生,超时则返回。
如果服务端同时受理多个客户端,且没有开启多线程,那么就会有一个很尬的问题,你得一直轮询查看哪个端口来数据了,就像这样:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 for (int i = 0 ; i < max_clients; i++) { if (client_sockets[i] > 0 ) { char buffer[1024 ] = {0 }; int valread = recv (client_sockets[i], buffer, sizeof (buffer), MSG_DONTWAIT); if (valread > 0 ) { printf ("Received from client %d: %s\n" , i, buffer); char *response = "Message received" ; send (client_sockets[i], response, strlen (response), 0 ); } else if (valread == 0 ) { printf ("Client %d disconnected\n" , i); close (client_sockets[i]); client_sockets[i] = 0 ; } } } usleep (10000 ); }
但是如果用了select, 就可以使用 select 实现多客户端管理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <string.h> #include <sys/socket.h> #include <arpa/inet.h> #include <sys/select.h> #define PORT 8080 #define MAX_CLIENTS 10 int main () int server_fd, new_socket, client_sockets[MAX_CLIENTS], max_clients = MAX_CLIENTS, max_sd; struct sockaddr_in address; int addrlen = sizeof (address); fd_set readfds; if ((server_fd = socket (AF_INET, SOCK_STREAM, 0 )) == 0 ) { perror ("socket failed" ); exit (EXIT_FAILURE); } address.sin_family = AF_INET; address.sin_addr.s_addr = INADDR_ANY; address.sin_port = htons (PORT); if (bind (server_fd, (struct sockaddr *)&address, sizeof (address)) < 0 ) { perror ("bind failed" ); exit (EXIT_FAILURE); } if (listen (server_fd, 3 ) < 0 ) { perror ("listen failed" ); exit (EXIT_FAILURE); } printf ("Waiting for connections...\n" ); for (int i = 0 ; i < max_clients; i++) { client_sockets[i] = 0 ; } while (1 ) { FD_ZERO (&readfds); FD_SET (server_fd, &readfds); max_sd = server_fd; for (int i = 0 ; i < max_clients; i++) { int sd = client_sockets[i]; if (sd > 0 ) { FD_SET (sd, &readfds); } if (sd > max_sd) { max_sd = sd; } } int activity = select (max_sd + 1 , &readfds, NULL , NULL , NULL ); if (activity < 0 ) { perror ("select error" ); exit (EXIT_FAILURE); } if (FD_ISSET (server_fd, &readfds)) { if ((new_socket = accept (server_fd, (struct sockaddr *)&address, (socklen_t *)&addrlen)) < 0 ) { perror ("accept failed" ); exit (EXIT_FAILURE); } printf ("New connection accepted\n" ); for (int i = 0 ; i < max_clients; i++) { if (client_sockets[i] == 0 ) { client_sockets[i] = new_socket; printf ("Adding new client to slot %d\n" , i); break ; } } } for (int i = 0 ; i < max_clients; i++) { int sd = client_sockets[i]; if (FD_ISSET (sd, &readfds)) { char buffer[1024 ] = {0 }; int valread = recv (sd, buffer, sizeof (buffer), 0 ); if (valread > 0 ) { printf ("Received from client %d: %s\n" , i, buffer); char *response = "Message received" ; send (sd, response, strlen (response), 0 ); } else if (valread == 0 ) { printf ("Client %d disconnected\n" , i); close (sd); client_sockets[i] = 0 ; } } } } return 0 ; }
与 select 相关的宏
FD_ISSET
1 int FD_ISSET (int fd, fd_set *set)
参数 :
fd:要检查的文件描述符。
set:一个 fd_set 类型的集合,通常由 select 或 pselect 填充。它包含了多个文件描述符。
返回值 :
如果文件描述符 fd 在集合 set 中处于活动状态(即有事件发生,如可读、可写、异常等),FD_ISSET 返回非零值(通常是 1)。
如果文件描述符 fd 没有在集合 set 中处于活动状态,返回 0。
还有以下几种
*FD_SET(fd, fd_set set) : 作用 :将文件描述符 fd 添加到文件描述符集合 set 中。
**FD_CLR(fd, fd_set *set) **: 作用 :将文件描述符 fd 从文件描述符集合 set 中移除。
*FD_ZERO(fd_set set) : 作用 :清空文件描述符集合 set。
断线重连 如果客户端处于 TIME_WAIT 状态并显式使用 bind 绑定到同一个端口,则会出错。 当然,服务端也是一样的
客户端/服务端在服务端断开连接后,尝试重新绑定(bind)时出现错误,这是因为此时客户端处于TIME_WAIT的状态
TIME_WAIT 状态确保所有的连接数据完全清除,以防止新的连接复用相同的端口并收到之前连接的数据包。
setsockopt 是一个用于设置套接字选项的系统调用函数。它允许开发者调整套接字的行为,例如设置端口复用、超时、缓冲区大小等。
1 2 3 #include <sys/socket.h> int setsockopt (int sockfd, int level, int optname, const void *optval, socklen_t optlen)
参数说明
sockfd
表示套接字描述符,由 socket() 函数创建。
指定需要设置选项的套接字。
level
设置选项所属的协议层,通常是以下值之一:
**SOL_SOCKET**:通用套接字选项。
**IPPROTO_TCP**:TCP 协议相关选项。
**IPPROTO_IP**:IPv4 协议相关选项。
**IPPROTO_IPV6**:IPv6 协议相关选项。
optname
指定要设置的选项名称,其含义由
决定:
通用选项(SOL_SOCKET):
SO_REUSEADDR:允许端口复用。SO_KEEPALIVE:启用 TCP 保活。SO_RCVBUF:设置接收缓冲区大小。SO_SNDBUF:设置发送缓冲区大小。SO_RCVTIMEO:接收超时时间。SO_SNDTIMEO:发送超时时间。
TCP 选项(IPPROTO_TCP):
TCP_NODELAY:禁用 Nagle 算法(减少延迟)。TCP_MAXSEG:设置最大 TCP 段大小。TCP_KEEPIDLE:设置保活探测的空闲时间。TCP_KEEPINTVL:设置保活探测之间的间隔时间。TCP_KEEPCNT:设置保活探测的最大重试次数。
optval
指向包含选项值的缓冲区。具体值类型取决于
和协议:
布尔值选项:int 类型。
超时选项:struct timeval 类型。
optlen
optval 指向数据的大小(字节数),通常是 sizeof(optval)。
允许端口复用:这样可以无视TIME_WAIT
1 2 3 4 int opt = 1 ;if (setsockopt (sockfd, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof (opt)) < 0 ) { perror ("setsockopt(SO_REUSEADDR) failed" ); }
支持断线重连的服务端,客户端代码:
服务端
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 #include <stdio.h> #include <string.h> #include <stdlib.h> #include <unistd.h> #include <arpa/inet.h> #include <sys/select.h> #include <sys/socket.h> #define PORT 8080 #define BUF_SIZE 4096 int main () int server_fd, client_fd = -1 ; struct sockaddr_in server_addr, client_addr; fd_set monitor_set, ready_set; char buf[BUF_SIZE] = { 0 }; socklen_t addr_len = sizeof (client_addr); if ((server_fd = socket (AF_INET, SOCK_STREAM, 0 )) == -1 ) { perror ("Socket creation failed" ); exit (EXIT_FAILURE); } int opt = 1 ; setsockopt (server_fd, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof (opt)); server_addr.sin_family = AF_INET; server_addr.sin_addr.s_addr = INADDR_ANY; server_addr.sin_port = htons (PORT); if (bind (server_fd, (struct sockaddr*)&server_addr, sizeof (server_addr)) == -1 ) { perror ("Bind failed" ); close (server_fd); exit (EXIT_FAILURE); } if (listen (server_fd, 5 ) == -1 ) { perror ("Listen failed" ); close (server_fd); exit (EXIT_FAILURE); } printf ("Server is listening on port %d...\n" , PORT); FD_ZERO (&monitor_set); FD_SET (server_fd, &monitor_set); while (1 ) { memcpy (&ready_set, &monitor_set, sizeof (monitor_set)); if (select (FD_SETSIZE, &ready_set, NULL , NULL , NULL ) == -1 ) { perror ("Select failed" ); break ; } if (FD_ISSET (server_fd, &ready_set)) { client_fd = accept (server_fd, (struct sockaddr*)&client_addr, &addr_len); if (client_fd == -1 ) { perror ("Accept failed" ); continue ; } printf ("Client connected\n" ); FD_SET (client_fd, &monitor_set); } if (client_fd != -1 && FD_ISSET (client_fd, &ready_set)) { bzero (buf, BUF_SIZE); ssize_t len = recv (client_fd, buf, BUF_SIZE, 0 ); if (len <= 0 ) { printf ("Client disconnected\n" ); close (client_fd); FD_CLR (client_fd, &monitor_set); client_fd = -1 ; } else { printf ("Received: %s\n" , buf); } } } close (server_fd); return 0 ; }
客户端
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 #include <stdio.h> #include <string.h> #include <stdlib.h> #include <unistd.h> #include <arpa/inet.h> #include <sys/socket.h> #define PORT 8080 #define SERVER_IP "127.0.0.1" #define BUF_SIZE 4096 int main () int sockfd; struct sockaddr_in server_addr; char buf[BUF_SIZE] = {0 }; server_addr.sin_family = AF_INET; server_addr.sin_port = htons (PORT); inet_pton (AF_INET, SERVER_IP, &server_addr.sin_addr); while (1 ) { if ((sockfd = socket (AF_INET, SOCK_STREAM, 0 )) == -1 ) { perror ("Socket creation failed" ); sleep (5 ); continue ; } if (connect (sockfd, (struct sockaddr *)&server_addr, sizeof (server_addr)) == -1 ) { perror ("Connect failed, retrying..." ); close (sockfd); sleep (5 ); continue ; } printf ("Connected to server!\n" ); while (1 ) { printf ("Enter message: " ); fgets (buf, BUF_SIZE, stdin); send (sockfd, buf, strlen (buf), 0 ); ssize_t len = recv (sockfd, buf, BUF_SIZE, 0 ); if (len <= 0 ) { printf ("Connection lost, reconnecting...\n" ); close (sockfd); break ; } buf[len] = '\0' ; printf ("Server: %s\n" , buf); } } return 0 ; }
Windows下网络编程 //
跨平台网络编程 远控项目 可以去看远控项目: 从零开始做远控 簡介篇 做一个属于你自己的远控_zeronet qt-CSDN博客
服务端 TcpServer类:
TcpServer.h
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 #ifndef TCPSERVER_H #define TCPSERVER_H #include <QObject> #include <QTcpServer> class TcpServer : public QObject{ Q_OBJECT public : explicit TcpServer (QObject *parent = 0 ) void start (int port) void stop () QTcpServer *server () { return mServer; } private : QTcpServer *mServer; signals: void newConnection (QTcpSocket *sock) public slots: void newConnection () }; #endif
TcpServer.cpp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #include "tcpserver.h" TcpServer::TcpServer (QObject *parent) : QObject (parent) { mServer = new QTcpServer (this ); connect (mServer, SIGNAL (newConnection ()), this , SLOT (newConnection ())); } void TcpServer::start (int port) if (!mServer->isListening ()) { if (mServer->listen (QHostAddress::AnyIPv4, port)) { qDebug () << "服务端监听成功" ; } else { qDebug () << "服务端监听失败:" << mServer->errorString (); } } } void TcpServer::stop () if (mServer->isListening ()) { mServer->close (); } } void TcpServer::newConnection () while (mServer->hasPendingConnections ()) { QTcpSocket *sock = mServer->nextPendingConnection (); emit newConnection (sock) ; } }
TcpSocket类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 #ifndef TCPSOCKET_H #define TCPSOCKET_H #include <QObject> #include <QTcpSocket> #include <QHostAddress> class TcpSocket : public QObject{ Q_OBJECT public : explicit TcpSocket (QTcpSocket *sock, QObject *parent = 0 ) QTcpSocket *socket () { return mSock; } QByteArray *buffer () { return &mBuf; } void close () void write (QByteArray data) private : QTcpSocket *mSock; QByteArray mBuf; signals: void newData () void disconnected () public slots: void readReady () }; #endif
TcpSocket.cpp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 #include "tcpsocket.h" TcpSocket::TcpSocket (QTcpSocket *sock, QObject *parent): QObject (parent), mSock (sock) { mSock->setParent (this ); connect (mSock, SIGNAL (readyRead ()), this , SLOT (readReady ())); connect (mSock, SIGNAL (disconnected ()), this , SIGNAL (disconnected ())); qDebug () << mSock->peerAddress ().toString () << ":" << mSock->peerPort () << " 已连接上服务端" ; } void TcpSocket::close () mSock->close (); } void TcpSocket::write (QByteArray data) mSock->write (data); if (!mSock->waitForBytesWritten (3000 )) { close (); emit disconnected () ; qDebug () << mSock->peerAddress ().toString () << ":" << mSock->peerPort () << " 写入失败:" << mSock->errorString (); } } void TcpSocket::readReady () mBuf.append (mSock->readAll ()); emit newData () ; }
ZeroClient类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 #ifndef ZEROCLIENT_H #define ZEROCLIENT_H #include <QObject> #include "tcpsocket.h" #include <QTimer> #include <QTcpSocket> #include <QHostAddress> class ZeroClient : public QObject{ Q_OBJECT public : explicit ZeroClient (QTcpSocket *sock, QObject *parent = 0 ) const QByteArray CmdScreenSpy = "SCREEN_SPY" ; const QByteArray CmdKeyboardSpy = "KEYBOARD_SPY" ; const QByteArray CmdFileSpy = "FILE_SPY" ; const QByteArray CmdCmdSpy = "CMD_SPY" ; const QByteArray CmdSendMessage = "SEND_MESSAGE" ; const QByteArray CmdReboot = "REBOOT" ; const QByteArray CmdQuit = "QUIT" ; const QByteArray CmdLogin = "LOGIN" ; const QByteArray CmdSplit = ";" ; const QByteArray CmdEnd = "\r\n" ; void closeAndDelete () void setId (int id) mId = id; } private : TcpSocket *mSock; QTimer *mLoginTimeout; int mId; void processCommand (QByteArray &cmd, QByteArray &args) QHash<QByteArray, QByteArray> parseArgs (QByteArray &args) ; void doLogin (QHash<QByteArray, QByteArray> &args) signals: void login (ZeroClient *client, QString userName, QString ip, int port, QString system) void logout (int id) public slots: void clientLoginTimeout () void disconnected () void newData () }; #endif
ZeroClient.cpp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 #include "zeroclient.h" ZeroClient::ZeroClient (QTcpSocket *sock, QObject *parent) : QObject (parent), mId (-1 ) { mSock = new TcpSocket (sock, this ); connect (mSock, SIGNAL (newData ()), this , SLOT (newData ())); connect (mSock, SIGNAL (disconnected ()), this , SLOT (disconnected ())); mLoginTimeout = new QTimer (this ); connect (mLoginTimeout, SIGNAL (timeout ()), this , SLOT (clientLoginTimeout ())); mLoginTimeout->start (10 *1000 ); } void ZeroClient::closeAndDelete () qDebug () << mSock->socket ()->peerAddress ().toString () << ":" << mSock->socket ()->peerPort () << " 已经断开服务端" ; mSock->close (); deleteLater (); } void ZeroClient::processCommand (QByteArray &cmd, QByteArray &args) cmd = cmd.toUpper ().trimmed (); QHash<QByteArray, QByteArray> hashArgs = parseArgs (args); if (cmd == CmdLogin && mId == -1 ) { doLogin (hashArgs); return ; } } QHash<QByteArray, QByteArray> ZeroClient::parseArgs (QByteArray &args) QList<QByteArray> listArgs = args.split (CmdSplit[0 ]); QHash<QByteArray, QByteArray> hashArgs; for (int i=0 ; i<listArgs.length ()-1 ; i+=2 ) { hashArgs.insert (listArgs[i].toUpper ().trimmed (), listArgs[i+1 ].trimmed ()); } return hashArgs; } void ZeroClient::doLogin (QHash<QByteArray, QByteArray> &args) QString userName = args["USER_NAME" ]; QString system = args["SYSTEM" ]; QString ip = mSock->socket ()->peerAddress ().toString (); int port = mSock->socket ()->peerPort (); emit login (this , userName, ip, port, system) ; qDebug () << ip << ":" << port << " 已经登入服务端" ; } void ZeroClient::clientLoginTimeout () if (mId == -1 ) { closeAndDelete (); } } void ZeroClient::disconnected () if (mId >= 0 ) { emit logout (mId) ; } closeAndDelete (); } void ZeroClient::newData () QByteArray *buf = mSock->buffer (); int endIndex; while ((endIndex = buf->indexOf (CmdEnd)) > -1 ) { QByteArray data = buf->mid (0 , endIndex); buf->remove (0 , endIndex + CmdEnd.length ()); QByteArray cmd, args; int argIndex = data.indexOf (CmdSplit); if (argIndex == -1 ) { cmd = data; } else { cmd = data.mid (0 , argIndex); args = data.mid (argIndex+CmdSplit.length (), data.length ()); } processCommand (cmd, args); } }
ZeroServer类:
ZeroServer.h
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 #ifndef ZEROSERVER_H #define ZEROSERVER_H #include <QObject> #include "TcpServer.h" #include "ZeroClient.h" #include <QHash> class ZeroServer : public QObject{ Q_OBJECT public : explicit ZeroServer (QObject *parent = 0 ) void start (int port) void stop () ZeroClient *client (int id) { return mClients[id]; } private : TcpServer *mServer; QHash<int , ZeroClient*> mClients; int generateId () signals: void clientLogin (int id, QString userName, QString ip,int port, QString system) void clientLogout (int id) public slots: void newConnection (QTcpSocket *sock) void login (ZeroClient*, QString userName, QString ip, int port, QString system) void logout (int id) }; #endif
ZeroServer.cpp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 #include "zeroserver.h" ZeroServer::ZeroServer (QObject *parent) : QObject (parent) { mServer = new TcpServer (this ); connect (mServer, SIGNAL (newConnection (QTcpSocket*)), this , SLOT (newConnection (QTcpSocket*))); } void ZeroServer::start (int port) mServer->start (port); } void ZeroServer::stop () mServer->stop (); } int ZeroServer::generateId () const int max = 1 << 30 ; QList<int > existsKeys = mClients.keys (); for (int i=mClients.size ()+1 ; i<max; ++i) { if (existsKeys.indexOf (i) == -1 ) { return i; } } return -1 ; } void ZeroServer::newConnection (QTcpSocket *sock) ZeroClient *client = new ZeroClient (sock); connect (client, SIGNAL (login (ZeroClient*,QString,QString,int ,QString)), this , SLOT (login (ZeroClient*,QString,QString,int ,QString))); connect (client, SIGNAL (logout (int )), this , SLOT (logout (int ))); } void ZeroServer::login (ZeroClient *client, QString userName, QString ip, int port, QString system) int id = generateId (); mClients.insert (id, client); client->setId (id); emit clientLogin (id, userName, ip, port, system) ; } void ZeroServer::logout (int id) mClients.remove (id); emit clientLogout (id) ; }
客户端: 客户端代码和CSDN项目不同,主要区别是从windows的代码转为了QT的
TcpSocket类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 #pragma once #ifndef TCPSOCKET_H #define TCPSOCKET_H #include <QTcpSocket> #include <QHostAddress> #include <QString> #include <QByteArray> #include <iostream> #include <QHostInfo> struct RecvResult { QByteArray data; int errorCode; }; class TcpSocket : public QObject{ Q_OBJECT public : TcpSocket (QObject* parent = nullptr ); ~TcpSocket (); static QString fromDomainToIP (const QString& domain) bool connectTo (const QString& domain, int port) void disconnect () bool sendData (const QByteArray& data) int recvData (QString& receivedData) void readReady () bool isConnected () const QTcpSocket* mSock; QByteArray buf; private : QString mIp; int mPort; signals: void newData (QString buf) }; #endif
TcpSocket.cpp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 #include "TcpSocket.h" TcpSocket::TcpSocket (QObject* parent): QObject (parent), mSock (new QTcpSocket (this )), mPort (0 ) { connect (mSock, &QTcpSocket::connected, this , [this ]() { std::cout << "Connected to server!" << std::endl; connect (mSock, &QTcpSocket::readyRead, this , &TcpSocket::readReady); }); connect (mSock, &QTcpSocket::disconnected, this , []() { std::cout << "Disconnected from server!" << std::endl; }); } void TcpSocket::readReady () if (mSock->bytesAvailable () == 0 ) { if (!mSock->waitForReadyRead (10000 )) { std::cout << "Timeout or error: " << mSock->errorString ().toStdString () << std::endl; return ; } } buf.append (mSock->readAll ()); QString string = QString::fromUtf8 (buf); emit newData (string) ; buf.clear (); } TcpSocket::~TcpSocket () { if (isConnected ()) { mSock->disconnectFromHost (); } } QString TcpSocket::fromDomainToIP (const QString& domain) QHostInfo hostInfo = QHostInfo::fromName (domain); if (hostInfo.error () == QHostInfo::NoError) { return hostInfo.addresses ().first ().toString (); } else { std::cout << "Failed to resolve domain!" << std::endl; return QString (); } } bool TcpSocket::connectTo (const QString& domain, int port) mIp = fromDomainToIP (domain); mPort = port; if (mIp.isEmpty ()) { std::cout << "Failed to resolve domain" << std::endl; return false ; } mSock->connectToHost (mIp, mPort); return mSock->waitForConnected (5000 ); } void TcpSocket::disconnect () if (isConnected ()) { mSock->disconnectFromHost (); } } bool TcpSocket::sendData (const QByteArray& data) if (isConnected ()) { mSock->write (data); return mSock->waitForBytesWritten (3000 ); } return false ; } int TcpSocket::recvData (QString& receivedData) if (!isConnected ()) { std::cout << "Socket not connected!" << std::endl; std::fflush (stdout); receivedData.clear (); return -1 ; } receivedData.clear (); while (mSock->waitForReadyRead (-1 )) { QByteArray data = mSock->readAll (); if (data.isEmpty ()) { continue ; } receivedData.append (QString::fromUtf8 (data)); if (receivedData.contains ("\r\n" )) { break ; } } if (receivedData.isEmpty ()) { std::cout << "Failed to receive data or connection closed" << std::endl; std::fflush (stdout); disconnect (); return -2 ; } return 0 ; } bool TcpSocket::isConnected () const return mSock->state () == QTcpSocket::ConnectedState; }
ZeroClient类:
ZeroClient.h
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 #pragma once #ifndef ZEROCLIENT_H #define ZEROCLIENT_H #include <QObject> #include <QString> #include <QByteArray> #include <QTcpSocket> #include <iostream> #include <map> #include <vector> #include <QProcessEnvironment> #include "TcpSocket.h" #include <QDataStream> struct TimeData { int hour; int minute; int second; int millisecond; }; class ZeroClient : public QObject{ Q_OBJECT public : ZeroClient (); ~ZeroClient (); QString mBuf; TcpSocket mSock; const QString CmdScreenSpy = "SCREEN_SPY" ; const QString CmdKeyboardSpy = "KEYBOARD_SPY" ; const QString CmdFileSpy = "FILE_SPY" ; const QString CmdCmdSpy = "CMD_SPY" ; const QString CmdSendMessage = "SEND_MESSAGE" ; const QString CmdReboot = "REBOOT" ; const QString CmdQuit = "QUIT" ; const QString CmdGetTime = "GET_TIME" ; const QString CmdLogin = "LOGIN" ; const QString CmdSplit = ";" ; const QString CmdEnd = "\r\n" ; bool sendLogin () void addDataToBuffer (QByteArray ret) void processCmd (const QString& cmd, QString& data) std::map<QString, QString> parseArgs (QString& data) ; void connectTo (const QString& domain, int port) void doGetTime (std::map<QString, QString> args) signals: void timeDataReceived (const QString& data) private slots: void onNewDataReceived (const QString& data) }; #endif
ZeroClient.cpp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 #include "ZeroClient.h" #include <QTcpSocket> #include <QByteArray> #include <QString> #include <QDebug> ZeroClient::ZeroClient () { QObject* parent = nullptr ; connect (&mSock, &TcpSocket::newData, this , &ZeroClient::onNewDataReceived); } void ZeroClient::onNewDataReceived (const QString& data) addDataToBuffer (data.toUtf8 ()); } ZeroClient::~ZeroClient () { } void ZeroClient::connectTo (const QString& domain, int port) if (!mSock.connectTo (domain, port)) { return ; } if (!sendLogin ()) { return ; } } QString getUserName () QString userName = QProcessEnvironment::systemEnvironment ().value ("USER" ); if (userName.isEmpty ()) { userName = QProcessEnvironment::systemEnvironment ().value ("USERNAME" ); } return userName; } QString getSystemModel () QString osName = QSysInfo::prettyProductName (); if (osName.contains ("Windows" , Qt::CaseInsensitive)) { return "Windows" ; } else if (osName.contains ("Ubuntu" , Qt::CaseInsensitive)) { return "Ubuntu" ; } else { return "Unknown" ; } } bool ZeroClient::sendLogin () QString data; data.append (CmdLogin + CmdSplit); data.append ("SYSTEM" + CmdSplit + getSystemModel () + CmdSplit); data.append ("USER_NAME" + CmdSplit + getUserName ()); data.append (CmdEnd); QByteArray dataUtf8 = data.toUtf8 (); return mSock.sendData (dataUtf8); } void ZeroClient::addDataToBuffer (QByteArray ret) QString str = QString::fromUtf8 (ret); mBuf.append (str); int endIndex; while ((endIndex = mBuf.indexOf (CmdEnd)) >= 0 ) { QString line = mBuf.left (endIndex); mBuf.remove (0 , endIndex + CmdEnd.length ()); int firstSplit = line.indexOf (CmdSplit); QString cmd = line.left (firstSplit); line.remove (0 , firstSplit + CmdSplit.length ()); processCmd (cmd, line); } } void ZeroClient::doGetTime (std::map<QString, QString> args) QString data = args["TIME" ]; emit timeDataReceived (data) ; } void ZeroClient::processCmd (const QString& cmd, QString& data) std::map<QString, QString> args = parseArgs (data); std::cout << cmd.toStdString () << " " << data.toStdString () << std::endl; if (cmd == CmdGetTime) { doGetTime (args); } } std::map<QString, QString> ZeroClient::parseArgs (QString& data) QStringList parts = data.split (CmdSplit); std::map<QString, QString> args; for (int i = 0 ; i < parts.size () - 1 ; i += 2 ) { args[parts.at (i)] = parts.at (i + 1 ); } return args; }