
数据库
数据库
关系与表
DB DBMS SQL
- 数据库(DB)、数据库管理系统(DBMS)、SQL,之间的关系
1.1 什么是数据库?
数据库:英文单词DataBase,简称DB。按照一定格式存储数据的一些文件的组合。
顾名思义:存储数据的仓库,数据的集合。实际上就是一堆文件。这些文件中存储了具有特定格式的数据。
1.2 什么是数据库管理系统?
数据库管理系统:DataBaseManagement,简称DBMS。
作用:专门管理数据库中的数据的,数据库管理系统可以对数据库当中的数据进行增删改查。
类型:层次型、网状型、关系u型(本课程主要学习)。
常见的数据库管理系统:MySQL,Oracle、MS SqlServer、DB2、sybase等…..
1.3 SQL - 结构化查询语言
程序员需要学习SQL语句,程序员通过编写SQL语句,然后DBMS负责执行SQL语句,最终来完成数据库中数据的增删改查操作。
本质:是一套标准。程序员只要学习的就是SQL语句包,这个SQL在mysql中可以使用,同时在Oracle也可以使用。
1.4 MB、DBMS、SQL之间的关系?
DBMS–执行 –> SQL – 操作 –> DB
先安装数据库管理系统MySQL,然后学习SQL语句怎么写,编写SQL语句之后,DBMS 对SQL语句进行执行,最终来完成数据库的数据管理。
1.5 为什么要学习数据库?
应用程序本地管理数据的缺点:
- 特定的格式,特定的应用程序操作,升级维护扩展困难。
- 提取数据困难。
- 约束(权限)困难。每个登录用户拥有不同的增删查改权限。
- 并发困难。多程序共同开发的时候,数据共享速度慢。
- 故障修复困难。
- 应用程序的开发成本大
关系数据库
主键:可唯一标识表中行的键。
类型:
- 主键:被选作唯一确定一行的属性。
- 复合键:用两个或两个以上的属性组合成为主键。
MySql安装
https://dev.mysql.com/downloads/file/?id=526085
点击底下的No thanks,jsut start my download.
安装完之后,将mysql文件夹里面的lib放在系统路径
然后启动安装mysql
依次执行:
1 | mysqld --install |
在执行完
1 | mysqld --initialize --console |
会有临时密码,要记住!
报错信息: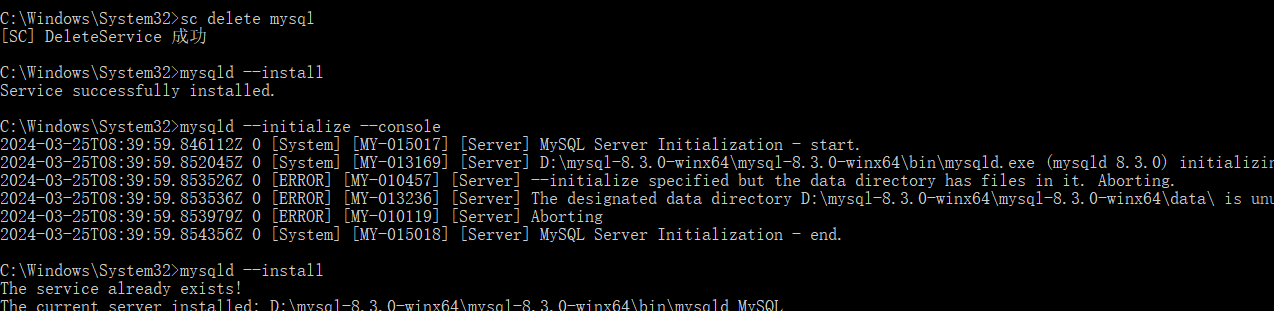
如果出现报错信息,直接将data目录里的东西全都删掉就行
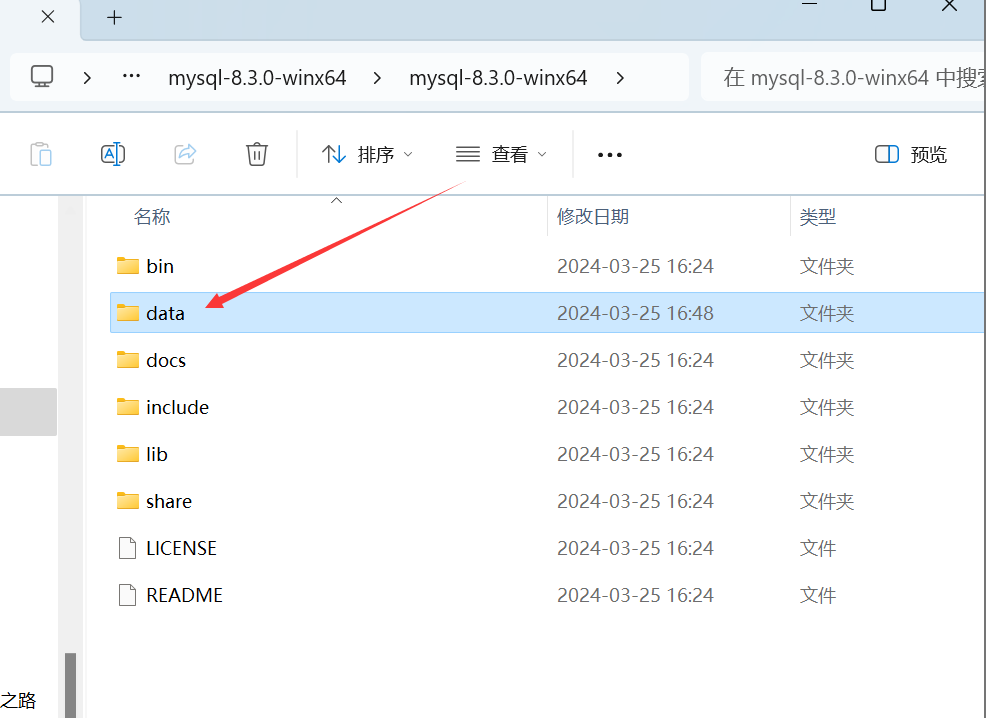
成功之后长这样:
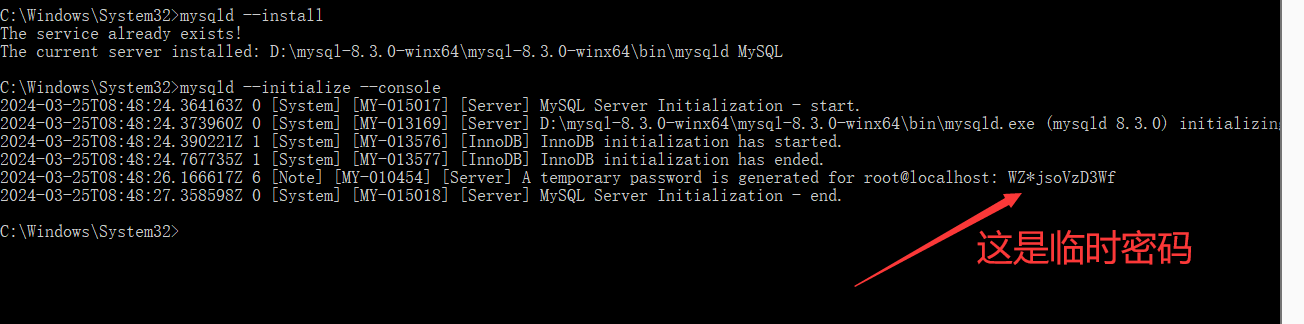
开启服务
1 | net start mysql |
暂停,删除mysql 服务
1 | sc stop mysql |
如何完整删除整个mysql?
总共就三步:
1.删除服务 sc delete mysql
2.删除系统路径
3.删文件
然后在命令行输入
1 | mysql -u root -p |
回车,然后输入安装时初始化密码,出现下面的mysql>就成功了
注意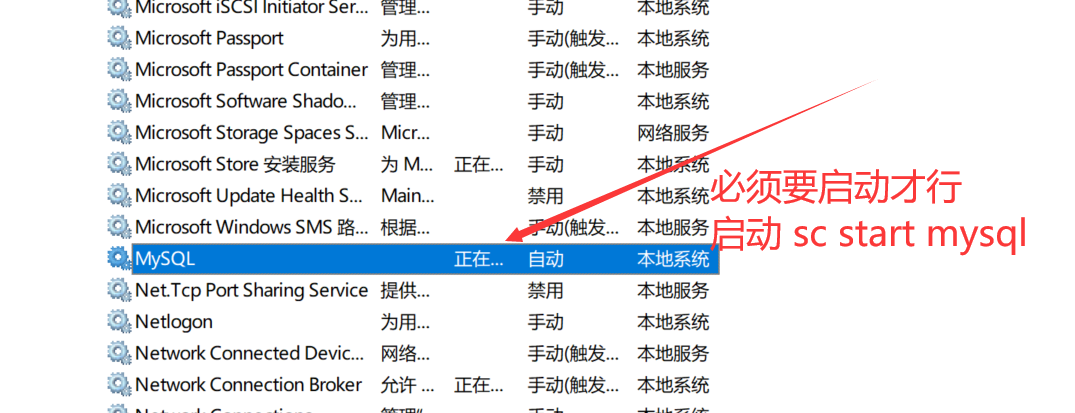
成功后长这样: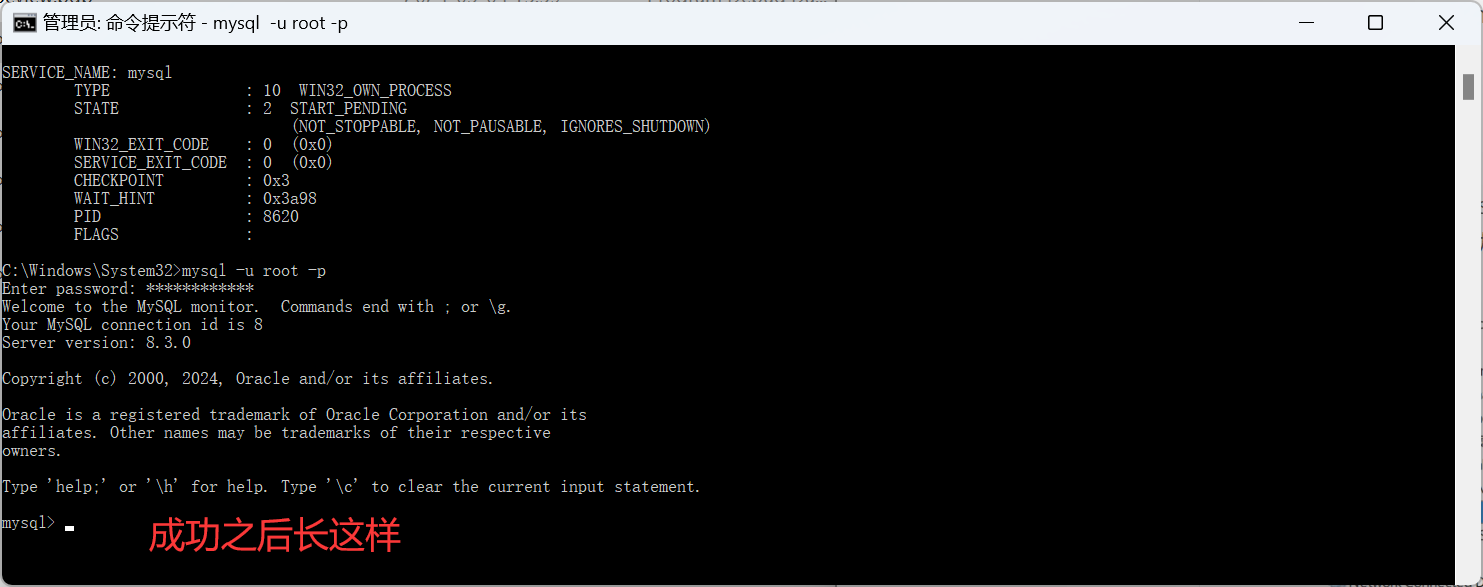
mysql第一次使用,需要修改密码,输入:
1 | alter user 'root'@'localhost' identified by 'toor'; |
(别忘了分号)
我的密码:123456123
端口号默认:3306
范式和表
范式
范式的作用:使用范式可以来判断表中是否存在问题(数据冗余,插入/删除异常等)
第一范式:
必须有主键,每个属性时不可再分的基本数据元素(原子性)
说明:关系型数据库中的所有关系必须满足第一范式
例如以下的表,觉得有无问题?是否属于第一范式?:
| 学号 | 姓名 | 语数外成绩 |
|---|---|---|
| xx | xx | xx |
根据第一范式的定义,确实有主键,就是学号,但是语数外成绩是可以再分的,因此不属于第一范式
于是我们可以拆成这样
| 学号 | 姓名 | 语文 | 数学 | 外语 |
|---|---|---|---|---|
| x’x | x’x’x’x | xxxxx’x | xxx | xxxx |
这样就满足第一范式了
第二范式
看下面这个表:
1.符合第一范式吗?
2.合理吗?
| 学号 | 课程号 | 姓名 | 课程 | 分数 |
|---|---|---|---|---|
| xx | xx | xx | xx | xx |
1.首先满足第一范式的概念
2.存在的不合理是因为,姓名依赖学号,壳程依赖课程号,分数依赖学号和课程号,这叫部分函数依赖,非主键字段有复合主键的一部分决定。
他们堆在一起就会显得十分冗余,因此我们要把他们拆开
| 课程号 | 课程 |
|---|---|
| xx | xx |
| 学号 | 姓名 |
|---|---|
| xx | xx |
| 学号 | 课程号 | 分数 |
|---|---|---|
| xx | xx | xx |
也就是说,能做主键的就提出来做主键
判断是否为第二范式:
1.判断是否为第一范式
2.判断是否有复合键
3.判断是否所有的非主键属性完全依赖复合主键
第三范式:
看下面这个表:
1.满足第二范式吗?
2.有什么不合理之处吗?
| 学号 | 班级 | 班主任 |
|---|---|---|
| xx | xx | xxxx |
1.满足第二范式
2.不合理之处在于,出现了非主键依赖非主键的情况,班主任依赖于班级
学号->班级->班主任
可以拆成这样
| 学号 | 班级 |
|---|---|
| xx | xx |
| 班级 | 班主任 |
|---|---|
| xx | xxx |
巧记第三范式:
1.原子性(不可分)
2.依赖性(必须完全依赖主键)
3.非依赖性(除了主键外部都不依赖)
MySql可视化
下载一个Navicat Premium(有破解版)
连接好长这样:
双击这个海豚图标,变成绿色就是连接成功
新建数据库:
用Navicat建表
先点击 新建数据库
然后新建表
我们做的表包括以下元素:
学生ID 学生姓名 课程ID 课程名称 分数
根据之前学的范式
做的表应该是
学生ID(主键) 学生姓名
课程ID(主键) 课程名称
学生ID (主键) 课程ID(主键) 分数
添加表的元素是这样,点击字段
然后输入元素,例如学生ID,学生姓名等
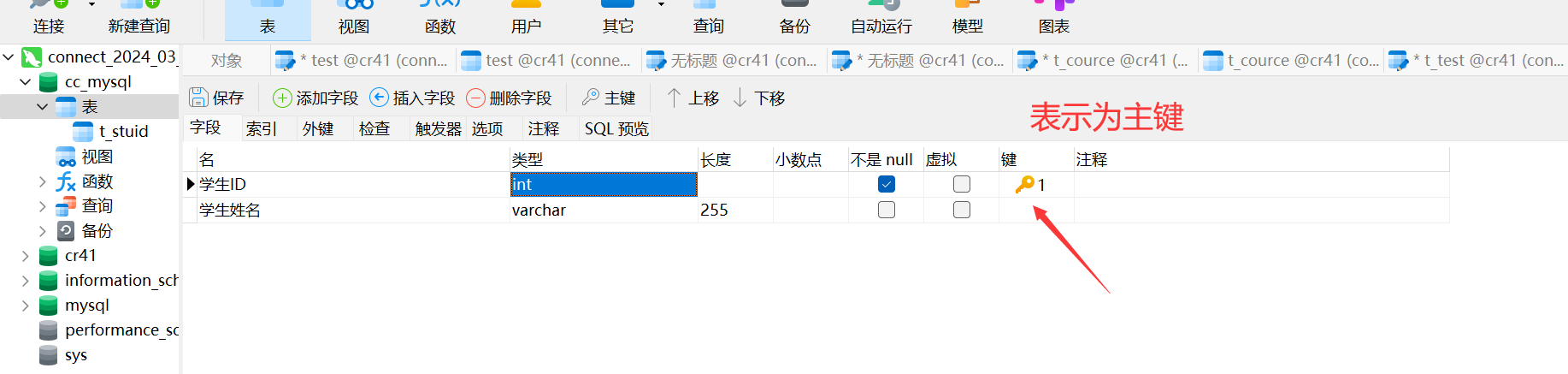
ctrl+s 是保存
建好以后,可以在视图右键,新建视图,视图创建工具
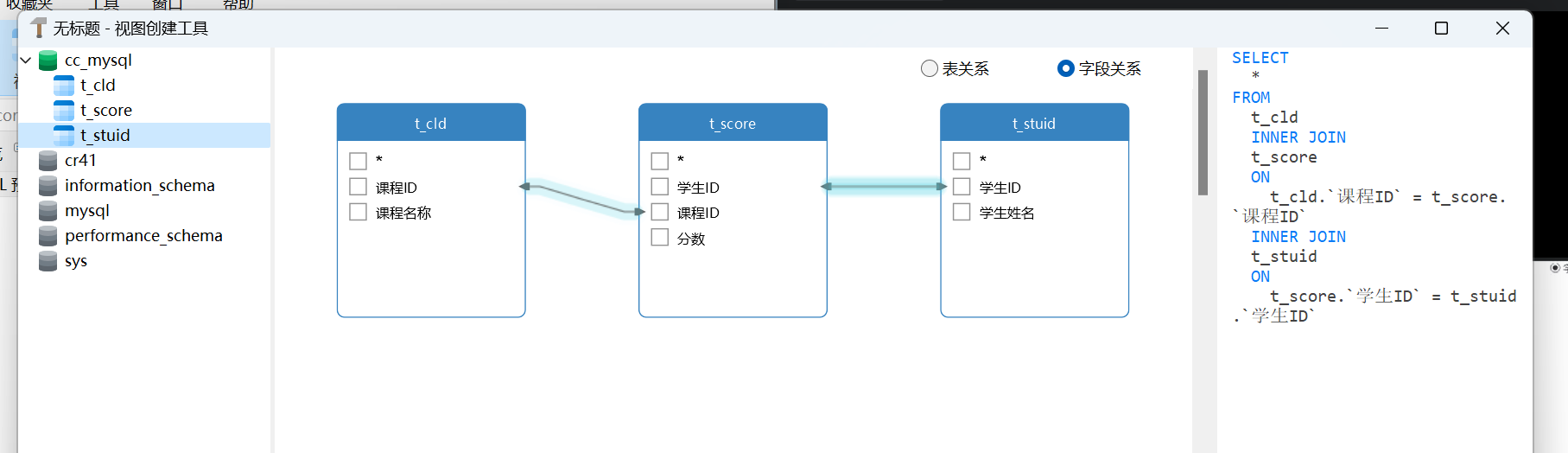
就可以看到具体表的联系了
mysql运算符
参考文章:
MySQL常用运算符(算数、逻辑、比较、位)及其优先级_mysql运算符有哪几类?优先级别分别如何?-CSDN博客
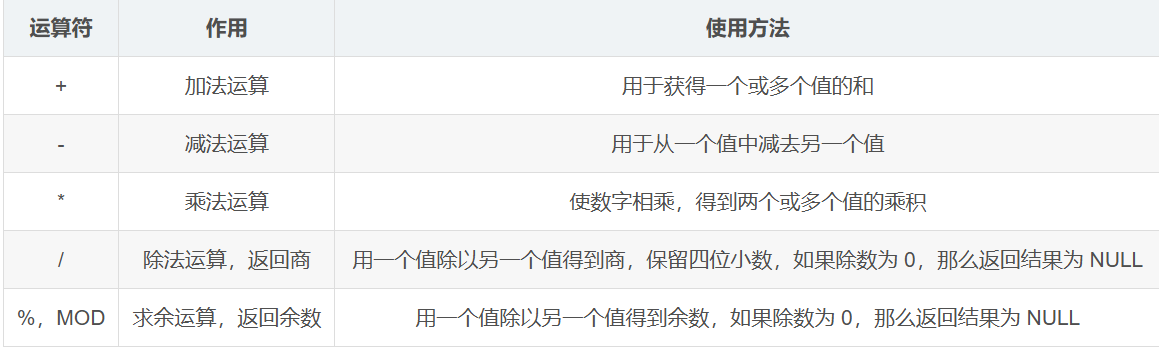
算术运算符
算术运算符
执行算术运算,例如:加、减、乘、除和取余运算等。
比较运算符
包括大于、小于、等于或不等于等等。可以用于比较数字、字符串和表达式的值。比较结果为真,则返回 1,为假则返回 0,比较结果不确定则返回 NULL。
注意,字符串的比较是不区分大小写的。
只有“<=>”才支持NULL的比较,其他比较运算对有NULL操作数时返回的结果就是NULL,永远返回false,即 NULL = NULL 返回false
| 运算符 | 作用 | 说明 |
|---|---|---|
| = | 等于 | 1. 若有一个或两个操作数为 NULL,则比较运算的结果为 NULL。 2. 若两个操作数都是字符串,则按照字符串进行比较。 3. 若两个操作数均为整数,则按照整数进行比较。 4. 若一个操作数为字符串,另一个操作数为数字,则 MySQL 可以自动将字符串转换为数字。 注意:NULL 不能用于 = 比较。 |
| <=> | 安全的等于 | 1. 当两个操作数均为 NULL 时,其返回值为 1 而不为 NULL 2. 而当一个操作数为 NULL 时,其返回值为 0 而不为 NULL。 注意:<=> 可以用来判断 NULL 值,只有“<=>”才支持NULL的比较,其他对有NULL操作数时返回的结果就是NULL |
| <> 或者 != | 不等于 | 1. 用于判断数字、字符串、表达式是否不相等 2.如果两侧操作数不相等,返回值为 1,否则返回值为 0 3. 如果两侧操作数有一个是 NULL,那么返回值也是 NULL。 |
| > | 大于 | 1. 如果大于,返回值为 1,否则返回值为 0 2. 如果两侧操作数有一个是 NULL,那么返回值也是 NULL |
| >= | 大于等于 | 1. 如果大于或者等于,返回值为 1,否则返回值为 0 如果两侧操作数有一个是 NULL,那么返回值也是 NULL |
| < | 小于 | 1. 如果小于,返回值为 1,否则返回值为 0 2. 如果两侧操作数有一个是 NULL,那么返回值也是 NULL |
| <= | 小于等于 | 1. 如果小于或者等于,返回值为 1,否则返回值为 0 2. 如果两侧操作数有一个是 NULL,那么返回值也是 NULL |
| IS NULL 或者 ISNULL | 判断一个值是否为空 | 如果为 NULL,返回值为 1,否则返回值为 0 ISNULL 可认为是 IS NULL 的简写,作用和用法完全相同。 |
| IS NOT NULL | 判断一个值是否不为空 | 如果是非 NULL,返回值为 1,否则返回值为 0 |
| BETWEEN AND | 判断一个值是否落在两个值之间 | 语法是大于等于 min 并且小于等于 max,那么返回值为 1,否则返回值为 0 注意:对于不同的时间数据类型,如datetime类型的2021-02-25 08:30:00,系统处理时会把时分秒默认为0进行处理,即2021-02-25 00:00:00,所以会出现结果不一致,但不是between and的问题 |
| IN | 判断操作数是否为IN列表中的一个值 | 如果是则返回1,否则返回0,对于NULL则返回NULL |
| NOT IN | 用于匹配字符串 | 1. 返回的结果值有1、0与NULL 2.包含两种通配符。“%”匹配任何字符,甚至包括零字符;“_”只能匹配一个字符 |
| LIKE | 用于匹配字符串 | 1. 返回的结果值有1、0与NULL 2.包含两种通配符。“%”匹配任何字符,甚至包括零字符;“_”只能匹配一个字符 |
| REGEXP | 正则表达式 | 1. 匹配不区分大小写 2. 可以使用 BINARY 关键字进行区分大小写 3. 匹配可使用的通配符非常多,与其他通配符普适 4.在 MySQL 中,使用 REGEXP 运算符进行正则表达式匹配。如果表达式匹配成功,则返回 1,否则返回 0。 |
| LEAST | 比较所有表达式的值,并返回其中最小的值 | 如果任意一个参数为 NULL,返回 NULL。 |
| GREATEST | 比较所有表达式的值,并返回其中最大的值。 | 如果任意一个参数为 NULL,则结果为 NULL。 |
sql语句示例:
IS NULL 和 IS NOT NULL
用于判断某字段是否为 NULL 或非 NULL。
1 | -- 查询 age 字段为 NULL 的记录 |
ISNULL
用于判断表达式是否为 NULL,如果为 NULL 返回 1,否则返回 0。
1 | -- 如果 age 为 NULL,返回 1,否则返回 0 |
BETWEEN … AND
用于判断值是否在一个范围内(包括边界值)。
1 | -- 查询年龄在 20 到 30 岁之间的记录 |
IN
1 | -- 查询年龄为 20、25 或 30 的记录 |
NOT IN
用于判断值不在指定列表中。
1 | -- 查询年龄不是 20、25 或 30 的记录 |
LIKE
用于字符串匹配,可以使用 % 和 _ 通配符。
1 | -- 查询名称以 "A" 开头的记录 |
REGEXP
1 | -- 查询名称中包含 "john" 的记录(不区分大小写) |
LEAST
1 | -- 比较多个列或常量值,返回最小值 |
GREATEST
1 | -- 比较多个列或常量值,返回最大值 |
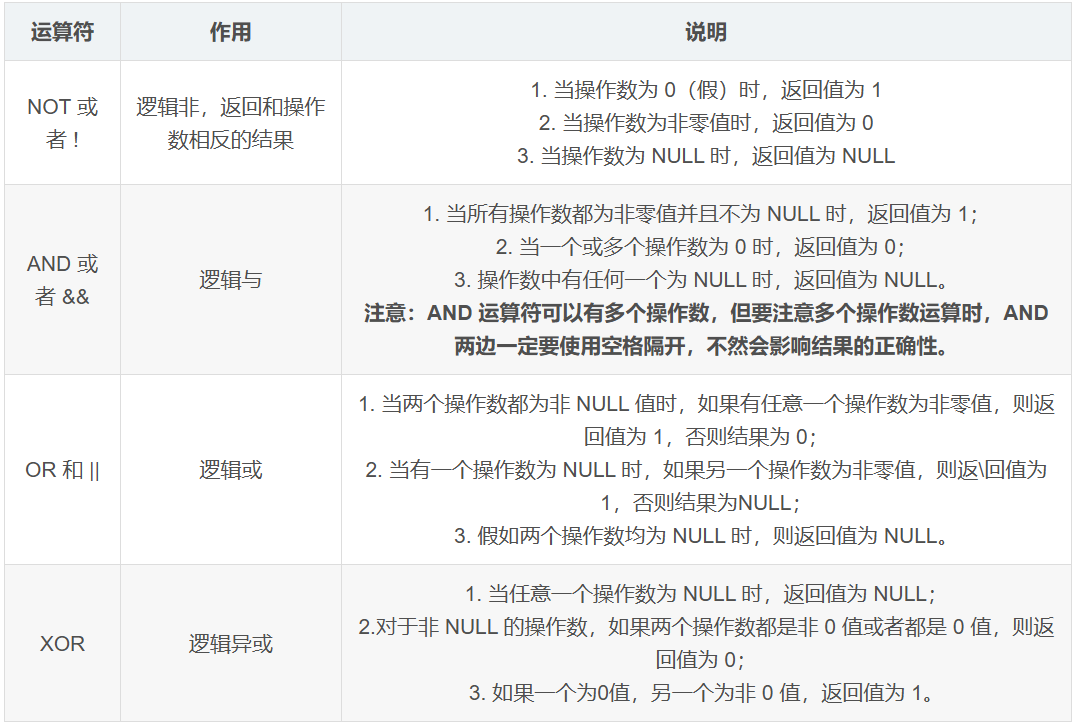
逻辑运算符
逻辑运算符又称为布尔运算符,包括与、或、非和异或等逻辑运算符。其返回值为布尔型,真值(1 或 true)和假值(0 或 false)。
位运算符
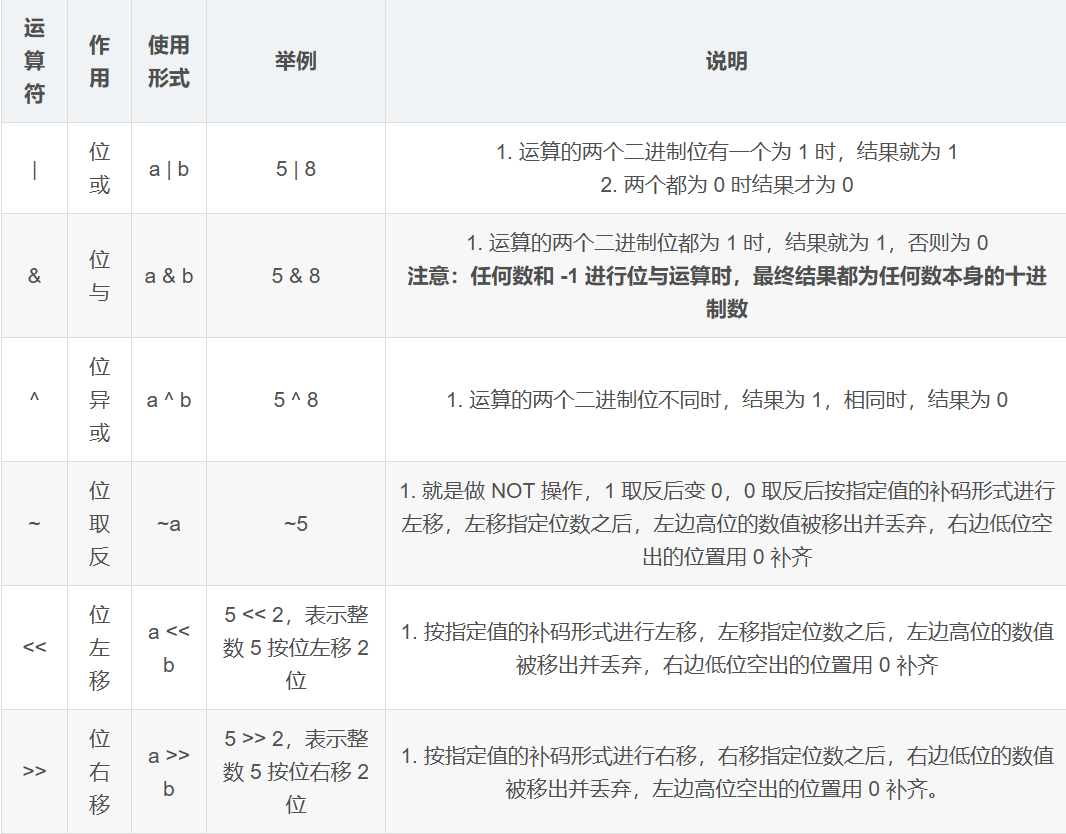
优先级
初始化 MySQL
这里我用的是云服务器Ubuntu系统,Kali貌似不是mysql,而是MariaDB
打开/关闭 mysql 服务
1 | sudo service mysql start/stop |
重启 mysql 服务
1 | sudo service mysql restart |
mysql 客户端远程登录
Mysql 安装后,默认只允许本机访问 Mysql。如果需要远程连接,需要修改如下两个步骤。
第一步:修改 mysql 配置文件
打开 sudo vim /etc/mysql/mysql.conf.d/mysqld.cnf 配置文件, 找到[mysqld]
把下面这俩注释掉
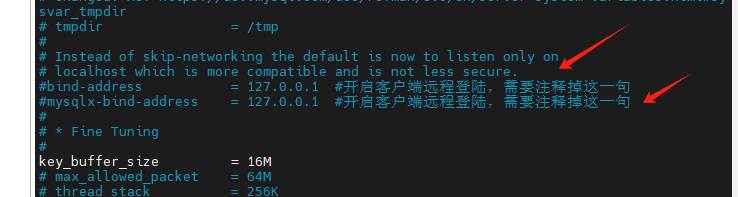
第二步:修改 host 权限
mysql.user 表中 Host 为%的含义 Host 列指定了允许用户登录所使用的 IP,比如 user=root Host=192.168.1.1。这里的意思就是说 root 用户只能通过 192.168.1.1 的客户端去访问。 而 % 是 个 通 配 符 , 如 果 Host=192.168.1.% , 那 么 就 表 示 只 要 是 IP 地 址 前 缀 为 “192.168.1.”的客户端都可以连接。如果 Host=%,表示所有 IP 都有连接权限。
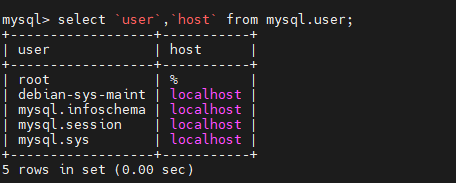
查看 mysql 用户账号信息。
1 | mysql> select `user`,`host` from mysql.user; |
update 修改 root 账号的 host 字段值为’%’。
1 | mysql> update mysql.user set host='%' where user='root'; |
改完长这样
第三步:重启 mysql 服务器
1 | sudo service mysql restart |
第四步:关闭防火墙(如果是云服务器)
用Navicat连接远程数据库
新建一个连接,主机填上云服务器的ip地址
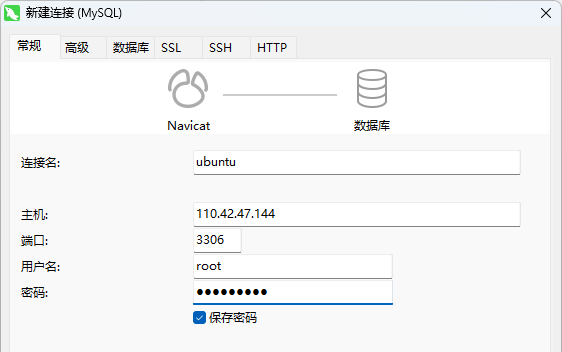
发现变绿了就是连上了
mysql常见命令和语法规范
1.查看当前所有数据库
1 | show databases; |
2.打开指定的库
1 | use 库名; |
3.查看当前库的所有表
1 | show tables; |
4.查看其他库的所有表
1 | show tables from 库名; |
5.创建表
1 | cerate table 表名( |
6.查看表结构
1 | desc 表名; |
7.查看 mysql 当前所有用户
1 | select `user`,`host` from `mysql`.`user`; |
语法规范
不区分大小写,但建议关键字大写,表名、列名小写。
每条命令最好用分号结尾。
每条命令根据需要,可以进行缩进或者换行。
注释 :
单行注释:#注释文字
单行注释:– 注释文字(杠杠空格)
多行注释:/* 注释文字 */
数据类型及存储引擎
数据类型
整数
| 类型 | 说明 | 存储需求(取值范围) |
|---|---|---|
| tinyint | 很小整数 | 1字节 |
| smallint | 小整数 | 2字节 |
| mediumint | 中等 | 3字节 |
| int(integer) | 普通 | 4字节 |
| bigint | 大整数 | 8字节 |
int(10) 这里的 10 指的是数值的宽度,并不是字节, INT(10) 会显示成一个至少 10 位字符宽度的数值,默认会在前面补零(在某些条件下)。
浮点数和定点数
| 类型 | 说明 | 存储需求 |
|---|---|---|
| float | 单精度浮点数 | 4字节 |
| double | 双精度浮点数 | 8字节 |
| decimal | 压缩的“严格”定点数 | M+2字节 |
注:定点数以字符串形式存储,对精度要求高时使用 decimal 较好;尽量避免对浮点数进行减法和比较运算
定义数据类型为 DECIMAL,使用以下语法:
1 | DECIMAL(M,D); |
M是表示有效数字数的精度。 M范围为 1〜65。
D 是表示小数点后的位数。 D 的范围是 0~30。MySQL 要求 D 小于或等于(<=)P。
DECIMAL(M,D)表示列可以存储 D 位小数的 M位数。十进制列的实际范围取决于精度和刻度。
时间/日期类型
| 数据类型 | 格式 | 存储需求 |
|---|---|---|
| date | YYYY-MM-DD | 3个字节 |
| time | HH:MM:SS | 3个字节 |
| year | YYYY | 1个字节 |
| datetime | YYYY-MM-DD HH:MM:SS | 8个字节 |
| timestamp | YYYYMMDD HHMMSS | 4个字节 |
1.在创建新记录和修改现有记录的时候都对这个数据列刷新:
1 | TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP |
2.这条语句用于在创建新记录时将 TIMESTAMP 列设置为当前时间,但以后修改记录时不再更新这个列的值。
1 | TIMESTAMP DEFAULT CURRENT_TIMESTAMP |
3.这条语句会在插入新记录时将 TIMESTAMP 列的值设置为 0,并在修改该记录时自动刷新为当前时间。
1 | TIMESTAMP ON UPDATE CURRENT_TIMESTAMP |
当新记录被创建时,updated_time 默认值为 0000-00-00 00:00:00(或 NULL,取决于 SQL 模式设置)。之后每次更新记录时,updated_time 将被更新为当时的当前时间。
- 在插入新记录时,该语句会将
TIMESTAMP列设置为指定的日期时间值,并在每次修改该记录时自动刷新为当前时间。
1 | TIMESTAMP DEFAULT 'yyyy-mm-dd hh:mm:ss' ON UPDATE CURRENT_TIMESTAMP |
代码例子:
1 | CREATE TABLE users |
created_at 列:用于记录记录的创建时间。插入新记录时自动填充为当前时间,但后续修改该记录时不会自动更新。
updated_at 列:用于记录记录的最后修改时间。插入新记录时自动设置为当前时间,后续修改该记录时 updated_at 会自动刷新为最新的当前时间。
也就是说,当执行如下语句的时候
1 | INSERT INTO users (username, email) VALUES ('john_doe', 'john@example.com'); |
执行这条语句后,表中的 created_at 和 updated_at 列都会自动设置为插入时的当前时间。
1 | id | username | email | created_at | updated_at |
字符串类型
| 类型 | 说明 | 存储需求 |
|---|---|---|
| char | 定长字符串 | 0-255 |
| varchar | 变长字符串 | 0-255 |
| tinyblob | 不超过255个字符的二进制字符串 | 0-255 |
| tinytext | 短文本字符串 | 0-255 |
| blob | 二进制形式的长文本数据 | 0-65535 |
| text | 长文本数据 | 0-65535 |
| …. | ….. | ….. |
存储引擎
1. MyISAM 存储引擎
MyISAM 是 MySQL 的默认存储引擎之一,以简单和高效著称,适合读取密集型应用。
特性
表级锁:在操作表时,MyISAM 会锁住整个表,这会导致并发写入性能不高。适合大量读操作、较少写操作的场景。
不支持事务:MyISAM 不支持事务功能,无法进行回滚操作,不适合需要严格数据一致性的应用。
不支持外键:MyISAM 不支持外键约束,适合不需要复杂数据关联的场景。
存储结构
:MyISAM 使用三种文件存储表数据:
.frm文件:表结构文件。.MYD文件:存储数据文件。.MYI文件:存储索引文件。
数据压缩:MyISAM 支持表的压缩和全文索引,提高查询效率。
快速计数:由于保存了表的总行数,因此使用
COUNT(*)查询的速度较快。
优缺点
- 优点:
- 查询速度快,特别适合只读或读多写少的场景。
- 占用的存储空间较小,支持全文索引。
- 缺点:
- 不支持事务和外键,无法保证数据的完整性。
- 并发性能较差,不适合写操作密集型场景。
适用场景
- 适合以查询为主、数据更新频率低、并发量不高的应用,如内容管理系统 (CMS)、数据分析等场景。
2. InnoDB 存储引擎
InnoDB 是 MySQL 的另一种存储引擎,以支持事务和高并发著称,适合对数据完整性和并发要求较高的应用。
特性
- 行级锁:InnoDB 采用行级锁,可以实现更高的并发性能,更适合读写混合或写密集型应用。
- 支持事务:InnoDB 完全支持 ACID 特性的事务,可以进行回滚操作,保证数据的一致性。
- 支持外键:InnoDB 支持外键约束,可以更好地保证数据的完整性。
- 存储结构:InnoDB 表的数据和索引都存储在一个
.ibd文件中。 - 数据缓存:InnoDB 有缓冲池(Buffer Pool)来缓存索引和数据,能有效提高数据的读写性能。
- 自适应哈希索引:InnoDB 可以根据查询频率生成哈希索引,提高频繁访问数据的查询效率。
优缺点
- 优点:
- 支持事务、外键,保证数据完整性。
- 并发性能优越,适合高并发、读写混合场景。
- 支持崩溃恢复机制,系统异常时数据仍可恢复。
- 缺点:
- 表的空间占用较大,相比 MyISAM 存储效率稍低。
- 不支持全文索引(5.6 版本后部分支持)。
- 由于行级锁实现复杂,在写操作非常频繁的场景可能出现锁等待情况。
适用场景
- 适合读写混合或写密集型应用,以及对数据一致性和完整性要求较高的应用,例如在线交易、订单管理系统等业务系统。
事务(Transaction)是一组操作的逻辑集合,这组操作要么全部执行成功,要么全部失败回滚。事务保证了数据库数据的一致性,即在事务执行过程中,如果某个操作失败,所有已执行的操作将被撤销,数据库恢复到事务开始时的状态,防止出现数据不一致的情况。
可以使用以下 SQL 语句来更换表的存储引擎:
1 | ALTER TABLE table_name ENGINE = NewEngine; |
表数据的创建和增删改查
创建和删除
创建数据库
1 | CREATE DATABAS 数据库名 DEFAULT CHARACTER SET utf8; |
utf8和utf8md4的区别
如果你的应用需要支持丰富的用户输入,如社交平台(用户可能会输入 emoji)、国际化应用(需要处理多种语言的复杂字符)等,那么utf8mb4是更好的选择
删除数据库
1 | DROP DATABASE 数据库名; |
选择数据库
1 | USE 数据库名; |
创建表
1 | CREATE TABLE table_name (column_name column_type); |
1 | CREATE TABLE IF NOT EXISTS `0voice_tbl` |
增删改查
增:
1 | INSERT INTO table_name ( field1, field2,...fieldN ) VALUES ( value1, value2,...valueN ); |
举例:
1 | INSERT INTO `0voice_tbl` (`course`, `teacher`, `price`) VALUES ('C/C++Linux 服务器开发 |
删:
1 | DELETE FROM table_name [WHERE Clause] |
举例:
1 | DELETE FROM `0voice_tbl` WHERE id = 3; |
改
1 | UPDATE table_name SET field1=new-value1, field2=new-value2 [WHERE Clause] |
举例:
1 | UPDATE `0voice_tbl` SET `teacher` = 'Mark' WHERE id = 1; |
查
1 | SELECT field1, field2,...fieldN FROM table_name [WHERE Clause] [OFFSET M ][LIMIT N] |
举例:
1 | SELECT `course`,`teacher`,`price` FROM `0voice_tbl`; |
条件查询
1 | SELECT `course`,`teacher`,`price` FROM `0voice_tbl` WHERE id = 1; |
表数据的高级查询
准备表
这里的AUTO_INCREMENT的意思是插入表的时候会自动进行递增,默认从1开始增长,不必指定id号
1 | CREATE TABLE IF NOT EXISTS `student` |
COMMENT用于为表或者列添加注释信息
在navicat右键,有个设计表选项,可以查看COMMENT


插入数据:
1 | INSERT INTO `student` (`name`, `age`, `sex`, `score`, `address`) VALUES ('darren', 2 |
单表查询
一般查询,查看表中的所有记录 以及 所有字段(属性)
1 | SELECT * FROM student; |
只查看某些字段
1 | SELECT `name`, `age` FROM student; |
把查询出来的结果的字段名显示为其它名字
1 | SELECT `name` AS '姓名' , `age` AS '年龄' FROM student; |
例如表里面的数据原来显示的是name和age,现在就可以展示成我们重命名过的 姓名 年龄
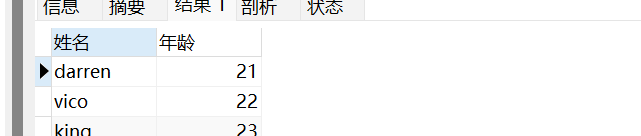
在查询结果中添加一列,这一列的值为一个常量
1 | SELECT `name`,`sex`,'广州' `address` FROM student; |
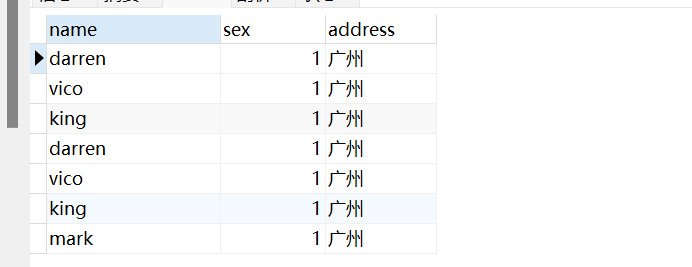
把某些字段合并后显示出来。注意,合并的字段的数据类型必须一致。
1 | SELECT `name`,(`age`+`score`) AS '年龄加得分' FROM student; |
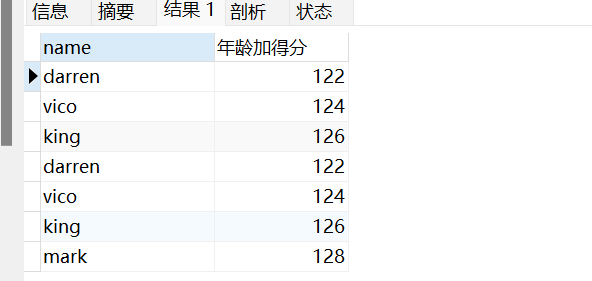
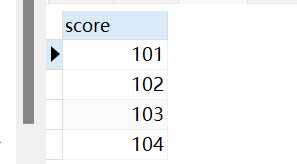
把查询出来的结果的重复记录去掉
1 | SELECT distinct `score` FROM student; |
条件查询
查询姓名为 vico 的学生信息
1 | SELECT * FROM `student` WHERE `name` = 'vico'; |
查询性别为 1,并且年龄为 22 岁的学生信息
1 | SELECT * FROM `student` WHERE `sex`=1 AND `age`=22; |
条件连接用 AND
查询年龄在 22 到 23 岁的学生的信息
1 | SELECT * FROM `student` WHERE age BETWEEN 22 AND 23; |
判空查询
判空主要有两个:
1.判断是否为 null
1 | SELECT * FROM `student` WHERE `score` IS NOT NULL; #判断不为空 |
2.判断是否为空字符串
1 | SELECT * FROM `student` WHERE sex <> ''; #判断不为空字符串 |
模糊查询
使用 like 关键字,”%”代表任意数量的字符,”_”代表占位符。
查询名字为 k 开头的学生的信息:
1 | SELECT * FROM `student` WHERE `name` LIKE 'k%'; |
查询姓名里第二个字母为 i 的学生的信息
1 | SELECT * FROM `student` WHERE `name` LIKE '_i%'; |
分页查询
分页查询主要用于查看第 N 条 到 第 M 条的信息,通常和排序查询一起使用。
使用 limit 关键字,第一个参数表示从条记录开始显示,第二个参数表示要显示的数目。 表中默认第一条记录的参数为 0。 查询学生表中第二到第三条的信息:
1 | SELECT * FROM `student` LIMIT 1,2; |
查询后排序
关键字:order by , asc:升序, desc:降序
例如按照年龄升序
1 | SELECT * FROM `student` ORDER BY `age` asc; |
还可以进行多个条件排序
例如先按照年龄排序,在此结果上再按成绩排序
1 | SELECT * FROM `student` ORDER BY `age` asc, `Score` asc; |
聚合查询
聚合函数对一组数据执行计算,集中生成汇总值。
如果需要对查询出来的结果进行求和,求平均值,求最大最小值,统计显示的数目等运算,就要用到聚合查询。
| 聚合函数 | 描述 |
|---|---|
| sum() | 计算某列的总和 |
| avg() | 计算某列的平均值 |
| max() | 计算某列的最大值 |
| min() | 计算某列的最小值 |
| count() | 它会计算每个分组中的行数 |
计算Student这个表里面的 id 号相加最终的得数
1 | select sum(id) as id_sum from `student`; |

分组查询
可以把查询出来的结果根据某个条件来分组显示
关键字:group by
例如根据性别把学生分组
1 | SELECT * FROM `student` GROUP BY `sex`; |
再举个例子,如下表,想要根据price进行分组,然后在此基础上,再去掉重复的price值
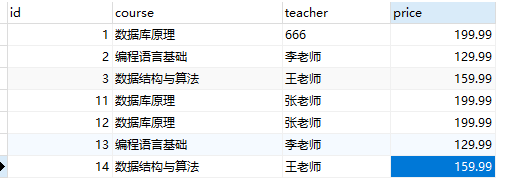
1 | -- 创建临时表存储第一个查询结果 |
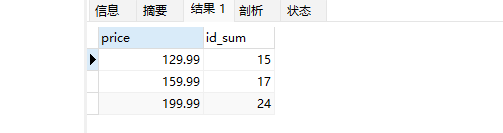
分组筛选查询
查询哪些地区的人数大于等于 1 个
1 | INSERT INTO `student` (`name`, `age`, `sex`, `score`, `address`) VALUES ('darren', 2 |
sql语句这样写:
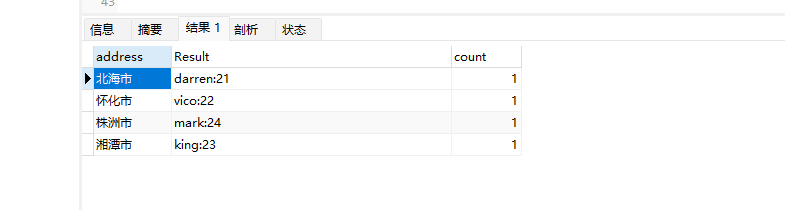
1 | SELECT `address`,count(*) from student group by `address` having count(*)>=1 |
GROUP BY 和 GROUP_CONCAT 可以结合使用来将同一分组中的多个值聚合成一个字符串。
GROUP_CONCAT(name):将同一 address 下的所有 name 值合并成一个字符串,默认以逗号分隔。
1 | select `address`,GROUP_CONCAT(`name`,':',`age`)AS Result ,count(*) from `student` GROUP BY `address`; |
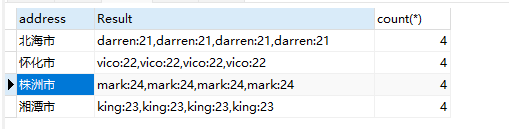
去重的话,可以这样写:
1 | SELECT |
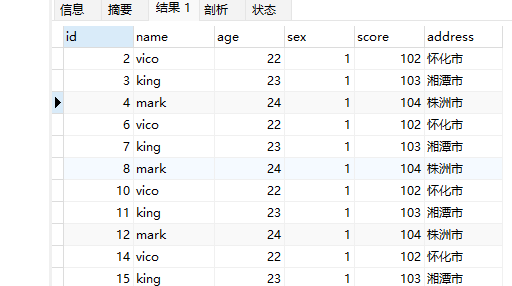
联合查询
联合查询可以让我们从多个表中提取数据,并将它们合并为一个结果集,这在处理关系数据库时非常有用,因为数据通常被分散存储在不同的表中。
例如查找满足age >=22和score>=102这俩条件的其中之一的数据
1 | select * from student where `age` >=22 |
结果如下
连表查询
在 SQL 中,多表查询是一种将两个或多个表的数据组合在一起的方式。
不同的连接类型决定了返回的结果集中会包含哪些数据。下面详细介绍多表查询中常见的四种连接方式:内连接(INNER JOIN)、左连接(LEFT JOIN)、右连接(RIGHT JOIN)和全连接(FULL JOIN)。
内连接(INNER JOIN)
定义:内连接返回的是两个表中符合连接条件的匹配记录。如果某行在其中一个表中没有匹配项,那么该行不会出现在结果集中。
1 | SELECT 表1.列名, 表2.列名, ... |
例如:
假设有两个表 students 和 courses:
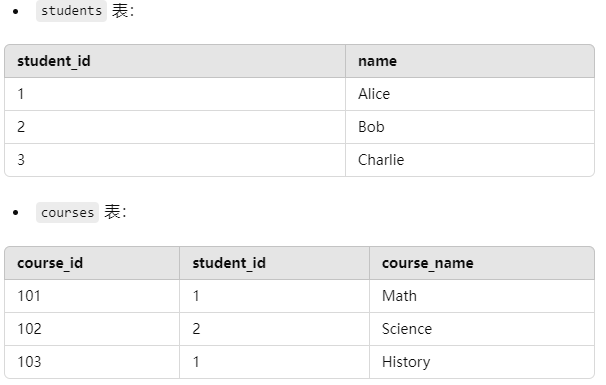
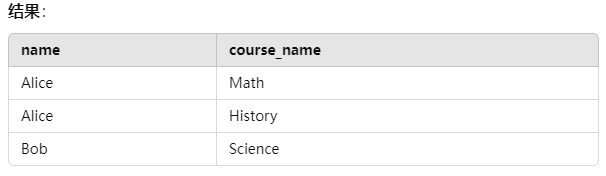
查询示例:查询每个学生及其所选课程(只有两表中都有数据的学生会显示)
1 | SELECT students.name, courses.course_name |
结果如下
左连接(LEFT JOIN)
左连接返回左表中所有的记录,即使在右表中没有匹配项,结果中也会包含这些记录(右表的字段将为 NULL)。
1 | SELECT 表1.列名, 表2.列名, ... |
示例:假设仍然使用 students 和 courses 表。
查询示例:查询每个学生及其课程(包括没有选课的学生)
1 | SELECT students.name, courses.course_name |
结果如下:
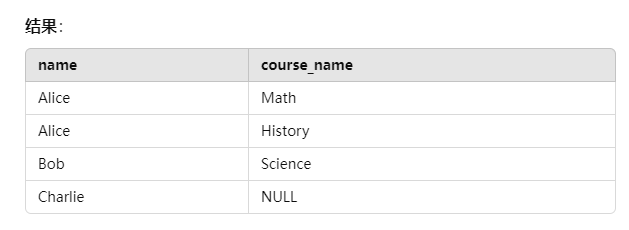
Charlie 没有课程,但由于是左连接,仍然会包含在结果中,course_name 显示为 NULL。
右连接(RIGHT JOIN)
定义:右连接返回右表中所有记录,即使在左表中没有匹配项,结果中也会包含这些记录(左表的字段将为 NULL)。
1 | SELECT 表1.列名, 表2.列名, ... |
示例:假设仍然使用 students 和 courses 表。
查询示例:查询每个学生及其课程(包括没有匹配学生的课程)。
1 | SELECT students.name, courses.course_name |
结果如下
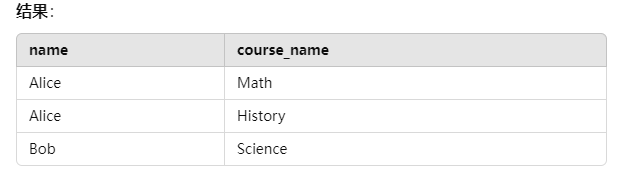
右连接在这种情况下与内连接结果一致,因为 courses 表中的 student_id 都在 students 表中有匹配项。
全连接(FULL JOIN)
类似于 UNION
可以这样写:
1 | SELECT * FROM `employee` LEFT JOIN `dept` ON `employee`.dept_id = `dept`.id |
子查询/合并查询
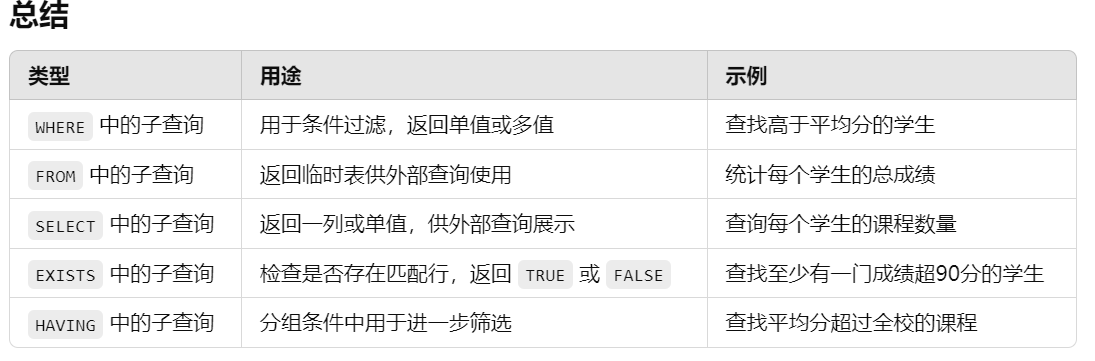
子查询
在 MySQL 中,子查询是一个嵌套在其他 SQL 语句(如 SELECT、INSERT、UPDATE 或 DELETE)中的查询。子查询会先执行,并将其结果提供给外部查询进行使用。子查询可以出现在 WHERE、FROM、HAVING 或 SELECT 语句中。
使用的例子:
1 | use mydatabase; |
1.在 WHERE 条件中使用的子查询
这种子查询返回满足特定条件的行,用于筛选结果集。通常返回单一值或一组值。
示例:查找分数高于班级平均分的学生。
1 | #示例:查找分数高于班级平均分的学生。 |
解释:这里的子查询 (SELECT AVG(score) FROM students) 计算学生的平均分,外层查询会筛选出所有高于该平均分的学生。
2.在 FROM 子句中使用的子查询
这种子查询返回一个临时表,外层查询会使用这个临时表进行查询。常用于数据汇总、统计等情况。
示例:查询每个学生的总课程成绩,并且按成绩排序。
假设我们有 scores 表结构如下:
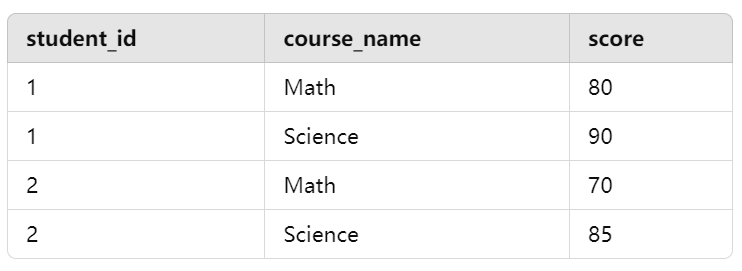
1 | SELECT |
解释:内层子查询 SELECT student_id, SUM(score) AS total_score FROM scores GROUP BY student_id 计算每个学生的总成绩,并将其作为一个临时表 student_scores 传给外层查询。
3.在 SELECT 子句中使用的子查询
这种子查询会返回一个值或一列,通常在外部查询的 SELECT 列表中使用来获取一些额外的数据。
示例:显示每个学生的姓名和该学生参加的课程数量。
1 | SELECT name, |
解释:这里的子查询 (SELECT COUNT(*) FROM scores WHERE scores.student_id = students.student_id) 计算每个学生参加的课程数量,并将结果作为外层查询的列值 course_count。
4.在 EXISTS 子句中使用的子查询
这种子查询通常用于判断子查询是否返回至少一行结果。返回 TRUE 或 FALSE。
示例:查找至少有一门课程成绩超过 90 分的学生。
1 | SELECT |
解释:EXISTS 子查询 (SELECT * FROM scores WHERE scores.student_id = students.student_id AND score > 90) 用于检查该学生是否有成绩超过 90 分的课程。如果存在则返回该学生信息。
补充下ANY,类似EXITS
1 | SELECT |
5.在 HAVING 子句中使用的子查询
这种子查询通常用于分组筛选条件中,用来进行更精确的筛选。
示例:查询课程平均分超过全校课程平均分的课程名称。
1 | SELECT |
解释:内层子查询 (SELECT AVG(score) FROM scores) 计算全校课程的平均分,HAVING 子句中筛选出那些平均分高于全校平均的课程。
合并查询
在实际应用中,为了合并多个 select 的执行结果,可以使用集合操作符 union,union all。
union
该操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行。
例如:将工资大于 1200 或职位是 MANAGER 的人找出来
1 | SELECT `name`,`salary`,`level` FROM `employee` WHERE salary > 1200 UNION |
union all
该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行。
例如:将工资大于 1200 或职位是 MANAGER 的人找出来
1 | SELECT `name`,`salary`,`level` FROM `employee` WHERE salary > 1200 UNION ALL |
正则表达式查询
正则表达式
| 选项 | 说明 | 例如 | 匹配值示例 |
|---|---|---|---|
| ^ | 文本开始字符 | ‘^b’匹配以字母b开头的字符串 | book, big, banana, bike |
| $ | 文本结束字符 | ‘st$’匹配以 st 结尾的字符串 | test, resist, persist |
| . | 任何单个字符 | ‘b.t’匹配任何 b 和 t 之间有一个字符 | bit, bat, but, bite |
| * | 0个或多个在它前面的字符 | f*n’匹配字符 n 前面有任意 n 个字符 | fn, fan, faan |
| + | 前面的字符一次或多次 | ba+’匹配以 b 开头后面紧跟至少一个 a | ba, bay, bare, battle |
| <字符串> | 包含指定字符串文本 | ‘fa’ | fan, afa, faad |
| [字符集合] | 字符集合中的任何一个字符 | ‘[xz]’匹配 x 或者 z | dizzy, zebra, x-ray, extra |
| [^] | 不在括号中的任何字符 | [^abc]’匹配任何不包含 a、b 或 c 的字符串 | desk, fox, f8ke |
| 字符串{n} | 前面的字符串至少n次 | b{2}匹配 2 个或更多的 b | bbb, bbbb, bbbbbb |
| 字符串{n,m} | 前面的字符串至少n次,至多m次 | b{2,4}匹配最少 2 个,最多4个b | bb, bbb, bbbb |
例题训练:
从 employee 表 name 字段中查询以 k 开头的记录
1 | SELECT * FROM `employee` WHERE `name` REGEXP '^k'; |
从 employee 表 name 字段中查询以 aaa 开头的记录
1 | SELECT * FROM `employee` WHERE `name` REGEXP '^aaa'; |
从 employee 表 name 字段中查询以 c 结尾的记录
1 | SELECT * FROM `employee` WHERE `name` REGEXP 'c$'; |
从 employee 表 name 字段中查询以 aaa 结尾的记录
1 | SELECT * FROM `employee` WHERE `name` REGEXP `aaa$` |
从 employee 表 name 字段中查询以 L 开头 y 结尾中间有两个任意字符的记录
1 | SELECT * FROM `employee` WHERE `name` REGEXP '^L..y$'; |
从 employee 表 name 字段中查询包含 c、e、o 三个字母中任意一个的记录
1 | SELECT * FROM `employee` WHERE `name` REGEXP '[ceo]'; |
从 employee 表 name 字段中查询包含数字的记录
1 | SELECT * FROM `employee` WHERE `name` REGEXP '[0-9]'; |
如果是要包含‘0’,‘-’,‘9’这三个字符,那么-号要进行转义
要这样写:
1 | SELECT * FROM `employee` WHERE `name` REGEXP '[0/-9]'; |
从 employee 表 name 字段中查询包含数字或 a、b、c 三个字母中任意一个的记录
1 | SELECT * FROM `employee` WHERE `name` REGEXP '[0-9a-c]' |
从 employee 表 name 字段中查询包含 a-w 字母和数字以外字符的记录
1 | SELECT * FROM `employee` WHERE `name` REGEXP '[^a-w]' |
从 employee 表 name 字段中查询包含’ic’的记录
1 | SELECT * FROM `employee` WHERE `name` REGEXP 'ic'; |
从 employee 表 name 字段中查询包含 ic、uc、ab 三个字符串中任意一个的记录
1 | SELECT * FROM `employee` WHERE `name` REGEXP 'ic|uc|ab'; |
* 代表多个该字符前的字符,包括 0 个或 1 个
从 employee 表 name 字段中查询 c 之前出现过 a 的记录
1 | SELECT * FROM `employee` WHERE `name` REGEXP 'a*c'; |
+ 代表多个该字符前的字符,包括 1 个
从 employee 表 name 字段中查询 c 之前出现过 a 的记录
1 | SELECT * FROM `employee` WHERE `name` REGEXP 'a+c';(注意比较结果!) |
字符串{N} 字符串出现 N 次
从 employee 表 name 字段中查询出现过 a 3 次的记录
1 | SELECT * FROM `employee` WHERE `name` REGEXP 'a{3}'; |
字符串{M,N}字符串最少出现 M 次,最多出现 N 次
例 1: 从 employee 表 name 字段中查询 ab 出现最少 1 次最多 3 次的记录
1 | SELECT * FROM `employee` WHERE `name` REGEXP 'ab{1,3}'; |
流程控制语句
IF,CASE,LEAVE,WHILE,LOOP,REPEAT,ITERATE
使用示例:
1 | CREATE PROCEDURE example_if(IN x INT) |
CREATE PROCEDURE CheckAge(IN age INT) 创建一个名为 CheckAge 的存储过程。
存储过程(Stored Procedure)是一段预先编译并存储在数据库中的 SQL 语句集合,可以被多次调用执行。它类似于程序中的函数
IN age INT 是一个输入参数声明 :
IN 参数:表示传入参数,值由调用者提供,存储过程内只能读取,不能修改。 OUT 参数:表示传出参数,存储过程执行后返回结果给调用者。INOUT 参数:表示既可以传入,又可以修改并返回给调用者。
age参数的名称,表示调用者传入的值在存储过程内使用的变量名称。
INT参数的数据类型,表示该参数必须是一个整数。
CASE语法
1 | CASE value |
示例代码:
1 | use mydatabase; |
WHILE语句
语法:
1 | WHILE condition DO |
示例 使用 WHILE 循环语句执行求前 100 的和
1 | -- 创建存储过程 |
LEAVE语句
LEAVE 语句退出循环或程序块,只能和 BEGIN … END,LOOP,WHILE 语句配合使用。
语法:
1 | LEAVE label |
label 是语句中标注的名字,这个名字是自定义的。
使用 WHILE 循环语句执行求前 50 的和。
1 | -- 创建存储过程 |
注意label要写在循环的开始,这样leave才知道要退出哪里
LOOP 语句
语法:
1 | LOOP |
LOOP 语句允许某特定语句或语句群的重复执行,实现一个简单的循环构造,在循环内的语句一直重复直至循环被退出,退出循环应用 LEAVE 语句
示例代码:
使用 LOOP 循环语句求前 100 的和。
1 | -- 创建存储过程 |
REPEAT 语句
REPEAT 循环语句先执行一次循环体,之后判断 condition 条件是否为真。 如果为真,则继续执行循环,否则退出循环。
语法:
1 | REPEAT |
使用 REPEAT 循环语句求前 100 的和。
注意REPEAT 本身就有 UNTIL 条件来决定循环终止,无需使用 LEAVE。
LEAVE 通常用于 LOOP 或 WHILE 结构中,但在 REPEAT 中并不常用。
1 | -- 创建存储过程 |
在 MySQL 的 REPEAT ... UNTIL ... END REPEAT 结构中,**UNTIL 不需要分号** 是因为它是 REPEAT 语句的一部分,不是一个独立的 SQL 语句。
ITERATE 语句
ITERATE 语句可以出现在 LOOP、REPEAT 和 WHILE 语句内,其意为“再次循环”。类似C中的continue
语法:
1 | ITERATE label |
该语句的格式与 LEAVE 大同小异,区别在于:LEAVE 语句是离开一个循环,而 ITERATE 语句
是重新开始一个循环
示例代码
求 10 以内奇数值的和。
1 | -- 创建存储过程 |
注意 DECLARE 是存储过程或函数的语法
SQL语句详解
DQL 语言学习(data query language)
基础查询,条件查询,排序查询,常见函数,分组函数,分组查询,连接查询,子查询 分页查询,union 联合查询
DML 语言学习(data manipulation language)
插入语句,删除语句,修改语句
DDL 语言学习(data definition language)
库的管理
创建库 0voice_test
1 | CREATE DATABASE IF NOT EXISTS 0voice_test; |
选中数据库
1 | USE 0voice_test; |
库的修改(修改库的字符集)
当然这里也可以参考直接在CREATE的时候就设置字符集
1 | ALTER DATABASE 0voice_test CHARACTER SET gbk; |
库的删除
1 | DROP DATABASE IF EXISTS 0voice_test; |
表的管理
创建表teacher
1 | CREATE TABLE IF NOT EXISTS `teacher` ( |
DESC 是 SQL 中的 DESCRIBE 命令的缩写形式,用于显示数据库表的元数据,包括表中每个列的名称、数据类型、是否可以为 NULL 以及键信息等。当你执行 DESC teacher; 时,你实际上是在请求数据库描述 teacher 表的结构。
DESC 命令会显示以下信息:
- Field:列的名称。
- Type:列的数据类型。
- Null:列是否可以包含
NULL值(YES或NO)。 - Key:列是否是索引的一部分,以及如果是,它是主键(
PRI)、唯一键(UNI)、普通索引(MUL)还是全文索引(FULLTEXT)。 - Default:列的默认值。
- Extra:额外的信息,比如自增属性(
auto_increment)
修改表:
修改列名,修改列的类型或约束,添加新列,删除列,修改表名
1 | ALTER TABLE `teacher` |
注意看,分号才是一句话的结束,这里的意思是修改表的列属性,例如上面的意思是修改publish_data这个列的名字为publishdate,将列的数据类型更改为DATETIME,并且允许该列的值为NULL。 注意,都没有逗号
而且,改约束的时候,必须按照顺序写,起码TYPE和NULL得有
修改列的类型或约束
1 | ALTER TABLE `teacher` |
添加新列
1 | ALTER TABLE `teacher` |
删除列
1 | ALTER TABLE `teacher` |
修改表名
1 | ALTER TABLE `teacher` RENAME TO `0voice_teacher`; |
删除表
1 | DROP TABLE IF EXISTS `0voice_teacher`; |
表的复制
1 | DROP TABLE IF EXISTS `teacher`; |
常见约束
创建表
1 | CREATE TABLE IF NOT EXISTS `course` ( |
主键约束:primary key
表中用来唯一标识每条记录的字段或字段组合。一个表只能有一个主键,它不仅保证了记录的唯一性,还经常用来作为连接其他表的外键。
1 | #删除主键约束: |
唯一性约束:unique key
1 | ALTER TABLE `course` |
外键约束:foreign key
用于约束处于关系内的实体
增加子表记录时,是否有与之对应的父表记录
如果主表没有相关的记录,从表不能插入
1 | DROP TABLE IF EXISTS `class`; |
如果我们认定班级表是主表,就是会在明明班级表没有这个班级的情况下,学生表填入了一个不存在的班级,例如以上代码,这时候我们就要绑定外键约束
1 | #添加外键约束 |
1 | DROP TABLE IF EXISTS `class`; |
添加完约束后,原来的代码就会爆错

非空约束
1 | 添加非空约束 |
MODIFY和Change是相像的,CHANGE貌似要按照顺序都写出来
1 | ALTER TABLE `student` CHANGE COLUMN `name` `name` VARCHAR(128) NOT NULL DEFAULT '张三丰'; |
默认值约束:default
1 | #添加默认约束 |
权限管理
创建账号
1 | CREATE USER username@host IDENTIFIED BY password; |
说明:
username:你将创建的用户名
host:指定该用户在哪个主机上可以登陆,如果是本地用户可localhost,如果想让该用户可以从任意远程主机登陆,可以使用通配符%
password:该用户的登陆密码,密码可以为空,如果为空则该用户可以不需要密码登陆服务器
示例
1 | CREATE USER 'milo'@'%' IDENTIFIED BY '1Milo_123$%^'; |
账号授权
GRANT 语句:允许对象的创建者给某用户或某组或所有用户(PUBLIC)某些特定的权限。
语句:
1 | GRANT privileges ON databasename.tablename TO 'username'@'host' WITH GRANT OPTION; |
说明:
privileges:用户的操作权限,如 SELECT,INSERT,UPDATE 等,如果要授予所的权限则使用 ALL
databasename:数据库名
tablename:表名,如果要授予该用户对所有数据库和表的相应操作权限则可用 * 表示 ,如 * . *
授权:
1 | GRANT ALL PRIVILEGES ON *.* TO 'milo'@'%'; |
刷新
1 | FLUSH PRIVILEGES; |
查询、插入、更新、删除 数据库中所有表数据的权利
1 | GRANT SELECT ON 0voice_db.* TO 'milo'@'%'; |
或者,用一条 MySQL 命令来替代:
1 | GRANT SELECT, INSERT, UPDATE, DELETE ON 0voice_db.* TO 'milo'@'%'; |
查看用户权限
1 | show grants #查自己 |
撤销授权
REVOKE 语句:可以废除某用户或某组或所有用户访问权限
1 | REVOKE 权限 ON 数据库.数据表 FROM 用户@IP |
示例:
1 | REVOKE INSERT ON *.* FROM 'milo'@'%'; |
注意事项:
grant, revoke 用户权限后,该用户只有重新连接 MySQL 数据库,权限才能生效。
如果想让授权的用户,也可以将这些权限 MySQL grant 给其他用户,需要选项
1
GRANT select on 0voice_db.* to dba@localhost with grant option;
事务
事务的含义
事务:一条或多条 sql 语句组成一个执行单位,一组 sql 语句要么都执行要么都不执行。
事务的特点
原子性: 一个事务是不可再分割的整体,要么都执行要么都不执行
一致性: 一致性是要保证操作前和操作后数据或者数据结构的一致性,一致性关注数据 的可见性,中间状态的数据对外部不可见,只有最初状态和最终状态的数据对 外可见
隔离性: 一个事务不受其他事务的干扰,多个事务互相隔离的
持久性: 一个事务一旦提交了,则永久的持久化到本地
mysql 默认情况下开启事物,每一条语句单独是一个事物。并且自动提交
1 | SHOW VARIABLES LIKE 'autocommit'; |
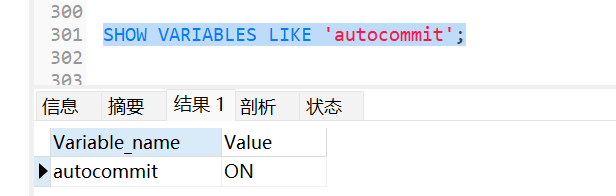
ON就是自动提交,OFF就是手动提交
自动提交设置
SET autocommit=0 禁止自动提交
SET autocommit=1 开启自动提交
当你在 MySQL 中执行 SET autocommit=0; 来禁止自动提交时,这意味着你关闭了自动提交功能。在这种模式下,所有的更改(如 INSERT、UPDATE、DELETE 等)都不会立即自动提交到数据库。这些更改会保持在当前的事务中,直到你显式地执行 COMMIT 语句来提交事务,或者执行 ROLLBACK 语句来撤销事务。
虽然你用SELECT查看可能改变了,但是在服务器上,其实并没有变
如果开启了自动提交,但是还是想用事务就要显式地使用事务
使用 START TRANSACTION 或 BEGIN 关键字:
1 | START TRANSACTION; |
这会告诉MySQL,接下来的一系列语句应该被视为一个单独的事务,直到你提交或回滚这个事务
提交或回滚事务:
如果所有语句都成功执行,你可以使用 COMMIT 关键字来提交事务,使更改永久生效
1 | COMMIT; |
如果在事务中的任何点出现了错误,或者你决定不继续执行事务,你可以使用 ROLLBACK 关键字来撤销事务中的所有更改:
1 | ROLLBACK; |
如果在事务中的任何点出现了错误,或者你决定不继续执行事务,你可以使用 ROLLBACK 关键字来撤销事务中的所有更改:
在MySQL中,当你使用BEGIN或START TRANSACTION显式地开启一个事务后,你执行的UPDATE语句会立即对数据库中的数据进行修改,但这些修改并不是永久性的,它们被放在一个事务中。这意味着,直到你执行COMMIT语句之前,这些修改对其他事务和数据库用户来说是不可见的。这是事务的隔离性所保证的。
索引
在Mysql,索引是用来提高查询速度的
在 MySQL 中,主键索引、唯一索引和普通索引的底层机制通常是通过 B+树 或其他高效的数据结构(如哈希表)来实现的。
举个例子
创建一个没有索引的数据库:
1 | CREATE TABLE employees_no_index ( |
此时对数据库进行查询:
1 | SELECT * FROM employees WHERE age = 30; |
数据库会对 employees 表逐行扫描(全表扫描),检查每一行的 age 值是否为 30。
如果有上百万条记录,这个过程会非常慢。
但是如果创建的是带索引的数据库,例如这样:
1 | CREATE TABLE employees ( |
id INT PRIMARY KEY AUTO_INCREMENT 自动创建了一个主键索引
数据库就可以直接通过主键这个索引,直接定位到age=30的记录所在位置
索引类似于有序的树状结构,查找速度为 O(log n),比全表扫描的 O(n) 快得多。
MySQL 索引常用有:普通索引、主键索引、唯一索引、全文索引和组合索引。
索引字段说明
如果我们去执行show index from table
就会显示出如下字段:

以下是对各个字段的介绍
- Table
表名,表示索引属于哪个表。在本例中为order。 - Non_unique
是否是唯一索引:0表示唯一索引(如PRIMARY KEY和UNIQUE索引)。1表示普通索引(非唯一)。
- Key_name
索引的名称:PRIMARY表示主键索引。- 自定义的唯一或普通索引的名称会根据创建时的定义显示。
- Seq_in_index
列在索引中的顺序:- 1 表示索引的第一列。
- 2 表示索引的第二列(如复合索引的列)。
- Column_name
列名,表示索引基于哪些列。 - Collation
索引中列的排序规则:A表示升序(Ascending)。- 如果排序规则不可用,则可能显示
NULL。
- Cardinality
索引的基数,表示索引中不同值的估计数量,用于查询优化。- 数值越大,索引区分度越高。
- 基数是估算值,通常通过
ANALYZE TABLE更新。
- Sub_part
如果索引仅部分列(如前 N 个字符)被索引,则显示被索引的字符数。否则为NULL。 - Packed
是否使用了压缩存储索引,通常为NULL。 - Null
列是否允许NULL值:YES表示可以为NULL。- 空白表示不允许
NULL。
- Index_type
索引的类型,例如:BTREE: 默认索引类型,用于大多数情况。FULLTEXT: 用于全文索引。HASH: 用于哈希索引。
- Comment
索引的额外信息,通常为空。 - Index_comment
索引创建时指定的注释(如果有)。
所以说数据库不仅包含用户存储的 表中数据(即你直接插入和查询的记录),还包含许多 额外的信息和结构 来支持数据库的高效运行和管理。
包含了以下
元数据(描述表和其他对象的定义)。
索引信息(加速查询的额外数据)。
统计信息(帮助优化查询)。
系统表(数据库的自描述结构)。
日志和事务信息(用于维护数据完整性和恢复能力)。
索引类型
普通索引
基本的索引类型,值可以为空,没有唯一性的限制。
直接创建索引
1 | #语法 |
添加索引
1 | 语法 |
删除索引
1 | #语法 |
主键索引
主键是一种唯一性索引,但它必须指定为 PRIMARY KEY,每个表只能有一个主键。
创建表时添加主键
1 | CREATE TABLE `user`( |
通过修改表的方式删除主键
1 | #语法 |
通过修改表的方式加入主键
1 | #语法 |
唯一索引
索引列的所有值都只能出现一次,即必须唯一,值可以为空。
创建唯一索引
1 | #语法 |
修改表结构添加
1 | #语法 |
全文索引
全文索引是一种特殊的数据库索引,用于加速对 大段文本数据 的搜索。它的特点是能够对 自然语言文本 进行高效查询,支持模糊匹配、相关性排序等功能。全文索引不只看字符串的完整匹配,而是从单词、短语的角度分析文本的内容。
常用于以下场景:
搜索引擎:比如查询一篇文章是否包含某些关键词。
博客或内容管理系统:用户可以搜索某篇文章的标题、正文或标签。
电子商务:用户按描述或评论中的关键词搜索商品。
文档检索:比如寻找包含某特定术语的法律或技术文档。
问答系统:匹配用户提问与数据库中的最佳答案。
全文索引 vs 普通索引
- 普通索引:通常用于精确匹配或简单的范围查询。例如:按
ID查找用户。 - 全文索引:主要用于处理 模糊匹配 和 自然语言搜索,效率更高。例如:查找包含某些关键词的文章。
代码示例:
创建:
1 | CREATE TABLE articles ( |
在已有表中添加全文索引:
1 | ALTER TABLE articles ADD FULLTEXT(title, content); |
查询全文索引
MySQL 提供了 MATCH ... AGAINST 语法用于全文搜索:
1 | SELECT * FROM articles |
还有高级查询,具体去GTP查
组合索引
组合索引(Composite Index,也称复合索引)是 在一个表的多个列上创建的索引。 与单列索引不同,组合索引可以通过同时对多个列的组合进行索引,从而加速涉及这些列的查询。
使用例子:
1 | CREATE TABLE orders ( |
索引名为 idx_customer_date,包含两列:customer_id 和 order_date。
然后就可以查询了
1 | SELECT * FROM orders |
MySQL 使用组合索引加速查询:先查 customer_id,再用 order_date 精确定位。
视图
视图(view)是一种虚拟存在的表,是一个逻辑表,本身并不包含数据。其内容由查询定义。
通过视图,可以展现基表的部分数据;
优点
简单:使用视图的用户完全不需要关心后面对应的表的结构、关联条件和筛选条件,对用户来说已经是过滤好的复合条件的结果集。
安全:使用视图的用户只能访问他们被允许查询的结果集,对表的权限管理并不能限制到某个行某个列,但是通过视图就可以简单的实现。
数据独立:一旦视图的结构确定了,可以屏蔽表结构变化对用户的影响,源表增加列对视图没有影响;源表修改列名,则可以通过修改视图来解决,不会造成对访问者的影响。
代码演试:
1 | #视图 |
存储过程和存储函数
存储过程
SQL 语句需要先编译然后执行,而存储过程(Stored Procedure)是一组为了完成特定功能的 SQL 语句集,经编译后存储在数据库中,用户通过指定存储过程的名字并给定参数(如果该存储过程带有参数)来调用执行它。
1.创建一个简单的存储过程
1 | CREATE TABLE user ( |
2.创建一个存储过程,用来查询user表中年龄大于给定值的用户
1 | DELIMITER $$ |
说明:
DELIMITER $$和DELIMITER ;:用于改变SQL语句结束符(默认是;),因为存储过程内部也使用了;,所以我们将其暂时改为$$,防止出现语法冲突。CREATE PROCEDURE:用于创建存储过程,GetUsersByAge是存储过程的名称,IN min_age INT定义了输入参数,min_age表示最小年龄。SELECT:存储过程的主体部分,查询user表中所有年龄大于min_age的用户。
- 创建存储过程之后,可以通过
CALL语句调用它
1 | -- 调用存储过程,获取年龄大于20的用户 |
带有输出参数的存储过程
1 | DELIMITER $$ |
说明:
OUT user_count INT:定义一个输出参数user_count,用于存储计算结果。SELECT COUNT(*) INTO user_count:查询user表中年龄大于min_age的用户数量,并将结果存入user_count输出参数。这里的INTO代表的是写入指定变量。
这样调用
1 | -- 定义一个变量来接收用户数量 |
删除存储过程
当不再需要存储过程时,可以使用 DROP PROCEDURE 删除存储过程
1 | DROP PROCEDURE IF EXISTS GetUsersByAge; |
存储函数
存储函数是一个可以接收输入参数、执行一系列 SQL 操作并返回一个单一结果值的程序。与存储过程不同的是,存储函数必须返回一个值,而存储过程则不要求返回值。 而且存储函数不能改变表,但是存储过程可以
1 | CREATE FUNCTION function_name (parameter1 datatype, parameter2 datatype, ...) |
function_name: 函数的名称。
parameter: 输入参数,可以有多个参数,每个参数后面需要指定数据类型。
RETURNS return_datatype: 指定返回值的数据类型。
DETERMINISTIC: 表示该函数对于相同的输入值,每次返回相同的结果。DETERMINISTIC 可选,也可以使用 NON-DETERMINISTIC,表示函数的结果可能不同,通常取决于外部因素(如时间、随机数等)。选择DETERMINISTIC可以节省资源
BEGIN ... END: 存储函数的执行代码块。
使用说明
创建存储函数
1 | DELIMITER $$ |
**DELIMITER $$**:这是为了将存储函数的定义从默认的 ; 结束符中分离开来。由于存储过程或函数体内可能包含 ;,因此需要使用 $$ 或其他定界符来标识函数的结束。
**CREATE FUNCTION GetUserCountByAge(min_age INT)**:定义了一个名为 GetUserCountByAge 的函数,该函数接收一个参数 min_age,表示最小年龄。
**RETURNS INT**:该函数返回一个整数值,表示年龄大于 min_age 的用户数量。
**DECLARE user_count INT**:声明了一个局部变量 user_count,用于存储计算得到的用户数量。
**SELECT COUNT(\*) INTO user_count ...**:这部分代码执行查询,计算符合条件(年龄大于 min_age)的用户数量,并将结果存储在 user_count 变量中。
**RETURN user_count**:返回计算得到的用户数量。
调用存储函数
1 | -- 调用存储函数,传入最小年龄 30,获取年龄大于 30 的用户数量 |
触发器
简介
MySQL 的 触发器(Trigger)是一种特殊类型的存储程序,它会在执行 INSERT、UPDATE 或 DELETE 操作时自动触发,执行与数据操作相关的自定义操作。触发器通常用于执行一些额外的逻辑,如数据验证、记录审计、日志记录、自动化计算或更复杂的数据修改等。
触发器与事件和条件相关,触发的具体行为由以下几个要素决定:
- 触发时间:指触发器被执行的时机,可以是:
- BEFORE:在数据修改之前触发。
- AFTER:在数据修改之后触发。
- 触发事件:指在表上执行的 SQL 操作,可以是:
- INSERT:插入新记录时触发。
- UPDATE:更新已有记录时触发。
- DELETE:删除记录时触发。
- 作用范围:触发器作用于表或视图,在这些对象上执行的 SQL 操作会激活触发器。
触发器的基本语法:
1 | CREATE TRIGGER trigger_name |
使用示例:
1 | CREATE TABLE IF NOT EXISTS employees ( |
事件
简介
MySQL 的 事件(Event)是 MySQL 提供的一种机制,允许在指定的时间或定期自动执行某些 SQL 语句。事件类似于计划任务(Cron jobs)
事件的基本语法长这样:
1 | CREATE EVENT event_name |
**event_name**:事件的名称。
**schedule**:定义事件执行的时间或时间间隔。
**event_body**:事件执行的 SQL 语句。
代码示例
例如,创建一个事件,每天午夜清理一个日志表:
1 | CREATE EVENT cleanup_logs |
Mysql开发
Windows开发Mysql
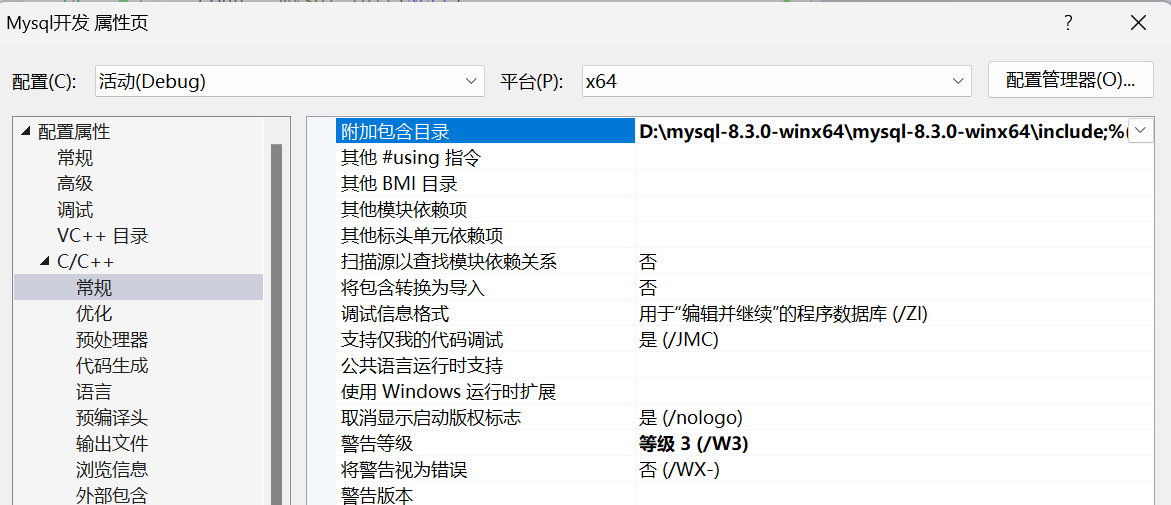
第一步:选择【C/C++】->【常规】,设置附加包含目录
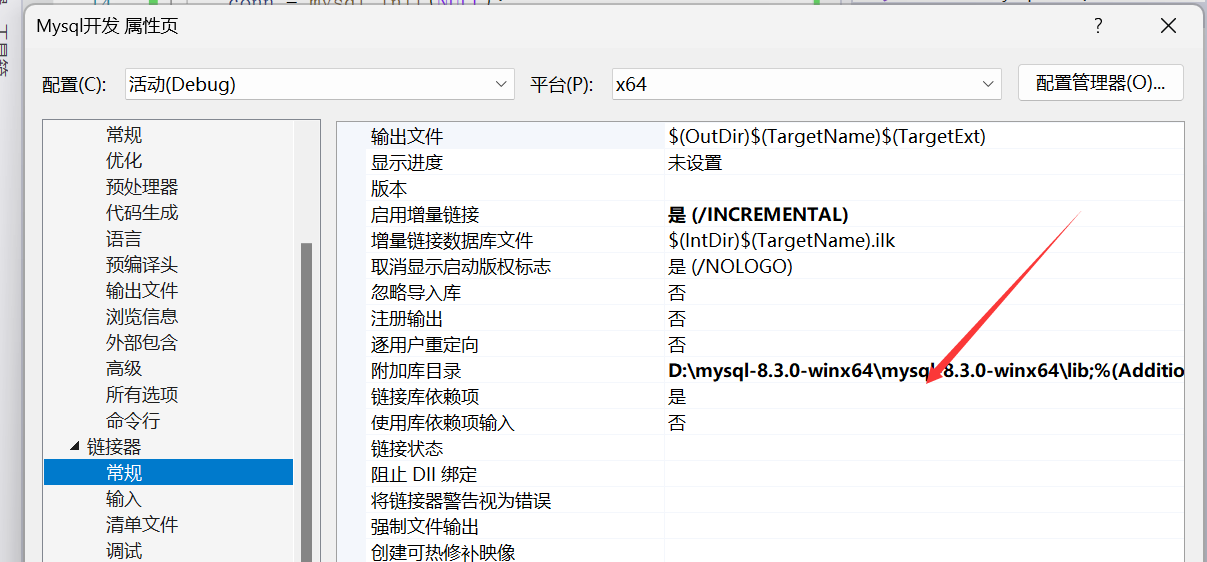
第二步:选择【链接器】->【常规】,设置附加库目录,
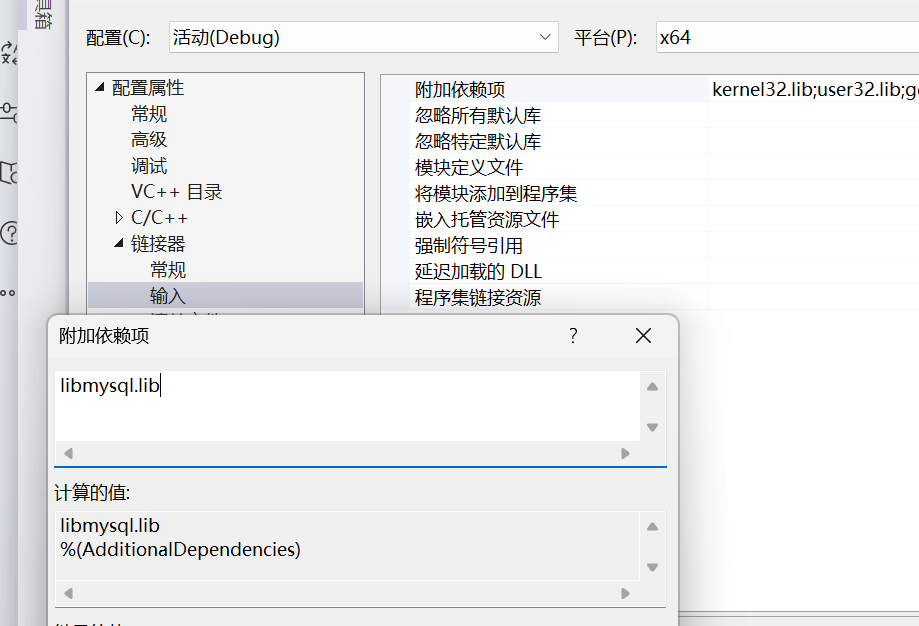
第三步:选择【链接器】->【输入】,设置附加依赖库,
增加依赖库 libmysql.lib,这个要自己拷贝到和cpp同个目录下
测试代码:
1 |
|
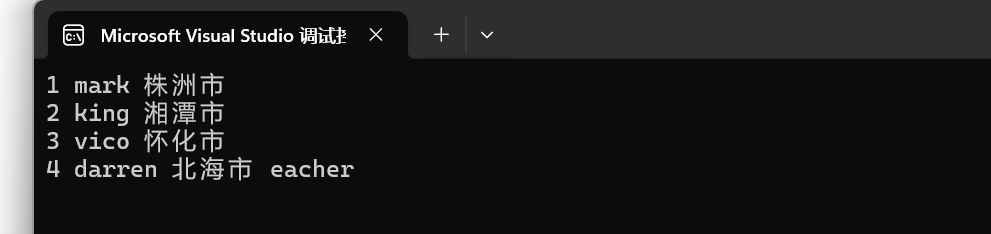
效果展示:
Linux开发Mysql
还是拿出宇宙最强Visual Studio IDE,但是最强毕竟也是跨平台,难免在一些地方显得业余,比如我的头文件VS就没有拷贝过来,靠北了真是
下面这个篇文章解决了,记得加一个库依赖项
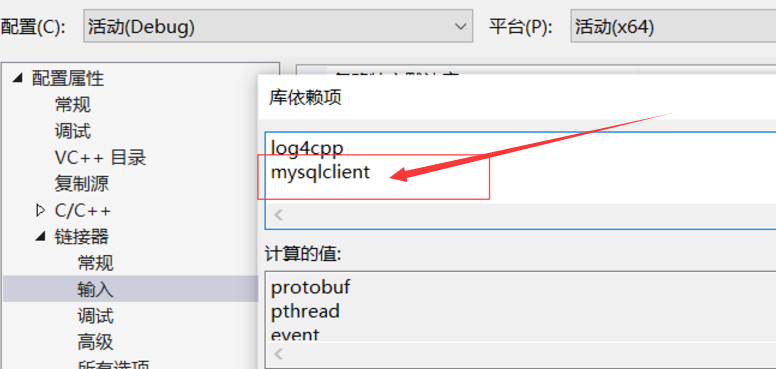
在vs2019连接linux环境下,mysql头文件报错的问题_vs209 linux程序 mysql-CSDN博客
参考代码:
1 |
|
效果:
